(Deep learning)深度卷积网络实战——第一部分
这周我们首先来看看一些卷积神经网络的实例分析,为什么要看这些实例分析呢?上周我们讲了基本构建,比如卷积层、池化层以及全连接层这些组件。事实上,过去几年计算机视觉研究中的大量研究都集中在如何把这些基本构件组合起来,形成有效的卷积神经网络。最直观的方式之一就是去看一些案例,就像很多人通过看别人的代码来学习编程一样,通过研究别人构建有效组件的案例是个不错的办法。实际上在计算机视觉任务中表现良好的神经网络框架往往也适用于其它任务,也许你的任务也不例外。也就是说,如果有人已经训练或者计算出擅长识别猫、狗、人的神经网络或者神经网络框架,而你的计算机视觉识别任务是构建一个自动驾驶汽车,你完全可以借鉴别人的神经网络框架来解决自己的问题。
最后,学完这几节课,你应该可以读一些计算机视觉方面的研究论文了,我希望这也是你学习本课程的收获。当然,读论文并不是必须的,但是我希望当你发现你可以读懂一些计算机视觉方面的研究论文或研讨会内容时会有一种满足感。言归正传,我们进入主题。
这是后面几节课的提纲,首先我们来看几个经典的网络。
![]() 的值,有10个可能的
的值,有10个可能的![]() 值,对应识别0-9这10个数字。在现在的版本中则使用softmax函数输出十种分类结果,而在当时,LeNet-5网络在输出层使用了另外一种,现在已经很少用到的分类器。
值,对应识别0-9这10个数字。在现在的版本中则使用softmax函数输出十种分类结果,而在当时,LeNet-5网络在输出层使用了另外一种,现在已经很少用到的分类器。
相比现代版本,这里得到的神经网络会小一些,只有约6万个参数。而现在,我们经常看到含有一千万到一亿个参数的神经网络,比这大1000倍的神经网络也不在少数。
不管怎样,如果我们从左往右看,随着网络越来越深,图像的高度和宽度在缩小,从最初的32×32缩小到28×28,再到14×14、10×10,最后只有5×5。与此同时,随着网络层次的加深,通道数量一直在增加,从1增加到6个,再到16个。
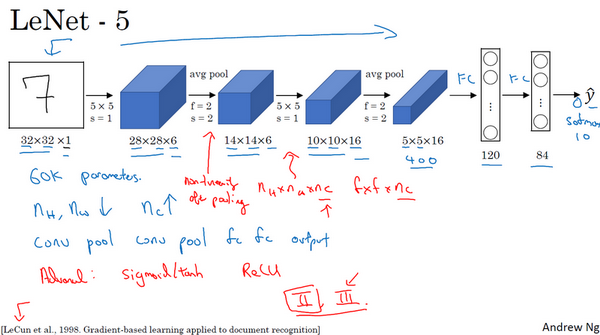
这个神经网络中还有一种模式至今仍然经常用到,就是一个或多个卷积层后面跟着一个池化层,然后又是若干个卷积层再接一个池化层,然后是全连接层,最后是输出,这种排列方式很常用。
对于那些想尝试阅读论文的同学,我再补充几点。接下来的部分主要针对那些打算阅读经典论文的同学,所以会更加深入。这些内容你完全可以跳过,算是对神经网络历史的一种回顾吧,听不懂也不要紧。
读到这篇经典论文时,你会发现,过去,人们使用sigmod函数和tanh函数,而不是ReLu函数,这篇论文中使用的正是sigmod函数和tanh函数。这种网络结构的特别之处还在于,各网络层之间是有关联的,这在今天看来显得很有趣。
比如说,你有一个![]() 的网络,有
的网络,有![]() 个通道,使用尺寸为
个通道,使用尺寸为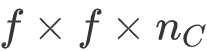 的过滤器,每个过滤器的通道数和它上一层的通道数相同。这是由于在当时,计算机的运行速度非常慢,为了减少计算量和参数,经典的LeNet-5网络使用了非常复杂的计算方式,每个过滤器都采用和输入模块一样的通道数量。论文中提到的这些复杂细节,现在一般都不用了。
的过滤器,每个过滤器的通道数和它上一层的通道数相同。这是由于在当时,计算机的运行速度非常慢,为了减少计算量和参数,经典的LeNet-5网络使用了非常复杂的计算方式,每个过滤器都采用和输入模块一样的通道数量。论文中提到的这些复杂细节,现在一般都不用了。
我认为当时所进行的最后一步其实到现在也还没有真正完成,就是经典的LeNet-5网络在池化后进行了非线性函数处理,在这个例子中,池化层之后使用了sigmod函数。如果你真的去读这篇论文,这会是最难理解的部分之一,我们会在后面的课程中讲到。
下面要讲的网络结构简单一些,幻灯片的大部分类容来自于原文的第二段和第三段,原文的后几段介绍了另外一种思路。文中提到的这种图形变形网络如今并没有得到广泛应用,所以在读这篇论文的时候,我建议精读第二段,这段重点介绍了这种网络结构。泛读第三段,这里面主要是一些有趣的实验结果。
我要举例说明的第二种神经网络是AlexNet,是以论文的第一作者Alex Krizhevsky的名字命名的,另外两位合著者是ilya Sutskever和Geoffery Hinton。
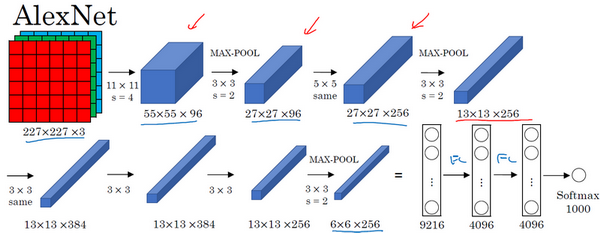
AlexNet首先用一张227×227×3的图片作为输入,实际上原文中使用的图像是224×224×3,但是如果你尝试去推导一下,你会发现227×227这个尺寸更好一些。第一层我们使用96个11×11的过滤器,步幅为4,由于步幅是4,因此尺寸缩小到55×55,缩小了4倍左右。然后用一个3×3的过滤器构建最大池化层,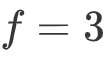 ,步幅s为2,卷积层尺寸缩小为27×27×96。接着再执行一个5×5的卷积,padding之后,输出是27×27×276。然后再次进行最大池化,尺寸缩小到13×13。再执行一次same卷积,相同的padding,得到的结果是13×13×384,384个过滤器。再做一次same卷积,就像这样。再做一次同样的操作,最后再进行一次最大池化,尺寸缩小到6×6×256。6×6×256等于9216,将其展开为9216个单元,然后是一些全连接层。最后使用softmax函数输出识别的结果,看它究竟是1000个可能的对象中的哪一个。
,步幅s为2,卷积层尺寸缩小为27×27×96。接着再执行一个5×5的卷积,padding之后,输出是27×27×276。然后再次进行最大池化,尺寸缩小到13×13。再执行一次same卷积,相同的padding,得到的结果是13×13×384,384个过滤器。再做一次same卷积,就像这样。再做一次同样的操作,最后再进行一次最大池化,尺寸缩小到6×6×256。6×6×256等于9216,将其展开为9216个单元,然后是一些全连接层。最后使用softmax函数输出识别的结果,看它究竟是1000个可能的对象中的哪一个。
实际上,这种神经网络与LeNet有很多相似之处,不过AlexNet要大得多。正如前面讲到的LeNet或LeNet-5大约有6万个参数,而AlexNet包含约6000万个参数。当用于训练图像和数据集时,AlexNet能够处理非常相似的基本构造模块,这些模块往往包含着大量的隐藏单元或数据,这一点AlexNet表现出色。AlexNet比LeNet表现更为出色的另一个原因是它使用了ReLu激活函数。
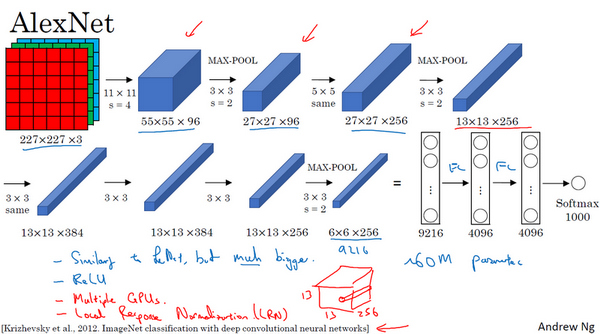
同样的,我还会讲一些比较深奥的内容,如果你并不打算阅读论文,不听也没有关系。第一点,在写这篇论文的时候,GPU的处理速度还比较慢,所以AlexNet采用了非常复杂的方法在两个GPU上进行训练。大致原理是,这些层分别拆分到两个不同的GPU上,同时还专门有一个方法用于两个GPU进行交流。


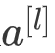 插入的时机是在线性激活之后,ReLU激活之前。除了捷径,你还会听到另一个术语“跳跃连接”,就是指
插入的时机是在线性激活之后,ReLU激活之前。除了捷径,你还会听到另一个术语“跳跃连接”,就是指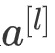 跳过一层或者好几层,从而将信息传递到神经网络的更深层。
跳过一层或者好几层,从而将信息传递到神经网络的更深层。
ResNet的发明者是何凯明(Kaiming He)、张翔宇(Xiangyu Zhang)、任少卿(Shaoqing Ren)和孙剑(Jiangxi Sun),他们发现使用残差块能够训练更深的神经网络。所以构建一个ResNet网络就是通过将很多这样的残差块堆积在一起,形成一个很深神经网络,我们来看看这个网络。

这并不是一个残差网络,而是一个普通网络(Plain network),这个术语来自ResNet论文。
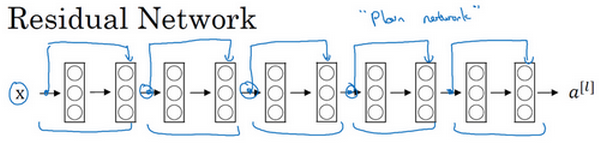
把它变成ResNet的方法是加上所有跳跃连接,正如前一张幻灯片中看到的,每两层增加一个捷径,构成一个残差块。如图所示,5个残差块连接在一起构成一个残差网络。
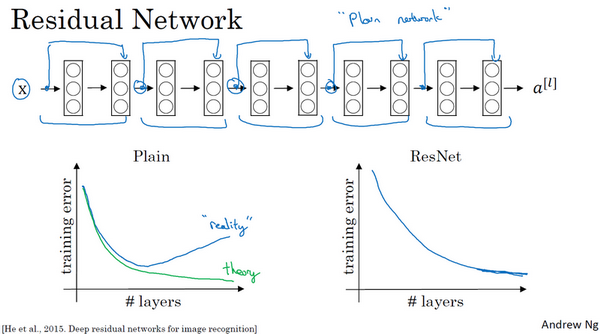
如果我们使用标准优化算法训练一个普通网络,比如说梯度下降法,或者其它热门的优化算法。如果没有残差,没有这些捷径或者跳跃连接,凭经验你会发现随着网络深度的加深,训练错误会先减少,然后增多。而理论上,随着网络深度的加深,应该训练得越来越好才对。也就是说,理论上网络深度越深越好。但实际上,如果没有残差网络,对于一个普通网络来说,深度越深意味着用优化算法越难训练。实际上,随着网络深度的加深,训练错误会越来越多。
但有了ResNets就不一样了,即使网络再深,训练的表现却不错,比如说训练误差减少,就算是训练深达100层的网络也不例外。有人甚至在1000多层的神经网络中做过实验,尽管目前我还没有看到太多实际应用。但是对x的激活,或者这些中间的激活能够到达网络的更深层。这种方式确实有助于解决梯度消失和梯度爆炸问题,让我们在训练更深网络的同时,又能保证良好的性能。也许从另外一个角度来看,随着网络越来深,网络连接会变得臃肿,但是ResNet确实在训练深度网络方面非常有效。
现在大家对ResNet已经有了一个大致的了解,通过本周的编程练习,你可以尝试亲自实现一下这些想法。至于为什么ResNets能有如此好的表现,接下来我会有更多更棒的内容分享给大家,我们下个视频见。
作者:cold星辰