梯度下降(Gradient Decent)与随机梯度下降(Stochastic Gradient Decent)
主要参考资料:台大李宏毅教授的机器学习课程 B站视频
与之前我有讲过的EM算法类似,梯度下降算法同样是一个优化算法。它所要解决的问题是:
求得
θ⋆=arg minL(θ)\theta^{\star}=\argmin L(\theta)θ⋆=argminL(θ)
其中θ\thetaθ是待更新的参数,注意这可以包括多个参数,也就是说θ\thetaθ是一个向量,L(θ)L(\theta)L(θ)是loss function,也就是在优化过程中我们要不断减小的函数。
整个过程用数学来描述其实很简单,用到的其实就是在高数中的梯度的概念。假设θ=[θ1,θ2]T\theta=[\theta_1,\theta_2]^Tθ=[θ1,θ2]T,也就是表示有两个参数。那么整个参数迭代的过程如下:

其中θij\theta_i^jθij表示第iii个变量在第jjj次迭代后的值,η\etaη是在深度学习中最常见的一个超参数:learning rate学习率。
要注意的一点是要得到θt+1\theta^{t+1}θt+1,那么就一定需要∇L(θ)\nabla L(\theta)∇L(θ),也就是说,需要算出整个loss function的梯度,所
Learning Rate 学习率学习率就是梯度下降的步伐值,有一张图我觉得很经典
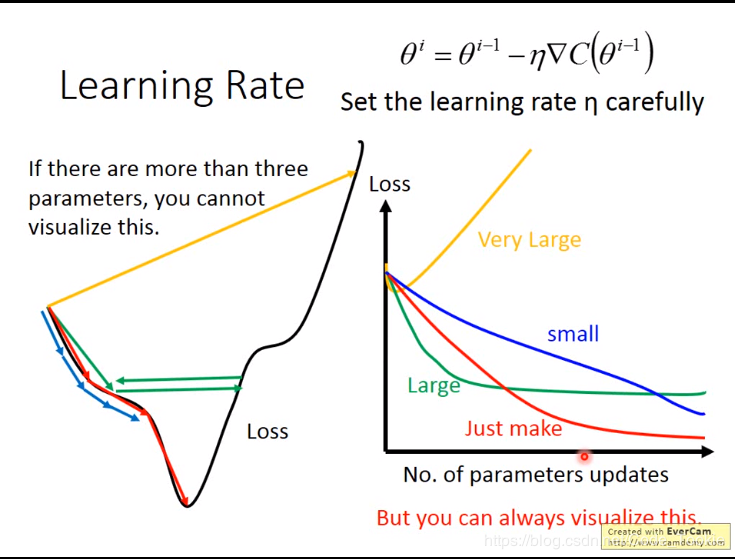
如上图所示,当学习率比较小的时候,参数会更新的很慢,这不利于网络的训练。当学习率非常大的时候,Loss会不降反增。只有恰当好处的学习率才能取得最好的效果。
很多人包括我自己初学learning rate的时候都有一个自然的想法,可以让learning rate在越靠近极值的时候越小。 这样不就可以既满足速度快且最后精度高了吗?
之前看过Andrew Ng的视频,他对此的有一个解释是:实际上这样子的操作是不太需要的,就以最普通的二次函数为例,在梯度一次次下降的过程中,即使保持学习率不变,由于越接近极值点,梯度越小,所以本身就会有逐渐越来越精确的效果。
不过有的时候我们还是需要设计一个更加有适应性的学习率调整算法。于是Adaptive Learning Rate就产生了。
AdagradAdagrad的算法流程如下:

在这里李宏毅教授讲课时提出了一个问题如下:
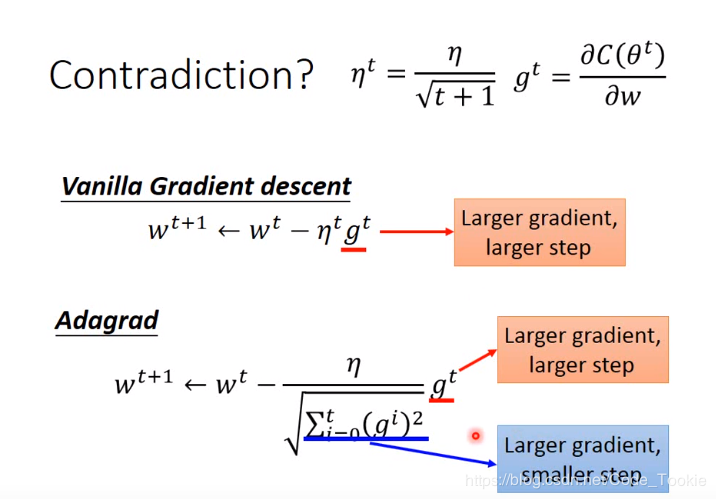
李宏毅教授对此的解释很清楚: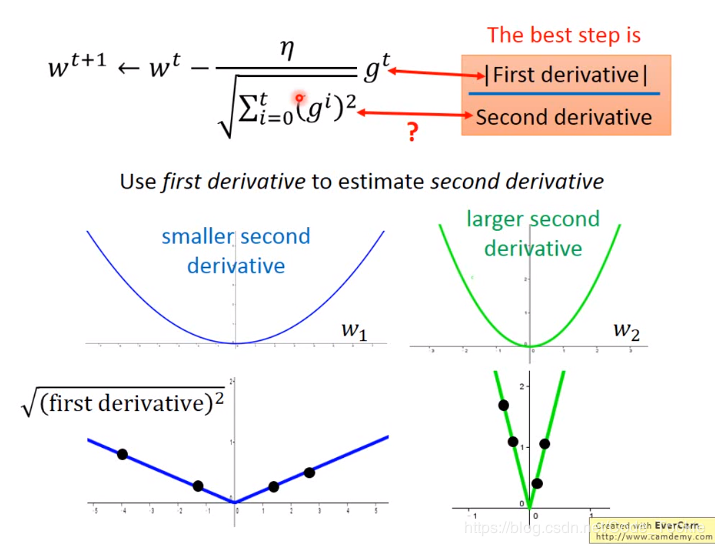
在整个过程中,分母的平方均值实际上承担的是一个采样求近似二阶导的过程。当然也可以真的求出一个二次导,但是在实际操作中上图的方法要快很多。
随机梯度下降(Stochastic Gradient Decent)在梯度下降算法中,我们算梯度时是用所有的样本来计算Loss function从而计算梯度的。这样子每次算出的梯度虽然方向非常正确,但是速度很慢。在训练网络时完全没有必要。
两种算法的主要区别如下:

此时的loss不再是全局的loss,而仅仅是随机取的这一个样本的loss。因此,速度要比普通的梯度下降要快很多。
作者:Code_Tookie