Pandas数值排序sort_values()的使用
参数解释
DataFrame.sort_values(by,
axis=0,
ascending=True,
inplace=False,
kind='quicksort',
na_position='last', # last,first;默认是last
ignore_index=False,
key=None)
参数的具体解释为:
by:表示根据什么字段或者索引进行排序,可以是一个或多个
axis:排序是在横轴还是纵轴,默认是纵轴axis=0
ascending:排序结果是升序还是降序,默认是升序
inplace:表示排序的结果是直接在原数据上的就地修改还是生成新的DatFrame
kind:表示使用排序的算法,快排quicksort,,归并mergesort, 堆排序heapsort,稳定排序stable ,默认是 :快排quicksort
na_position:缺失值的位置处理,默认是最后,另一个选择是首位
ignore_index:新生成的数据帧的索引是否重排,默认False(采用原数据的索引)
key:排序之前使用的函数
数据值的排序主要使用sort_values(),数字按大小排序,字符按字母顺序
Series和DataFrame都支持此方法
import pandas as pd
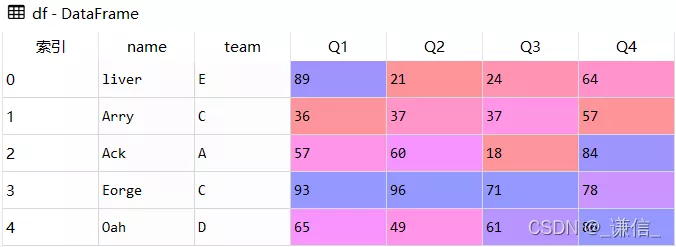
df = pd.DataFrame([['liver','E',89,21,24,64],
['Arry','C',36,37,37,57],
['Ack','A',57,60,18,84],
['Eorge','C',93,96,71,78],
['Oah','D',65,49,61,86]
],
columns = ['name','team','Q1','Q2','Q3','Q4'])
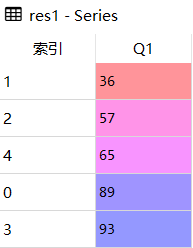
res1 = df.Q1.sort_values()
# DataFrame 需要传入一个或多个排序的列名
res2 = df.sort_values('Q4')
# 默认排序是升序,但可以指定排序方式
# 下例先按team升序排列,如遇到相同的team再按name降序排列
res3 = df.sort_values(by = ['team','name'], ascending = [True, False])
结果展示
df
res1
res2

res3

扩展
# 其他常用方法如下:
s.sort_values(ascending = False) # 降序
s.sort_values(inplace = True) # 修改生效
s.sort_values(na_position = 'first') # 空值在前
# df按指定字段排列
df.sort_values(by = ['team'])
df.sort_values('Q1')
# 按多个字段,先排team,在同team内再看Q1
df.sort_values(by = ['mean','Q1'])
# 全降序
df.sort_values(by = ['mean','Q1'], ascending = False)
# 对应指定team升Q1降
df.sort_values(by = ['mean','Q1'], ascending = [True, False])
到此这篇关于Pandas数值排序 sort_values()的使用的文章就介绍到这了,更多相关Pandas数值排序 sort_values()内容请搜索软件开发网以前的文章或继续浏览下面的相关文章希望大家以后多多支持软件开发网!