百度飞浆paddlepaddle之波士顿房价预测(二)


1.顺序读取
#reader示例
#实现文件的顺序读取、随机读取、批量读取
#读取文件的生成器函数,实则是采用闭包的形式
def reader_creator(file_path):
def reader():
with open(file_path) as f:
lines=f.readlines()
for line in lines:
yield line #生成一行数据
return reader
reader=reader_creator("test.txt")
for data in reader():
print(data,end="")
 2.随机读取
2.随机读取
#reader示例
#实现文件的顺序读取、随机读取、批量读取
import paddle
#读取文件的生成器函数,实则是采用闭包的形式
def reader_creator(file_path):
def reader():
with open(file_path) as f:
lines=f.readlines()
for line in lines:
yield line #生成一行数据
return reader
reader=reader_creator("test.txt")
shuffle_reader=paddle.reader.shuffle(reader,10) #随机读取
# for data in reader():
for data in shuffle_reader:
print(data,end="")
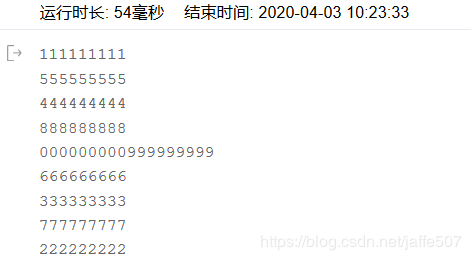
因为文件的0后面没有换行符 所以沾到以块去了,所以在文件的最后一行加上换行符就可以了
3.批量读取
#reader示例
#实现文件的顺序读取、随机读取、批量读取
import paddle
#读取文件的生成器函数,实则是采用闭包的形式
def reader_creator(file_path):
def reader():
with open(file_path) as f:
lines=f.readlines()
for line in lines:
yield line #生成一行数据
return reader
reader=reader_creator("test.txt")
shuffle_reader=paddle.reader.shuffle(reader,10) #随机读取
batch_reader=paddle.batch(shuffle_reader,3) #以批量读取,每个批次3笔
# for data in reader():
# for data in shuffle_reader:
for data in batch_reader():
print(data,end="")
 4.波士顿房价预测
4.波士顿房价预测
数据集一共有506笔数据,前13列为特征 最后一列(14)为价格中位数
一行一样本,一列一特征
#波士顿房价预测
import paddle
import paddle.fluid as fluid
import numpy as np
import os
import matplotlib.pyplot as mp
#1.准备数据
#直接使用paddle提供的uci_housing训练集、测试集
BUF_SIZE=500
BATCH_SIZE=20
#训练数据集
r_train=paddle.dataset.uci_housing.train() #训练集
random_reader=paddle.reader.shuffle(r_train,buf_size=BUF_SIZE) #每500打乱一次
train_reader=paddle.batch(random_reader,batch_size=BATCH_SIZE) #将随机读取器交给批量读取器
#测试集
r_test=paddle.dataset.uci_housing.test() #测试集
random_tester=paddle.reader.shuffle(r_test,buf_size=BUF_SIZE)
test_reader=paddle.batch(random_tester,batch_size=BATCH_SIZE)
train_data=paddle.dataset.uci_housing.train()
# for simple_data in train_data():
# print(simple_data)
'''
其中的两行
(array([-0.0405441 , 0.06636364, -0.32356227, -0.06916996, -0.03435197,
0.05563625, -0.03475696, 0.02682186, -0.37171335, -0.21419304,
-0.33569506, 0.10143217, -0.21172912]), array([24.]))
(array([-0.04030818, -0.11363636, -0.14907546, -0.06916996, -0.17632728,
0.02612869, 0.10633469, 0.1065807 , -0.32823509, -0.31724648,
-0.06973762, 0.10143217, -0.09693883]), array([21.6]))
'''
#2.搭建网络
#定义输入、输出
x=fluid.layers.data(name="x",shape=[13],dtype="float32")
y=fluid.layers.data(name="y",shape=[1],dtype="float32")
y_predict=fluid.layers.fc(input=x,
size=1,#输出值得个数
act=None )#激活函数
cost=fluid.layers.square_error_cost(input=y_predict, #预测值
label=y) #期望值
avg_cost=fluid.layers.mean(cost) #求平均损失值
optimizer=fluid.optimizer.SGD(learning_rate=0.001)
opts=optimizer.minimize(avg_cost) #通过优化器求均方差的最小值
#创建一个新的program用于测试
test_program=fluid.default_main_program().clone(for_test=True) #设置为True后会减少很多的优化动作
#3.模型的训练、评估、保存
place=fluid.CPUPlace()
exe=fluid.Executor(place)
exe.run(fluid.default_startup_program())
feeder=fluid.DataFeeder(place=place,feed_list=[x,y]) #生成器一批一批生成出来的 所以没采用字典的形式喂进去
iter=0
iters=[]#记录迭代次数 用于可视化
train_costs=[]#记录训练过程的损失值
for pass_id in range(120):
i=0
train_cost = 0
for data in train_reader():#从训练集读取器读取数据
i+=1
train_cost=exe.run(program=fluid.default_main_program(),
feed=feeder.feed(data),
fetch_list=[avg_cost] #取损失值
)
if i%20==0: #打印训练过程
print("pass_id:%d,cost:%0.5f"%(pass_id,train_cost[0][0]))
iter+=BATCH_SIZE
iters.append(iter)
train_costs.append(train_cost[0][0])
#模型保存
model_save_dir='model/housing.model' #模型保存路径
if not os.path.exists(model_save_dir):
os.makedirs(model_save_dir)
else:
fluid.io.save_inference_model(model_save_dir,
["x"],#输入数据的名称
[y_predict],
exe) #执行器
#可视化训练数据
mp.title('Training cost',fontsize=24)
mp.xlabel('iter',fontsize=14)
mp.ylabel('cost',fontsize=14)
mp.plot(iters,train_costs,color='red',label='Training cost')
#4.模型加载、预测
infer_exe=fluid.Executor(place) #用于预测的执行器
infer_result=[] #预测值的列表
ground_truths=[] #真实值的列表
#infer_program :预测的程序(包含了变量、计算规则、计算流程)
#feed_target_name:需要传入的变量
#fetch_targets:预测结构保存的变量
#load_inference_model:模型加载
[infer_program,feed_target_name,fetch_targets]=fluid.io.load_inference_model(
model_save_dir,#模型保存的路径
infer_exe) #要执行预测的执行器
infer_reader=paddle.batch(paddle.dataset.uci_housing.test(),
batch_size=200)#读取测试数据
test_data=next(infer_reader) #取可迭代对象的下一条数据
#将测试数据转换为数组
test_x=np.array(data[0] for data in test_data).astype("float32")
test_y=np.array(data[1] for data in test_data).astype("float32")
x_name=feed_target_name[0] #从加载模型取出输入参数的名称
result=infer_exe.run(infer_program,
feed={x_name:np.array(test_x)},
fetch_list=fetch_targets)
#预测完成后,记录预测值、实际值,用于可视化
for idx,val in enumerate(result[0]):
print("%d:%.2f"%(idx,val))#打印预测值
infer_result.append(val)
for idx,val in enumerate(test_y):#真实值
ground_truths.append(val)#记录真实值
#可视化
mp.figure("scatter",facecolor='lightgray')
mp.title("TestFigure",fontsize=24)
x=np.arange(1,30)
y=x
mp.plot(x,y)
mp.xlabel("ground truth" ,fontsize=14)
mp.ylabel("infer result" ,fontsize=14)
mp.scatter(ground_truths,infer_result,color='green',label='Test')
mp.grid(linestyle=":")
mp.show()
mp.savefig('predict.png')
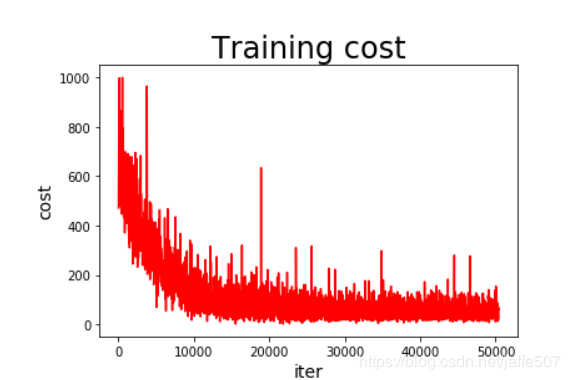
损失函数收敛过程
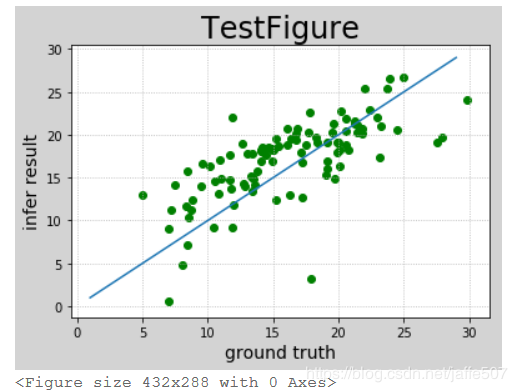
预测值与真实值对比
不用飞浆深度学习框架写,用决策树来预测波士顿房价
import sklearn.datasets as sd
import sklearn.utils as su
# 加载波士顿地区房价数据集
boston = sd.load_boston()
print(boston.feature_names)
# |CRIM|ZN|INDUS|CHAS|NOX|RM|AGE|DIS|RAD|TAX|PTRATIO|B|LSTAT|
# 犯罪率|住宅用地比例|商业用地比例|是否靠河|空气质量|房间数|年限|距中心区距离|路网密度|房产税|师生比|黑人比例|低地位人口比例|
# 打乱原始数据集的输入和输出
x, y = su.shuffle(boston.data, boston.target, random_state=7)
# 划分训练集和测试集
train_size = int(len(x) * 0.8)
train_x, test_x, train_y, test_y = \
x[:train_size], x[train_size:], \
y[:train_size], y[train_size:]
创建决策树回归器模型,使用训练集训练模型。使用测试集测试模型。
import sklearn.tree as st
import sklearn.metrics as sm
# 创建决策树回归模型
model = st.DecisionTreeRegressor(max_depth=4)
# 训练模型
model.fit(train_x, train_y)
# 测试模型
pred_test_y = model.predict(test_x)
print(sm.r2_score(test_y, pred_test_y))
=============
0.8202560889408635
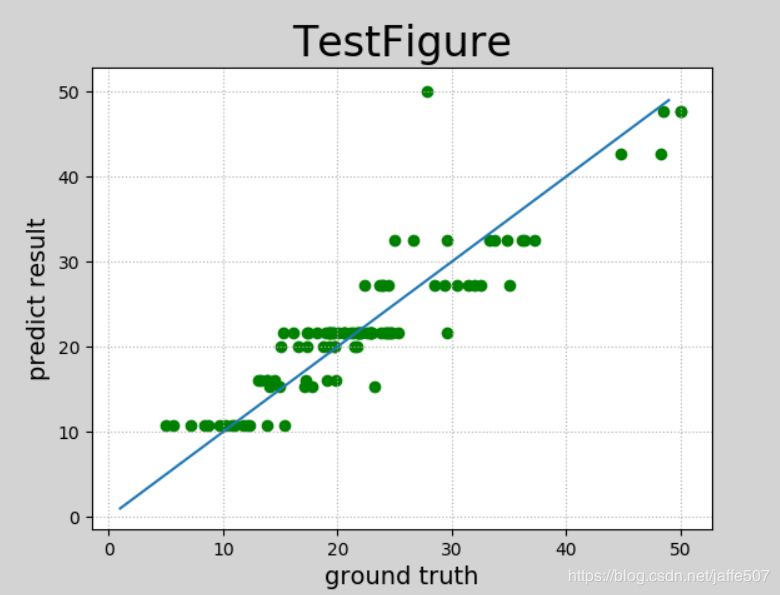
import numpy as np
import matplotlib.pyplot as mp
mp.figure("scatter",facecolor='lightgray')
mp.title("TestFigure",fontsize=24)
x=np.arange(1,50)
y=x
mp.plot(x,y)
mp.xlabel("ground truth" ,fontsize=14)
mp.ylabel("predict result" ,fontsize=14)
mp.scatter(test_y,pred_test_y,color='green',label='Test')
mp.grid(linestyle=":")
mp.show()
作者:Python数分与数挖