Python预测分词的实现
前言
加载模型
构建词网
维特比算法
实战
前言在机器学习中,我们有了训练集的话,就开始预测。预测是指利用模型对句子进行推断的过程。在中文分词任务中也就是利用模型推断分词序列,同时也叫解码。
在HanLP库中,二元语法的解码由ViterbiSegment分词器提供。本篇将详细介绍ViterbiSegment的使用方式
加载模型在前篇博文中,我们已经得到了训练的一元,二元语法模型。后续的处理肯定会基于这几个文件来处理。所以,我们首先要做的就是加载这些模型到程序中:
if __name__ == "__main__":
MODEL_PATH = "123"
HanLP.Config.CoreDictionaryPath = MODEL_PATH + ".txt"
HanLP.Config.BiGramDictionaryPath = MODEL_PATH + ".ngram.txt"
CoreDictionary = SafeJClass("com.hankcs.hanlp.dictionary.CoreDictionary")
CoreBiGramTableDictionary = SafeJClass('com.hankcs.hanlp.dictionary.CoreBiGramTableDictionary')
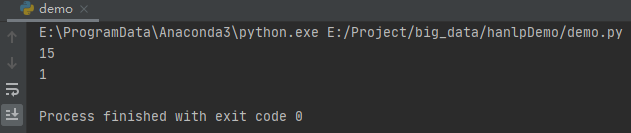
print(CoreDictionary.getTermFrequency("秦机"))
print(CoreBiGramTableDictionary.getBiFrequency("秦机","的"))
运行之后,效果如下:
构建词网这里我们使用CoreDictionary.getTermFrequency()方法获取”秦机“的频次。使用CoreBiGramTableDictionary.getBiFrequency()方法获取“秦机 的”的二元语法频次。
在前文中我们介绍了符号“末##末“,代表句子结尾,”始##始“代表句子开头。而词网指的是句子中所有一元语法构成的网状结构。比如MSR词典中的“秦机和科技”这个句子,是给定的一元词典。我们将句子中所有单词找出来。得到如下词网:
[始##始]
[秦机]
[]
[和,和科]
[科技]
[技]
[末##末]
对应的此图如下所示:
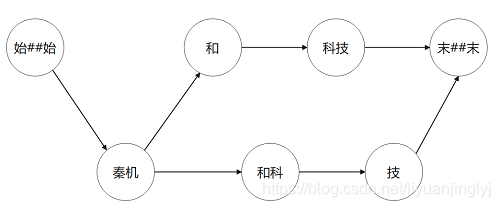
当然,这里博主只是举例说明词网的概念,“和科”并不是一个单词。
下面,我们来通过方法构建词网。具体代码如下:
def build_wordnet(sent, trie):
JString = JClass('java.lang.String')
Vertex = JClass('com.hankcs.hanlp.seg.common.Vertex')
WordNet = JClass('com.hankcs.hanlp.seg.common.WordNet')
searcher = trie.getSearcher(JString(sent), 0)
wordnet = WordNet(sent)
while searcher.next():
wordnet.add(searcher.begin + 1,
Vertex(sent[searcher.begin:searcher.begin + searcher.length], searcher.value, searcher.index))
# 原子分词,保证图连通
vertexes = wordnet.getVertexes()
i = 0
while i < len(vertexes):
if len(vertexes[i]) == 0: # 空白行
j = i + 1
for j in range(i + 1, len(vertexes) - 1): # 寻找第一个非空行 j
if len(vertexes[j]):
break
wordnet.add(i, Vertex.newPunctuationInstance(sent[i - 1: j - 1])) # 填充[i, j)之间的空白行
i = j
else:
i += len(vertexes[i][-1].realWord)
return wordnet
if __name__ == "__main__":
MODEL_PATH = "123"
HanLP.Config.CoreDictionaryPath = MODEL_PATH + ".txt"
HanLP.Config.BiGramDictionaryPath = MODEL_PATH + ".ngram.txt"
CoreDictionary = SafeJClass("com.hankcs.hanlp.dictionary.CoreDictionary")
CoreBiGramTableDictionary = SafeJClass('com.hankcs.hanlp.dictionary.CoreBiGramTableDictionary')
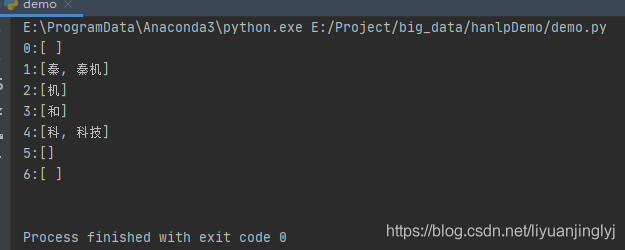
print(build_wordnet("秦机和科技", CoreDictionary.trie))
运行之后,我们会得到与上图归纳差不多的内容:
如果现在我们赋予上述词图每条边以二元语法的概率作为距离,那么如何求解词图上的最短路径就是一个关键问题。
假设文本长度为n,则一共有2(n-1次方)种切分方式,因为每2个字符间都有2种选择:切或者不切,时间复杂度就为O(2(n-1次方))。显然不切实际,这里我们考虑使用维特比算法。
维特比算法原理:它分为前向和后向两个步骤。
前向:由起点出发从前往后遍历节点,更新从起点到该节点的最下花费以及前驱指针
后向:由终点出发从后往前回溯前驱指针,取得最短路径
维特比算法用python代码的实现如下:
def viterbi(wordnet):
nodes = wordnet.getVertexes()
# 前向遍历
for i in range(0, len(nodes) - 1):
for node in nodes[i]:
for to in nodes[i + len(node.realWord)]:
# 根据距离公式计算节点距离,并维护最短路径上的前驱指针from
to.updateFrom(node)
# 后向回溯
# 最短路径
path = []
# 从终点回溯
f = nodes[len(nodes) - 1].getFirst()
while f:
path.insert(0, f)
# 按前驱指针from回溯
f = f.getFrom()
return [v.realWord for v in path]
实战
现在我们来做个测试,我们在msr_test_gold.utf8上训练模型,为秦机和科技常见词图,最后运行维特比算法。详细代码如下所示:
if __name__ == "__main__":
MODEL_PATH = "123"
corpus_path = r"E:\ProgramData\Anaconda3\Lib\site-packages\pyhanlp\static\data\test\icwb2-data\gold\msr_test_gold.utf8"
train_model(corpus_path, MODEL_PATH)
HanLP.Config.CoreDictionaryPath = MODEL_PATH + ".txt"
HanLP.Config.BiGramDictionaryPath = MODEL_PATH + ".ngram.txt"
CoreDictionary = SafeJClass("com.hankcs.hanlp.dictionary.CoreDictionary")
CoreBiGramTableDictionary = SafeJClass('com.hankcs.hanlp.dictionary.CoreBiGramTableDictionary')
ViterbiSegment = JClass('com.hankcs.hanlp.seg.Viterbi.ViterbiSegment')
MODEL_PATH = "123"
HanLP.Config.CoreDictionaryPath = MODEL_PATH + ".txt"
HanLP.Config.BiGramDictionaryPath = MODEL_PATH + ".ngram.txt"
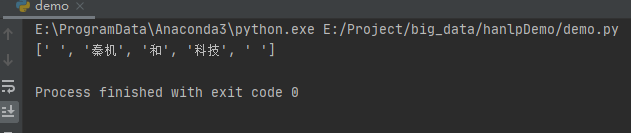
sent = "秦机和科技"
wordnet = build_wordnet(sent, CoreDictionary.trie)
print(viterbi(wordnet))
有的人可能有疑问,因为二元模型里,本身就存在秦机 和
科技这个样本。这么做不是多此一举吗?那好,我们替换sent的文本内容为“北京和广州”,这个样本可不在模型中。运行之后,效果如下:

我们发现依然能正确的分词为[北京 和 广州],这就是二元语法模型的泛化能力。至此我们走通了语料标注,训练模型,预测分词结果的完整步骤。
到此这篇关于Python预测分词的实现的文章就介绍到这了,更多相关Python预测分词内容请搜索软件开发网以前的文章或继续浏览下面的相关文章希望大家以后多多支持软件开发网!