前端面试题全面整理-带解析 涵盖CSS、JS、浏览器、Vue、React、移动web、前端性能、算法、Node
喜欢的小伙伴关注我哦,欢迎大家的交流学习 全选
1
2
3
var checkbox = document.getElementsByClassName('check')
var checkAll = document.getElementById('all')
var checkOther = document.getElementById('other')
checkAll.onclick = function() {
var flag = true
for (var i = 0; i < checkbox.length; i++) {
if (!checkbox[i].checked) flag = false
}
if (flag) {
for (var i = 0; i < checkbox.length; i++) {
checkbox[i].checked = false
}
} else {
for (var i = 0; i < checkbox.length; i++) {
checkbox[i].checked = true
}
}
}
checkOther.onclick = function() {
for (var i = 0; i < checkbox.length; i++) {
checkbox[i].checked = !checkbox[i].checked
}
}
16. 对原型链的理解?prototype上都有哪些属性
全选
1
2
3
var checkbox = document.getElementsByClassName('check')
var checkAll = document.getElementById('all')
var checkOther = document.getElementById('other')
checkAll.onclick = function() {
var flag = true
for (var i = 0; i < checkbox.length; i++) {
if (!checkbox[i].checked) flag = false
}
if (flag) {
for (var i = 0; i < checkbox.length; i++) {
checkbox[i].checked = false
}
} else {
for (var i = 0; i < checkbox.length; i++) {
checkbox[i].checked = true
}
}
}
checkOther.onclick = function() {
for (var i = 0; i < checkbox.length; i++) {
checkbox[i].checked = !checkbox[i].checked
}
}
16. 对原型链的理解?prototype上都有哪些属性
在js里,继承机制是原型继承。继承的起点是 对象的原型(Object prototype)。
一切皆为对象,只要是对象,就会有 proto 属性,该属性存储了指向其构造的指针。
Object prototype也是对象,其 proto 指向null。
对象分为两种:函数对象和普通对象,只有函数对象拥有『原型』对象(prototype)。
prototype的本质是普通对象。
Function prototype比较特殊,是没有prototype的函数对象。
new操作得到的对象是普通对象。
当调取一个对象的属性时,会先在本身查找,若无,就根据 proto 找到构造原型,若无,继续往上找。最后会到达顶层Object prototype,它的 proto 指向null,均无结果则返回undefined,结束。
由 proto 串起的路径就是『原型链』。
通过prototype可以给所有子类共享属性
17. 为什么使用继承通常在一般的项目里不需要,因为应用简单,但你要用纯js做一些复杂的工具或框架系统就要用到了,比如webgis、或者js框架如jquery、ext什么的,不然一个几千行代码的框架不用继承得写几万行,甚至还无法维护。
18. setTimeout时间延迟为何不准单线程, 先执行同步主线程, 再执行异步任务队列
19. 事件循环述,宏任务和微任务有什么区别?先主线程后异步任务队列
先微任务再宏任务
20. let const var作用域块级作用域, 暂时性死区
ES语法
函数节流是指一定时间内js方法只跑一次。比如人的眨眼睛,就是一定时间内眨一次。这是函数节流最形象的解释。
// 函数节流 滚动条滚动
var canRun = true;
document.getElementById("throttle").onscroll = function(){
if(!canRun){
// 判断是否已空闲,如果在执行中,则直接return
return;
}
canRun = false;
setTimeout(function(){
console.log("函数节流");
canRun = true;
}, 300);
};
函数防抖是指频繁触发的情况下,只有足够的空闲时间,才执行代码一次。比如生活中的坐公交,就是一定时间内,如果有人陆续刷卡上车,司机就不会开车。只有别人没刷卡了,司机才开车。
// 函数防抖
var timer = false;
document.getElementById("debounce").onscroll = function(){
clearTimeout(timer); // 清除未执行的代码,重置回初始化状态
timer = setTimeout(function(){
console.log("函数防抖");
}, 300);
};
22. 实现一个sleep函数
// 这种实现方式是利用一个伪死循环阻塞主线程。因为JS是单线程的。所以通过这种方式可以实现真正意义上的sleep()。
function sleep(delay) {
var start = (new Date()).getTime();
while ((new Date()).getTime() - start < delay) {
continue;
}
}
function test() {
console.log('111');
sleep(2000);
console.log('222');
}
test()
23. 闭包
点击查看闭包详情
概念: 内层函数能够访问外层函数作用域的变量
缺点: 引起内存泄漏(释放内存)
作用:
使用闭包修正打印值
实现柯里化
实现node commonJs 模块化, 实现私有变量
保持变量与函数活性, 可延迟回收和执行
Facebook出品, 倡导数据的不可变性, 用的最多就是List和Map.
25. js实现instanceof// 检测l的原型链(proto)上是否有r.prototype,若有返回true,否则false
function myInstanceof (l, r) {
var R = r.prototype
while (l.proto) {
if (l.proto === R) return true
}
return false
}
ES模块化
28. 严格模式ES严格模式
// 严格模式下, 隐式绑定丢失后this不会指向window, 而是指向undefined
'use strict'
var a = 2
var obj = {
a: 1,
b: function() {
// console.log(this.a)
console.log(this)
}
}
var c = obj.b
c() // undefined
29. fetch, axios区别
30. typescript缺点
并不是严格意义的js的超集, 与js不完全兼容, 会报错
更多的限制, 是一种桎梏
有些js第三方库没有dts, 有问题
31. 构造函数实现原理构造函数中没有显示的创建Object对象, 实际上后台自动创建了
直接给this对象赋值属性和方法, this即指向创建的对象
没有return返回值, 后台自动返回了该对象
// 模拟构造函数实现
var Book = function(name) {
this.name = name;
};
//正常用法
var java = new Book(‘Master Java’);
//使用代码模拟,在非IE浏览器中测试,IE浏览器不支持
var python = {};
python.__proto__ = Book.prototype;
Book.call(python, 'Master Python');
32. for in 和 for of区别
for in遍历数组会遍历到数组原型上的属性和方法, 更适合遍历对象
forEach不支持break, continue, return等
使用for of可以成功遍历数组的值, 而不是索引, 不会遍历原型
for in 可以遍历到myObject的原型方法method,如果不想遍历原型方法和属性的话,可以在循环内部判断一下,hasOwnPropery方法可以判断某属性是否是该对象的实例属性
33. JS实现并发控制:使用消息队列以及setInterval或promise进行入队和出队
34. ajax和axios、fetch的区别 35. promise.finally实现Promise.prototype.finally = function (callback) {
let P = this.constructor;
return this.then(
value => P.resolve(callback()).then(() => value),
reason => P.resolve(callback()).then(() => { throw reason })
);
};
浏览器网络相关
1. reflow(回流)和repaint(重绘)优化
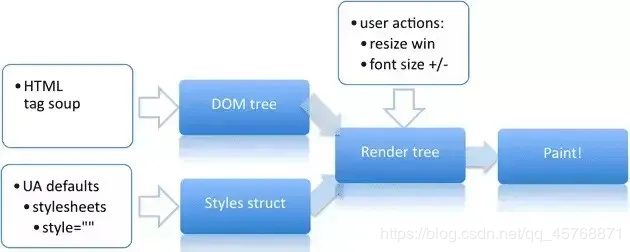
浏览器渲染过程: DOM tree, CSS tree --> Render tree --> Paint
DOM tree根节点为html
渲染从浏览器左上角到右下角
第一次打开页面至少触发一次重绘和回流, 结构如宽高位置变化时, 触发reflow回流;非结构如背景色变化时, 触发repaint重绘. 二者都会造成体验不佳
如何减少重绘和回流?
通过classname或cssText一次性修改样式, 而非一个一个改
离线模式: 克隆要操作的结点, 操作后再与原始结点交换, 类似于虚拟DOM
避免频繁直接访问计算后的样式, 而是先将信息保存下来
绝对布局的DOM, 不会造成大量reflow
p不要嵌套太深, 不要超过六层
2.一个页面从输入 URL 到页面加载显示完成,这个过程中都发生了什么?浏览器根据请求的URL交给DNS域名解析,找到真实IP,向服务器发起请求;
服务器交给后台处理完成后返回数据,浏览器接收文件(HTML、JS、CSS、图象等);
浏览器对加载到的资源(HTML、JS、CSS等)进行语法解析,建立相应的内部数据结构(如HTML的DOM Tree);
载入解析到的资源文件,渲染页面,完成。
3.localStorage 与 sessionStorage 与cookie的区别总结共同点: 都保存在浏览器端, 且同源
localStorage 与 sessionStorage 统称webStorage,保存在浏览器,不参与服务器通信,大小为5M
生命周期不同: localStorage永久保存, sessionStorage当前会话, 都可手动清除
作用域不同: 不同浏览器不共享local和session, 不同会话不共享session
Cookie: 设置的过期时间前一直有效, 大小4K.有个数限制, 各浏览器不同, 一般为20个.携带在HTTP头中, 过多会有性能问题.可自己封装, 也可用原生
4.浏览器如何阻止事件传播,阻止默认行为阻止事件传播(冒泡): e.stopPropagation()
阻止默认行为: e.preventDefault()
5.虚拟DOM方案相对原生DOM操作有什么优点,实现上是什么原理?虚拟DOM可提升性能, 无须整体重新渲染, 而是局部刷新.
JS对象, diff算法
事件捕获阶段: 从dom树节点往下找到目标节点, 不会触发函数
事件目标处理函数: 到达目标节点
事件冒泡: 最后从目标节点往顶层元素传递, 通常函数在此阶段执行.
addEventListener第三个参数默认false(冒泡阶段执行),true(捕获阶段执行).
阻止冒泡见以上方法
跨域是指一个域下的文档或脚本试图去请求另一个域下的资源
防止XSS、CSFR等攻击, 协议+域名+端口不同
jsonp; 跨域资源共享(CORS)(Access control); 服务器正向代理等
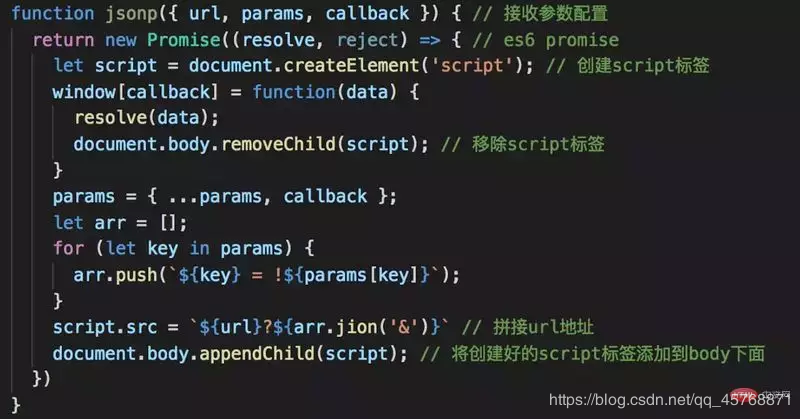
预检请求: 需预检的请求要求必须首先使用 OPTIONS 方法发起一个预检请求到服务器,以获知服务器是否允许该实际请求。"预检请求“的使用,可以避免跨域请求对服务器的用户数据产生未预期的影响
8.了解浏览器缓存机制吗?浏览器缓存就是把一个已经请求过的资源拷贝一份存储起来,当下次需要该资源时,浏览器会根据缓存机制决定直接使用缓存资源还是再次向服务器发送请求.
from memory cache ; from disk cache
作用: 减少网络传输的损耗以及降低服务器压力。
优先级: 强制缓存 > 协商缓存; cache-control > Expires > Etag > Last-modified
9.为什么操作 DOM 慢?DOM本身是一个js对象, 操作这个对象本身不慢, 但是操作后触发了浏览器的行为, 如repaint和reflow等浏览器行为, 使其变慢
10.什么情况会阻塞渲染?js脚本同步执行
css和图片虽然是异步加载, 但js文件执行需依赖css, 所以css也会阻塞渲染
11.如何判断js运行在浏览器中还是node中?判断有无全局对象global和window
12.关于web以及浏览器处理预加载有哪些思考?图片等静态资源在使用之前就提前请求
资源使用到的时候能从缓存中加载, 提升用户体验
页面展示的依赖关系维护
Keep-Alive: Keep-Alive解决的核心问题:一定时间内,同一域名多次请求数据,只建立一次HTTP请求,其他请求可复用每一次建立的连接通道,以达到提高请求效率的问题。这里面所说的一定时间是可以配置的,不管你用的是Apache还是nginx。
解决两个问题: 串行文件传输(采用二进制数据帧); 连接数过多(采用流, 并行传输)
14. http和https:http: 最广泛网络协议,BS模型,浏览器高效。
https: 安全版,通过SSL加密,加密传输,身份认证,密钥
https相对于http加入了ssl层, 加密传输, 身份认证;
需要到ca申请收费的证书;
安全但是耗时多,缓存不是很好;
注意兼容http和https;
连接方式不同, 端口号也不同, http是80, https是443
15. CSRF和XSS区别及防御CSRF(Cross-site request forgery):跨站请求伪造。
PS:中文名一定要记住。英文全称,如果记不住也拉倒。
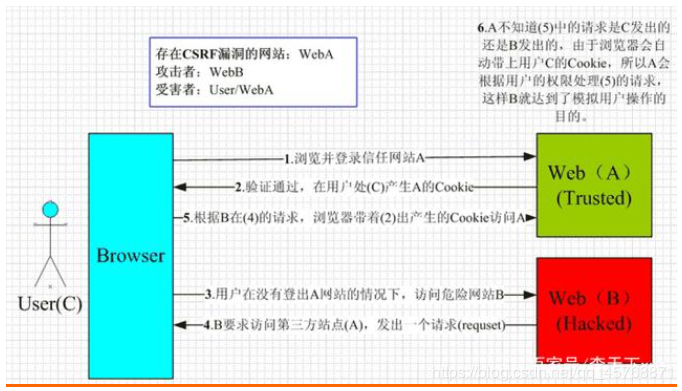
用户是网站A的注册用户,且登录进去,于是网站A就给用户下发cookie。
从上图可以看出,要完成一次CSRF攻击,受害者必须满足两个必要的条件:
(1)登录受信任网站A,并在本地生成Cookie。(如果用户没有登录网站A,那么网站B在诱导的时候,请求网站A的api接口时,会提示你登录)
(2)在不登出A的情况下,访问危险网站B(其实是利用了网站A的漏洞)。
我们在讲CSRF时,一定要把上面的两点说清楚。
温馨提示一下,cookie保证了用户可以处于登录状态,但网站B其实拿不到 cookie。
3、CSRF如何防御
方法一、Token 验证:(用的最多)
(1)服务器发送给客户端一个token;
(2)客户端提交的表单中带着这个token。
(3)如果这个 token 不合法,那么服务器拒绝这个请求。
方法二:隐藏令牌:
把 token 隐藏在 http 的 head头中。
方法二和方法一有点像,本质上没有太大区别,只是使用方式上有区别。
方法三、Referer 验证:
Referer 指的是页面请求来源。意思是,只接受本站的请求,服务器才做响应;如果不是,就拦截。
XSS
1、XSS的基本概念
XSS(Cross Site Scripting):跨域脚本攻击。
2. XSS的攻击原理
XSS攻击的核心原理是:不需要你做任何的登录认证,它会通过合法的操作(比如在url中输入、在评论框中输入),向你的页面注入脚本(可能是js、hmtl代码块等)。
最后导致的结果可能是:
盗用Cookie破坏页面的正常结构,插入广告等恶意内容D-doss攻击
XSS的攻击方式
1、反射型
发出请求时,XSS代码出现在url中,作为输入提交到服务器端,服务器端解析后响应,XSS代码随响应内容一起传回给浏览器,最后浏览器解析执行XSS代码。这个过程像一次反射,所以叫反射型XSS。
2、存储型存
储型XSS和反射型XSS的差别在于,提交的代码会存储在服务器端(数据库、内存、文件系统等),下次请求时目标页面时不用再提交XSS代码。
XSS的防范措施(encode + 过滤)
XSS的防范措施主要有三个:
1、编码:
对用户输入的数据进行
HTML Entity 编码。
如上图所示,把字符转换成 转义字符。
Encode的作用是将
$var
等一些字符进行转化,使得浏览器在最终输出结果上是一样的。
比如说这段代码:
alert(1)
若不进行任何处理,则浏览器会执行alert的js操作,实现XSS注入。
进行编码处理之后,L在浏览器中的显示结果就是
alert(1)
实现了将$var作为纯文本进行输出,且不引起JavaScript的执行。
2、过滤:
移除用户输入的和事件相关的属性。如onerror可以自动触发攻击,还有onclick等。(总而言是,过滤掉一些不安全的内容)移除用户输入的Style节点、Script节点、Iframe节点。(尤其是Script节点,它可是支持跨域的呀,一定要移除)。
3、校正
避免直接对HTML Entity进行解码。使用DOM Parse转换,校正不配对的DOM标签。备注:我们应该去了解一下
DOM Parse
这个概念,它的作用是把文本解析成DOM结构。
比较常用的做法是,通过第一步的编码转成文本,然后第三步转成DOM对象,然后经过第二步的过滤。
还有一种简洁的答案:
首先是encode,如果是富文本,就白名单。
CSRF 和 XSS 的区别
区别一:
CSRF:需要用户先登录网站A,获取 cookie。XSS:不需要登录。
区别二:(原理的区别)
CSRF:是利用网站A本身的漏洞,去请求网站A的api。XSS:是向网站 A 注入 JS代码,然后执行 JS 里的代码,篡改网站A的内容。
chrome控制台的application下可查看:

name 字段为一个cookie的名称。
value 字段为一个cookie的值。
domain 字段为可以访问此cookie的域名。
path 字段为可以访问此cookie的页面路径。比如domain是abc.com,path是/test,那么只有/test路径下的页面可以读取此cookie。
expires/Max-Age 字段为此cookie超时时间。若设置其值为一个时间,那么当到达此时间后,此cookie失效。不设置的话默认值是Session,意思是cookie会和session一起失效。当浏览器关闭(不是浏览器标签页,而是整个浏览器) 后,此cookie失效。
Size 字段 此cookie大小。
http 字段 cookie的httponly属性。若此属性为true,则只有在http请求头中会带有此cookie的信息,而不能通过document.cookie来访问此cookie。
secure 字段 设置是否只能通过https来传递此条cookie
17. 登录后,前端做了哪些工作,如何得知已登录前端存放服务端下发的cookie, 简单说就是写一个字段在cookie中表明已登录, 并设置失效日期
或使用后端返回的token, 每次ajax请求将token携带在请求头中, 这也是防范csrf的手段之一
18. http状态码1**: 服务器收到请求, 需请求者进一步操作
2**: 请求成功
3**: 重定向, 资源被转移到其他URL了
4**: 客户端错误, 请求语法错误或没有找到相应资源
5**: 服务端错误, server error
301: 资源(网页等)被永久转移到其他URL, 返回值中包含新的URL, 浏览器会自动定向到新URL
302: 临时转移. 客户端应访问原有URL
304: Not Modified. 指定日期后未修改, 不返回资源
403: 服务器拒绝执行请求
404: 请求的资源(网页等)不存在
500: 内部服务器错误
19. # Http请求头缓存设置方法
Cache-control, expire, last-modify
旧: window.history.back() + window.location.href=document.referrer;
新: HTML5的新API扩展了window.history,使历史记录点更加开放了。可以存储当前历史记录点、替换当前历史记录点、监听历史记录点onpopstate, replaceState
正向代理和反向代理正向代理:

(1)访问原来无法访问的资源,如google
(2) 可以做缓存,加速访问资源
(3)对客户端访问授权,上网进行认证
(4)代理可以记录用户访问记录(上网行为管理),对外隐藏用户信息
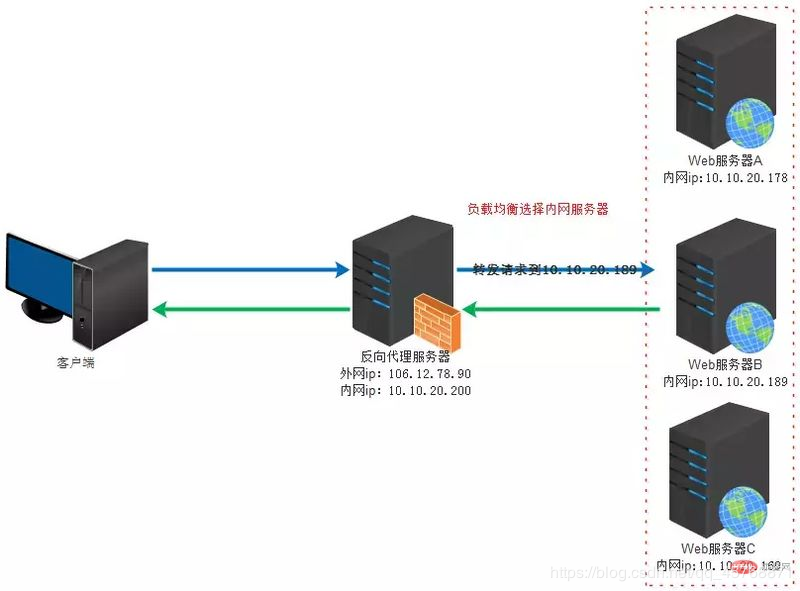
(1)保证内网的安全,可以使用反向代理提供WAF功能,阻止web攻击大型网站,通常将反向代理作为公网访问地址,Web服务器是内网。
(2)负载均衡,通过反向代理服务器来优化网站的负载
22. 关于预检请求在非简单请求且跨域的情况下,浏览器会自动发起options预检请求。
23. 三次握手四次挥手开启连接用三次握手, 关闭用四次挥手
24. TCP和UDP协议TCP(Transmission Control Protocol:传输控制协议;面向连接,可靠传输
UDP(User Datagram Protocol):用户数据报协议;面向无连接,不可靠传输
25. 进程和线程的区别进程:是并发执行的程序在执行过程中分配和管理资源的基本单位,是一个动态概念,竞争计算机系统资源的基本单位。
线程:是进程的一个执行单元,是进程内科调度实体。比进程更小的独立运行的基本单位。线程也被称为轻量级进程。
一个程序至少一个进程,一个进程至少一个线程。
vue相关 生命周期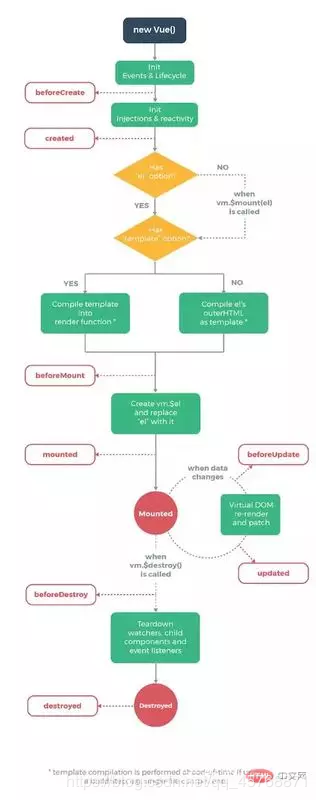 2 .双向数据绑定v-model。这个最好也是自己实现一下 理解更深
通过v-model
2 .双向数据绑定v-model。这个最好也是自己实现一下 理解更深
通过v-modelVUE实现双向数据绑定的原理就是利用了 Object.defineProperty() 这个方法重新定义了对象获取属性值(get)和设置属性值(set)的操作来实现的。
// 依赖收集
// 简化版
var obj = { }
var name
//第一个参数:定义属性的对象。
//第二个参数:要定义或修改的属性的名称。
//第三个参数:将被定义或修改的属性描述符。
Object.defineProperty(obj, "data", {
//获取值
get: function () {
return name
},
//设置值
set: function (val) {
name = val
console.log(val)
}
})
//赋值调用set
obj.data = 'aaa'
//取值调用get
console.log(obj.data)
// 详细版
myVue.prototype._obverse = function (obj) { // obj = {number: 0}
var value;
for (key in obj) { //遍历obj对象
if (obj.hasOwnProperty(key)) {
value = obj[key];
if (typeof value === 'object') { //如果值是对象,则递归处理
this._obverse(value);
}
Object.defineProperty(this.$data, key, { //关键
enumerable: true,
configurable: true,
get: function () {
console.log(`获取${value}`);
return value;
},
set: function (newVal) {
console.log(`更新${newVal}`);
if (value !== newVal) {
value = newVal;
}
}
})
}
}
}
3.vue父子组件传递参数
父 -->子: 通过props
子 -->父: 通过 $$refs 或 $emit
4.vue传递参数方法父子组件传参如上, v-bind : v-on @
兄弟组件传参:(通过EventBus事件总线实现)
// 1\. 新建eventBus.js
import Vue from 'vue'
export default new Vue
// 或直接在main.js中初始化EventBus(全局)
Vue.prototype.$EventBus = new Vue()
// 2\. 发射与接收
// 如果是定义在eventBus.js中
import eventBus from 'eventBus.js'
eventBus.$emit()
eventBus.$on()
// 如果是定义在main.js中
this.bus.$emit()
this.bus.$on()
// 3\. 移除监听
eventBus.$off()
5.vue自定义组件
可以使用独立可复用的自定义组件来构成大型应用, 采用帕斯卡命名法或横线连接, 通过以上方式进行组件间通信. 每一个组件都是Vue实例, 可以使用生命周期钩子.
6. vue自定义指令除核心指令之外的指令, 使用directive进行注册.
指令自定义钩子函数: bind, inserted, update, componentUpdated, unbind
7.vuex组成和原理组成: 组件间通信, 通过store实现全局存取
修改: 唯一途径, 通过commit一个mutations(同步)或dispatch一个actions(异步)
简写: 引入mapState、mapGetters、mapActions
8.vue-router的原理,例如hashhistory和History interface这些东西要弄明白。其实看一下源码就好了,看不懂可以直接看解析的相关技术博客。vue-router用法:
在router.js或者某一个路由分发页面配置path, name, component对应关系
每个按钮一个value, 在watch功能中使用this.$router.push实现对应跳转, 类似react的this.history.push
或直接用router-link to去跳转, 类似react的link to
vue-router原理: 通过hash和History interface两种方式实现前端路由
HashHistory: 利用URL中的hash(“#”);replace()方法与push()方法不同之处在于,它并不是将新路由添加到浏览器访问历史的栈顶,而是替换掉当前的路由
History interface: 是浏览器历史记录栈提供的接口,通过back(), forward(), go()等方法,我们可以读取浏览器历史记录栈的信息,进行各种跳转操作. pushState(), replaceState() 这下不仅是读取了,还可以对浏览器历史记录栈进行修改
9.vue的seo问题seo关系到网站排名, vue搭建spa做前后端分离不好做seo, 可通过其他方法解决:
SSR服务端渲染: 将同一个组件渲染为服务器端的 HTML 字符串.利于seo且更快.
vue-meta-info, nuxt, prerender-spa-plugin页面预渲染等
10.预渲染和ssr以上
11.生命周期内create和mounted的区别created: 在模板渲染成html前调用,即通常初始化某些数据,然后再渲染成视图。
mounted: 在模板渲染成html后调用,通常是初始化页面完成后,再对html的dom节点进行一些需要的操作和方法。
12.监听watch对应一个对象,键是观察表达式,值是对应回调。值也可以是methods的方法名,或者是对象,包含选项。在实例化时为每个键调用 $watch()
13.登录验证拦截(通过router) 先设置requireAuth:routes = [
{
name: 'detail',
path: '/detail',
meta: {
requireAuth: true
}
},
{
name: 'login',
path: '/login'
}
]
再配置router.beforeEach:
router.beforeEach((from, to, next) => {
if (to.meta.requireAuth) { // 判断跳转的路由是否需要登录
if (store.state.token) { // vuex.state判断token是否存在
next() // 已登录
} else {
next({
path: '/login',
query: {redirect: to.fullPath} // 将跳转的路由path作为参数,登录成功后跳转到该路由
})
}
} else {
next()
}
})
14. v-for key值
不写key值会报warning, 和react的array渲染类似. 根据diff算法, 修改数组后, 写key值会复用, 不写会重新生成, 造成性能浪费或某些不必要的错误
15. vue3.0的更新和defineProperty优化放弃 Object.defineProperty ,使用更快的原生 Proxy (访问对象拦截器, 也成代理器)
提速, 降低内存使用, Tree-shaking更友好
支持IE11等
使用Typescript
15. vue使用this获取变量![正常要通过vm.[图片上传失败...(image-6d2f4e-1570591304185)]](/upload/wp-content/uploads/2020/04/20200403163836923.png)
root传参取值
16. jQuery的优缺点,与vue的不同,vue的优缺点?jq优点: 比原生js更易书写, 封装了很多api, 有丰富的插件库; 缺点: 每次升级与之前版本不兼容, 只能手动开发, 操作DOM很慢, 不方便, 变量名污染, 作用域混淆等。
vue优缺点: 双向绑定, 虚拟DOM, diff算法, MVVM, 组件化, 通信方便, 路由分发等
17. vue解除双向绑定let obj = JSON.parse(JSON.stringify(this.temp1));
18. vue异步组件
为了简化,Vue 允许你以一个工厂函数的方式定义你的组件,这个工厂函数会异步解析你的组件定义。Vue 只有在这个组件需要被渲染的时候才会触发该工厂函数,且会把结果缓存起来供未来重渲染
Vue.component(
'async-webpack-example',
// 这个 `import` 函数会返回一个 `Promise` 对象。
() => import('./my-async-component')
)
19. MVC与MVVM
model-数据层 view-视图层 controller-控制层
MVC的目的是实现M和V的分离,单向通信,必须通过C来承上启下
MVVM中通过VM(vue中的实例化对象)的发布者-订阅者模式实现双向绑定,数据绑定,dom事件监听
区别:MVC和MVVM的区别并不是VM完全取代了C,ViewModel存在目的在于抽离Controller中展示的业务逻辑,而不是替代Controller,其它视图操作业务等还是应该放在Controller中实现。也就是说MVVM实现的是业务逻辑组件的重用
20. vue渐进式小到可以只使用核心功能,比如单文件组件作为一部分嵌入;大到使用整个工程,vue init webpack my-project来构建项目;VUE的核心库及其生态系统也可以满足你的各式需求(core+vuex+vue-route)
react相关 1. 新旧生命周期旧: will, did; mount, update…
新: 16版本之后:
getDerivedStateFromProps: 虚拟dom之后,实际dom挂载之前, 每次获取新的props或state之后, 返回新的state, 配合didUpdate可以替代willReceiveProps
getSnapshotBeforeUpdate: update发生的时候,组件更新前触发, 在render之后,在组件dom渲染之前;返回一个值,作为componentDidUpdate的第三个参数;配合componentDidUpdate, 可以覆盖componentWillUpdate的所有用法
componentDidCatch: 错误处理
对比: 弃用了三个will, 新增两个get来代替will, 不能混用, 17版本会彻底删除. 新增错误处理
2. react核心虚拟DOM, Diff算法, 遍历key值
react-dom: 提供了针对DOM的方法,比如:把创建的虚拟DOM,渲染到页面上 或 配合ref来操作DOM
react-router
3. fiber核心(react 16)旧: 浏览器渲染引擎单线程, 计算DOM树时锁住整个线程, 所有行为同步发生, 有效率问题, 期间react会一直占用浏览器主线程,如果组件层级比较深,相应的堆栈也会很深,长时间占用浏览器主线程, 任何其他的操作(包括用户的点击,鼠标移动等操作)都无法执行。
新: 重写底层算法逻辑, 引入fiber时间片, 异步渲染, react会在渲染一部分树后检查是否有更高优先级的任务需要处理(如用户操作或绘图), 处理完后再继续渲染, 并可以更新优先级, 以此管理渲染任务. 加入fiber的react将组件更新分为两个时期(phase 1 && phase 2),render前的生命周期为phase1,render后的生命周期为phase2, 1可以打断, 2不能打断一次性更新. 三个will生命周期可能会重复执行, 尽量避免使用。
4. 渲染一个react分为首次渲染和更新渲染
生命周期, 建立虚拟DOM, 进行diff算法
对比新旧DOM, 节点对比, 将算法复杂度从O(n^3)降低到O(n)
key值优化, 避免用index作为key值, 兄弟节点中唯一就行
5. 高阶组件高阶组件就是一个函数,且该函数(wrapper)接受一个组件作为参数,并返回一个新的组件。
高阶组件并不关心数据使用的方式和原因,而被包裹的组件也不关心数据来自何处.
export default DragSource(type, spec, collect)(MyComponent)
重构代码库使用HOC提升开发效率
6. hook(v16.7测试)
在无状态组件(如函数式组件)中也能操作state以及其他react特性, 通过useState
7. redux和vuex以及dva:redux: 通过store存储,通过action唯一更改,reducer描述如何更改。dispatch一个action
dva: 基于redux,结合redux-saga等中间件进行封装
vuex:类似dva,集成化。action异步,mutation非异步
8. react和vue的区别数据是否可变: react整体是函数式的思想,把组件设计成纯组件,状态和逻辑通过参数传入,所以在react中,是单向数据流,推崇结合immutable来实现数据不可变; vue的思想是响应式的,也就是基于是数据可变的,通过对每一个属性建立Watcher来监听,当属性变化的时候,响应式的更新对应的虚拟dom。总之,react的性能优化需要手动去做,而vue的性能优化是自动的,但是vue的响应式机制也有问题,就是当state特别多的时候,Watcher也会很多,会导致卡顿,所以大型应用(状态特别多的)一般用react,更加可控。
通过js来操作一切,还是用各自的处理方式: react的思路是all in js,通过js来生成html,所以设计了jsx,还有通过js来操作css,社区的styled-component、jss等; vue是把html,css,js组合到一起,用各自的处理方式,vue有单文件组件,可以把html、css、js写到一个文件中,html提供了模板引擎来处理。
类式的组件写法,还是声明式的写法: react是类式的写法,api很少; 而vue是声明式的写法,通过传入各种options,api和参数都很多。所以react结合typescript更容易一起写,vue稍微复杂。
**扩展不同: **react可以通过高阶组件(Higher Order Components–HOC)来扩展,而vue需要通过mixins来扩展。
什么功能内置,什么交给社区去做: react做的事情很少,很多都交给社区去做,vue很多东西都是内置的,写起来确实方便一些,
比如 redux的combineReducer就对应vuex的modules,
比如reselect就对应vuex的getter和vue组件的computed,
vuex的mutation是直接改变的原始数据,而redux的reducer是返回一个全新的state,所以redux结合immutable来优化性能,vue不需要。
React是单向数据流,数据主要从父节点传递到子节点(通过props)。如果顶层(父级)的某个props改变了,React会重渲染所有的子节点。
10. React算法复杂度优化react树对比是按照层级去对比的, 他会给树编号0,1,2,3,4… 然后相同的编号进行比较。所以复杂度是n,这个好理解。
关键是传统diff的复杂度是怎么算的?传统的diff需要出了上面的比较之外,还需要跨级比较。他会将两个树的节点,两两比较,这就有n2的复杂度了。然后还需要编辑树,编辑的树可能发生在任何节点,需要对树进行再一次遍历操作,因此复杂度为n。加起来就是n3了。
11. React优点声明式, 组件化, 一次学习, 随处编写. 灵活, 丰富, 轻巧, 高效
移动端相关 1. 移动端兼容适配
rem, em, 百分比
框架的栅格布局
media query媒体查询
手淘团队的一套flexible.js, 自动判断dpr进行整个布局视口的放缩
2. flexible如何实现自动判断dpr判断机型, 找出样本机型去适配. 比如iphone以6为样本, 宽度375px, dpr是2
3. 为什么以iPhone6为标准的设计稿的尺寸是以750px宽度来设计的呢?iPhone6的满屏宽度是375px,而iPhone6采用的视网膜屏的物理像素是满屏宽度的2倍,也就是dpr(设备像素比)为2, 并且设计师所用的PS设计软件分辨率和像素关系是1:1。所以为了做出的清晰的页面,设计师一般给出750px的设计图,我们再根据需求对元素的尺寸设计和压缩。
4. 如何处理异形屏iphone Xsafe area: 默认放置在安全区域以避免遮挡, 但会压缩
在meta中添加viewport-fit=cover: 告诉浏览器要讲整个页面渲染到浏览器中,不管设备是圆角与否,这个时候会造成页面的元素被圆角遮挡
padding: constant(env): 解决遮挡问题
5. 移动端首屏优化采用服务器渲染ssr
按需加载配合webpack分块打包, 通过entry和commonChunkPlugin
很有必要将script标签➕异步
有轮播图 最好给个默认 另外要处理图片懒加载
打包线上也要注意去掉map 文件
组件, 路由懒加载
webpack的一切配置 肯定是必须的
压缩图片 tinypng.com/
建议还是用webpack的图片压缩插件
骨架屏
Loading页面
6. PWA全称Progressive Web App,即渐进式WEB应用一个 PWA 应用首先是一个网页, 可以通过 Web 技术编写出一个网页应用. 随后添加上 App Manifest 和 Service Worker 来实现 PWA 的安装和离线等功能
解决了哪些问题?
它解决了上述提到的问题,这些特性将使得 Web 应用渐进式接近原生 App。 7. 离线包方案
现在 web 页面在移动端的地位越来越高,大部分主流 App 采用 native + webview 的 hybrid 模式,加载远程页面受限于网络,本地 webview 引擎,经常会出现渲染慢导致的白屏现象,体验很差,于是离线包方案应运而生。动态下载的离线包可以使得我们不需要走完整的 App 审核发布流程就完成了版本的更新
8. 自适应和响应式布局的区别 自适应布局通过检测视口分辨率,来判断当前访问的设备是:pc端、平板、手机,从而请求服务层,返回不同的页面;响应式布局通过检测视口分辨率,针对不同客户端在客户端做代码处理,来展现不同的布局和内容。 自适应布局需要开发多套界面,而响应式布局只需要开发一套界面就可以了。 自适应对页面做的屏幕适配是在一定范围:比如pc端一般要大于1024像素,手机端要小于768像素。而响应式布局是一套页面全部适应。 自适应布局如果屏幕太小会发生内容过于拥挤。而响应式布局正是为了解决这个问题而衍生出的概念,它可以自动识别屏幕宽度并做出相应调整的网页设计。 插件及工具相关 1. babel和polyfillBabel: Babel 是一个广泛使用的 ES6 转码器,可以将 ES6 代码转为 ES5 代码。注意:Babel 默认只转换新的 JavaScript 句法(syntax),而不转换新的 API
Polyfill: Polyfill的准确意思为,用于实现浏览器并不支持的原生API的代码。
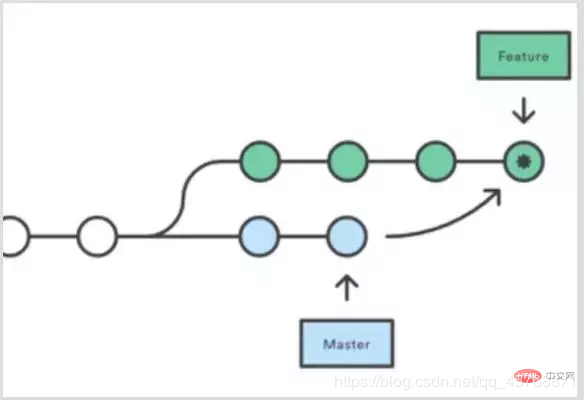
2. jpg, jpeg和png区别 jpg是jpeg的缩写, 二者一致 PNG就是为取代GIF而生的, 无损压缩, 占用内存多 jpg牺牲图片质量, 有损, 占用内存小 PNG格式可编辑。如图片中有字体等,可利用PS再做更改。JPG格式不可编辑 3. git rebase和merge区别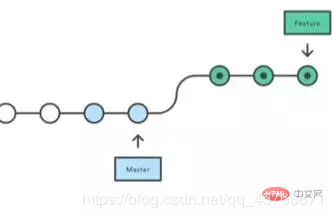
减少HTTP请求(合并css、js,雪碧图/base64图片)
压缩(css、js、图片皆可压缩,使用webpack uglify和 svg)
样式表放头部,脚本放底部
使用CDN(这部分,不少前端都不用考虑,负责发布的兄弟可能会负责搞好)
http缓存
bosify图片压缩: 根据具体情况修改图片后缀或格式 后端根据格式来判断存储原图还是缩略图
懒加载, 预加载
替代方案: 骨架屏, SSR
webpack优化
原生通信1.JSBridge通信原理, 有哪几种实现的方式?
JsBridge给JavaScript提供了调用Native功能,Native也能够操控JavaScript。这样前端部分就可以方便使用地理位置、摄像头以及登录支付等Native能力啦。JSBridge构建 Native和非Native间消息通信的通道,而且是 双向通信的通道。
JS 向 Native 发送消息 : 调用相关功能、通知 Native 当前 JS 的相关状态等。
Native 向 JS 发送消息 : 回溯调用结果、消息推送、通知 JS 当前 Native 的状态等。
2.实现一个简单的 JSBridge,设计思路?
算法相关 1. 二分查找和冒泡排序二分查找: 递归(分左右, 传递start,end参数)和非递归(使用while(l < h))
冒泡排序: 两个for循环
2. 快速排序function quickSort (arr) {
if (arr.length < 2) return arr
var middle = Math.floor(arr.length / 2)
var flag = arr.splice(middle, 1)[0]
var left = [],
right = []
for (var i = 0; i < arr.length; i++) {
if (arr[i] < flag) {
left.push(arr[i])
} else {
right.push(arr[i])
}
}
return quickSort(left).concat([flag], quickSort(right))
}
3. 最长公共子串
function findSubStr(str1, str2) {
if (str1.length > str2.length) {
[str1, str2] = [str2, str1]
}
var result = ''
var len = str1.length
for (var j = len; j > 0; j--) {
for (var i = 0; i < len - j; i++) {
result = str1.substr(i, j)
if (str2.includes(result)) return result
}
}
}
console.log(findSubStr('aabbcc11', 'ppooiiuubcc123'))
4. 最长公共子序列(LCS动态规划)
另一篇
// dp[i][j] 计算去最大长度,记住口诀:相等左上角加一,不等取上或左最大值
function LCS(str1, str2){
var rows = str1.split("")
rows.unshift("")
var cols = str2.split("")
cols.unshift("")
var m = rows.length
var n = cols.length
var dp = []
for(var i = 0; i < m; i++){
dp[i] = []
for(var j = 0; j 0 && j>0){
if(input1[i] == input2[j]){
result.unshift(input1[i]);
i--;
j--;
}else{
//向左或向上回退
if(T[i-1][j]>T[i][j-1]){
//向上回退
i--;
}else{
//向左回退
j--;
}
}
}
console.log(result);
}
5. 数组去重,多种方法
双for循环, splice剔除并i--回退
indexOf等于index
filter indexOf === index
新数组indexOf === index
使用空对象等
6. 实现一个函数功能:sum(1,2,3,4…n)转化为 sum(1)(2)(3)(4)…(n)
// 使用柯里化 + 递归
function curry ( fn ) {
var c = (...arg) => (fn.length === arg.length) ?
fn (...arg) : (...arg1) => c(...arg, ...arg1)
return c
}
7. 反转二叉树
var invertTree = function (root) {
if (root !== null) {
[root.left, root.right] = [root.right, root.left]
invertTree(root.left)
invertTree(root.right)
}
return root
}
8. 贪心算法解决背包问题
var items = ['A','B','C','D']
var values = [50,220,60,60]
var weights = [5,20,10,12]
var capacity = 32 //背包容积
greedy(values, weights, capacity) // 320
function greedy(values, weights, capacity) {
var result = 0
var rest = capacity
var sortArray = []
var num = 0
values.forEach((v, i) => {
sortArray.push({
value: v,
weight: weights[i],
ratio: v / weights[i]
})
})
sortArray.sort((a, b) => b.ratio - a.ratio)
sortArray.forEach((v, i) => {
num = parseInt(rest / v.weight)
rest -= num * v.weight
result += num * v.value
})
return result
}
9. 输入一个递增排序的数组和一个数字S,在数组中查找两个数,使得他们的和正好是S,如果有多对数字的和等于S,输出两个数的乘积最小的。
function FindNumbersWithSum(array, sum)
{
var index = 0
for (var i = 0; i < array.length - 1 && array[i] < sum / 2; i++) {
for (var j = i + 1; j < array.length; j++) {
if (array[i] + array[j] === sum) return [array[i], array[j]]
}
//index = array.indexOf(sum - array[i], i + 1)
// if (index !== -1) {
// return [array[i], array[index]]
//}
}
return []
10. 二叉树各种(层序)遍历
深度广度遍历
// 根据前序和中序重建二叉树
/* function TreeNode(x) {
this.val = x;
this.left = null;
this.right = null;
} */
function reConstructBinaryTree(pre, vin)
{
var result = null
if (pre.length === 1) {
result = {
val: pre[0],
left: null,
right: null
}
} else if (pre.length > 1) {
var root = pre[0]
var vinRootIndex = vin.indexOf(root)
var vinLeft = vin.slice(0, vinRootIndex)
var vinRight = vin.slice(vinRootIndex + 1, vin.length)
pre.shift()
var preLeft = pre.slice(0, vinLeft.length)
var preRight = pre.slice(vinLeft.length, pre.length)
result = {
val: root,
left: reConstructBinaryTree(preLeft, vinLeft),
right: reConstructBinaryTree(preRight, vinRight)
}
}
return result
}
// 递归
// 前序遍历
function prevTraverse (node) {
if (node === null) return;
console.log(node.data);
prevTraverse(node.left);
prevTraverse(node.right);
}
// 中序遍历
function middleTraverse (node) {
if (node === null) return;
middleTraverse(node.left);
console.log(node.data);
middleTraverse(node.right);
}
// 后序遍历
function lastTraverse (node) {
if (node === null) return;
lastTraverse(node.left);
lastTraverse(node.right);
console.log(node.data);
}
// 非递归
// 前序遍历
function preTraverse(tree) {
var arr = [],
node = null
arr.unshift(tree)
while (arr.length) {
node = arr.shift()
console.log(node.root)
if (node.right) arr.unshift(node.right)
if (node.left) arr.unshift(node.left)
}
}
// 中序遍历
function middleTraverseUnRecursion (root) {
let arr = [],
node = root;
while (arr.length !== 0 || node !== null) {
if (node === null) {
node = arr.shift();
console.log(node.data);
node = node.right;
} else {
arr.unshift(node);
node = node.left;
}
}
}
// 广度优先-层序遍历
// 递归
var result = []
var stack = [tree]
var count = 0
var bfs = function () {
var node = stack[count]
if (node) {
result.push(node.value)
if (node.left) stack.push(node.left)
if (node.right) stack.push(node.right)
count++
bfs()
}
}
bfs()
console.log(result)
// 非递归
function bfs (node) {
var result = []
var queue = []
queue.push(node)
while (queue.length) {
node = queue.shift()
result.push(node.value)
node.left && queue.push(node.left)
node.right && queue.push(node.right)
}
return result
}
11. 各种排序
// 插入排序
function insertSort(arr) {
var temp
for (var i = 1; i 0 && temp < arr[j - 1]; j--) {
arr[j] = arr[j - 1]
}
arr[j] = temp
}
return arr
}
console.log(insertSort([3, 1, 8, 2, 5]))
// 归并排序
function mergeSort(array) {
var result = array.slice(0)
function sort(array) {
var length = array.length
var mid = Math.floor(length * 0.5)
var left = array.slice(0, mid)
var right = array.slice(mid, length)
if (length === 1) return array
return merge(sort(left), sort(right))
}
function merge(left, right) {
var result = []
while (left.length || right.length) {
if (left.length && right.length) {
if (left[0] < right[0]) {
result.push(left.shift())
} else {
result.push(right.shift())
}
} else if (left.length) {
result.push(left.shift())
} else {
result.push(right.shift())
}
}
return result
}
return sort(result)
}
console.log(mergeSort([5, 2, 8, 3, 6]))
// 二分插入排序
function twoSort(array) {
var len = array.length,
i,
j,
tmp,
low,
high,
mid,
result
result = array.slice(0)
for (i = 1; i < len; i++) {
tmp = result[i]
low = 0
high = i - 1
while (low <= high) {
mid = parseInt((high + low) / 2, 10)
if (tmp = high + 1; j--) {
result[j + 1] = result[j]
}
result[j + 1] = tmp
}
return result
}
console.log(twoSort([4, 1, 7, 2, 5]))
12. 使用尾递归对斐波那契优化
递归非常耗费内存,因为需要同时保存成千上百个调用帧,很容易发生“栈溢出”错误(stack overflow)。但对于尾递归来说,由于只存在一个调用帧,所以永远不会发生“栈溢出”错误。
// 传统递归斐波那契, 会造成超时或溢出
function Fibonacci (n) {
if ( n <= 1 ) {return 1};
return Fibonacci(n - 1) + Fibonacci(n - 2);
}
Fibonacci(10) // 89
Fibonacci(100) // 超时
Fibonacci(500) // 超时
// 使用尾递归优化, 可规避风险
function Fibonacci2 (n , ac1 = 1 , ac2 = 1) {
if( n <= 1 ) {return ac2};
return Fibonacci2 (n - 1, ac2, ac1 + ac2);
}
Fibonacci2(100) // 573147844013817200000
Fibonacci2(1000) // 7.0330367711422765e+208
Fibonacci2(10000) // Infinity
13. 两个升序数组合并为一个升序数组
function sort (A, B) {
var i = 0, j = 0, p = 0, m = A.length, n = B.length, C = []
while (i < m || j < n) {
if (i < m && j < n) {
C[p++] = A[i] < B[j] ? A[i++] : B[j++]
} else if (i < m) {
C[p++] = A[i++]
} else {
C[p++] = B[j++]
}
}
return C
}
后记
喜欢的小伙伴关注收藏哦

作者:前端XQ
面试题
浏览器
前端面试
Web
前端面试题
VUE
性能
面试
前端性能
前端
算法
node
js
React
CSS