爬虫实战—爬取房天下全国所有的楼盘并入库(附源码)
1.创建项目
作者:半岛囚天
使用命令创建scrapy项目:scrapy startproject fang
进入到spiders文件中: cd fang/fang/spiders
创建爬虫文件:scrapy genspider sfw https://www.fang.com/SoufunFamily.htm
2.xpath解析页面,获取所需元素
快捷键“ctrl+shift+x”,调出xpath插件,通过xpath语法获取全国“省,市”
3.获取省和市
注意:当市有多行时,第二行开始就没有了省份,需要作出判断,为市添加对应的省份
class SwfSpider(scrapy.Spider):
name = 'swf'
allowed_domains = ['https://www.fang.com/SoufunFamily.htm']
start_urls = ['https://www.fang.com/SoufunFamily.htm']
def parse(self, response):
tr_list = response.xpath('//div[@id="c02"]//tr')
province_text = ''
# 去除国外的城市
for tr in tr_list[0:55]:
province = tr.xpath('./td[2]//text()').extract_first().strip('\xa0')
#给没有省份的市,添加省份
if province:
province_text = province
else:
province = province_text
a_list = tr.xpath('./td[3]/a')
#city_list = tr.xpath('./td[3]/a/text()').extract()
#for city in city_list:
# print(province, city)
4.找链接,拼接成新房的连接
北京的新房的URL:https://newhouse.fang.com/house/s/
合肥的新房的URL:https://hf.newhouse.fang.com/house/s/
芜湖的新房的URL:https://wuhu.newhouse.fang.com/house/s/
只有北京的URL不同,其他的城市都是:城市名+“.newhouse.fang.com/house/s/”,由此可以得出规律,在当前省市页面,解析获取市的路径,然后做拼接,获取市的新房的连接
创建Item对象,
class FangItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
province = scrapy.Field()
city = scrapy.Field()
name = scrapy.Field()
price = scrapy.Field()
for a in a_list:
city = a.xpath('./text()').extract_first()
if city == '北京':
url = 'https://newhouse.fang.com/house/s/'
else:
href = a.xpath('./@href').extract_first()
url = href.split('.')[0]
url = url + '.newhouse.fang.com/house/s/'
# url = 'https://tongling.newhouse.fang.com/house/s/b93/'
fang = FangItem(province=province,city=city)
yield scrapy.Request(url=url,
meta={'fang':fang,'url':url},
callback=self.parseSecond)

通过上面呢,已经找到了全国每个市的新房链接,接下来,通过这个新房的链接,进入该页面,然后解析页面,获取楼盘名和价格
先以北京为例:爬取第一页
def parseSecond(self,response):
fang = response.meta['fang']
#xpath解析的代码
#//div[@id="newhouse_loupai_list"]//div[@class="nlcd_name"]/a/text()
#//div[@id="newhouse_loupai_list"]//div[@class="nhouse_price"]/span/text()
div_list = response.xpath('//div[@id="newhouse_loupai_list"]//div[@class="nlc_details"]')
for div in div_list:
name = div.xpath('.//div[@class="nlcd_name"]/a/text()').extract_first().strip('\t\n')
# .xpath('string(.)')意思是将标签中子标签的文本进行拼接
# 他的调用者是seletor列表
price = price.xpath('string(.)').extract_first().strip('\t\n').strip('广告').strip('\t\n')
6.多页下载
北京的首页:https://newhouse.fang.com/house/s/
北京的第二页:https://newhouse.fang.com/house/s/b92/
北京的尾页:https://newhouse.fang.com/house/s/b932/
接下来爬取所有的网页,页码的规律就为:“b9”+当前页码数,第一页特殊
我们爬取的元素有四个:province city name price
在parse中,爬取:province city
在parceSecond中,爬取:name price
获取尾页数:
1.检查源码,解析,
2.注意有坑,当在中间的某一页时,会有两个class="last"标签,获取到的值为“首页”和“尾页”
# 尾页的href的值 last() 就是xpath中获取最后一个数据的方法
# href = response.xpath('//a[@class="last"][last()]/@href').extract_first()
3.获取到最后的页码时: /house/s/b932/
4.使用正则表达式提取页码32:
reg = '/b9(\d+)/' # /house/s/b932/
pattern = re.compile(reg)
当尾页获取到后:
1.在遍历之前,需要对页码数进行处理,第一次访问新房的页面时是第一页,URL是:https://newhouse.fang.com/house/s/,第二页之后是:https://newhouse.fang.com/house/s/b92/,当前页就为“b9”后面的数,下次访问就是第三页,为“b93”,所以为当前页+1,
2.遍历页码,拼接url,
url1 = response.meta['url']
for i in range(page,int(num)+1):
url = url1 + 'b9' + str(i) + '/'
yield scrapy.Request(url=url,callback=self.parseSecond,meta={'fang':fang,'url':url1})
break
7.打开管道,保存数据pymysql的使用:
1. conn 连接
1. 端口号必须是整型
2. 字符集不允许加-
2. cursor 游标
3. cursor.execute(sql)
4. conn.commit()
5. cursor.close()
6. conn.close()
8.最后获取到的数据
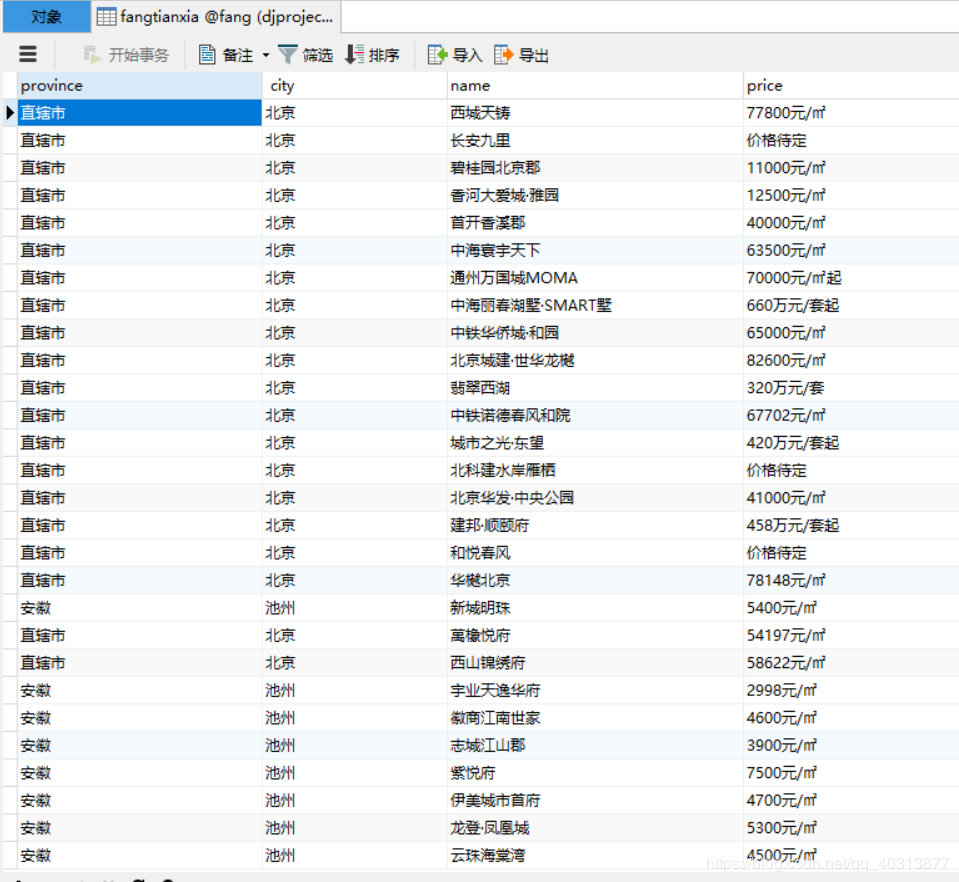
源码已放在github上:源码地址
作者:半岛囚天