Twitter推特爬虫工具开发
这篇博客将从头到尾展示关于如何实现推特爬虫。
由于推特其设置的请求频率较低且反爬力度较高,无法使用Scrapy来实现较高效率的爬取,因此选择用Selenium作为爬取模块来进行爬虫主体的构建。
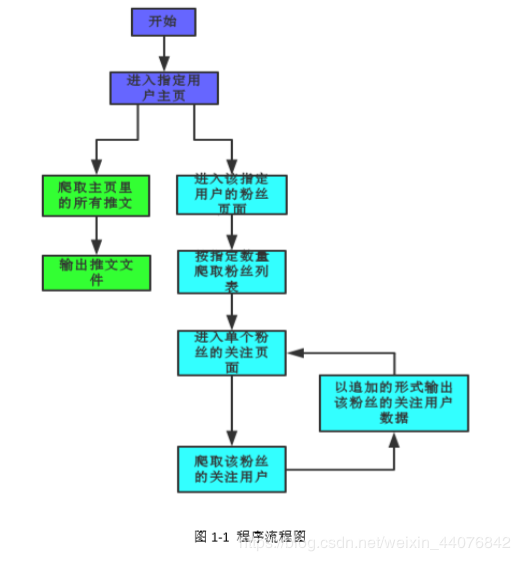
为方便理解,附上程序思路的流程图框架
在Selenium模块里内置了关于chrome的驱动器,因此在使用selenium驱动chrome之前需要安装对应版本的chromedriver。度娘一下即可获得。
以下是程序使用时所需要到的模块,以及驱动chrome的代码,采用无头浏览器则不会弹出浏览器(可于程序调试完成后使用),调试程序以普通的浏览器模式进行,易观察到bug的位置。
from selenium import webdriver
import time
import re
import numpy as np
from bs4 import BeautifulSoup as bs
import pandas as pd
import os
import csv
import random
import traceback
def Chrome_activate():#此部分是驱动chrome浏览器,采用的是无界面形式,最小化内存空间
option = webdriver.ChromeOptions()
option.add_argument('headless')#设置为无头浏览器模式
option.add_argument('--lang=zh-cn')#此句是为了让网页以中文的形式显示
browser = webdriver.Chrome(chrome_options=option)
# browser=webdriver.Chrome()
return browser
在启动浏览器之后,键入要访问的用户id名,进入该用户主页。
input_name = input("请输入爬取用户的id:(如爬取用户id为@KingJames,则输入:KingJames)")
user_url='https://www.twitter.com/'+input_name
#得到要首先访问的用户网址
用户登陆及验证
推特在访问用户主页时,非登陆状态下无法进行粉丝页和关注页的跳转,因此需要解决的第一个部分是自动登陆及验证。
下图为未登陆状态下访问推特用户主页的页面示意图:
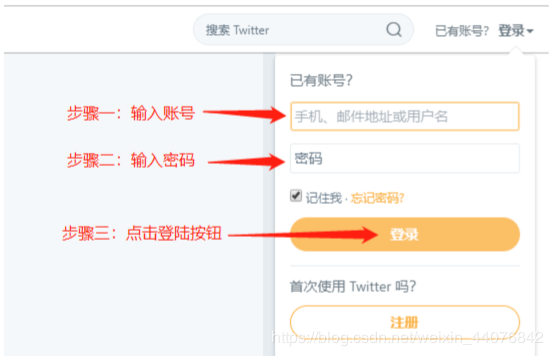
可以看到在登入到用户页面后,右上角会出现输入用户名及密码的橙色方框,找到其对应的网页Html元素的位置,将用户名及密码输入到对应的方框里,最后点击登陆即可。
详细步骤如下:
(1)在程序路径下创建一个存放账号密码以及验证手机号的txt文本,按照(账号,密码,验证手机号)的格式,在程序启动后随机抽取一个账号进行登陆
file_ac = (os.path.realpath(__file__))[:-12]
#由于找到的是该程序文件,但只需进入到该文件夹,因此需将xxx.py略去
account_password = file_ac + '账号密码.txt'#找到存放账号密码的txt文件
file_account = open(account_password)
lines = file_account.readlines()
user_2 = {}#存放密码
user_3 = {}#存放验证手机号
for line in lines:#把账号密码放进对应的字典里
user_list = line.split(',')
account = user_list[0]
password = user_list[1]
callnumber = user_list[2][:-1]
#将账号与密码及手机号以键值对的形式一一对应起来
user_2[account] = password
user_3[account] = callnumber
(2)随机抽取一个账号进行登陆
#随机选择一个账号进行登陆
login_account = random.sample(user_1.keys(), 1)
login_account = login_account[0]
login_password = user_2[login_account]
login_callnumber = user_3[login_account]
print("登陆账号为:{}".format(login_account))
print("登陆密码为:{}".format(login_password))
#找到账号和密码的输入栏,将账号与密码输入至方框内
user_id = browser.find_element_by_xpath('//input[@class="text-input email-input js-signin-email"]')#找到方框对应的位置
if user_id:
user_id.clear()#清楚掉方框里原有的内容
user_id.send_keys("{}".format(login_account))#将账号传入
else:
print("用户登录界面未显示")#可能存在账号密码方框未自动浮现的情况
time.sleep(3)
browser.close()
user_password = browser.find_element_by_xpath('//input[@class="text-input"]')
user_password.clear()
user_password.send_keys("{}".format(login_password))
#找到登陆的点击键
click = browser.find_element_by_xpath(
'//input[@class="EdgeButton EdgeButton--primary EdgeButton--medium submit js-submit"]')
click.click()
time.sleep(3)#需预留时间让网页进行加载。
(3)登陆完毕后,由于推特可能识别到IP地址的变化而转到验证手机号码的页面上,或者账号由于被识别到频繁请求而被禁止访问,因此需要对这两种情况进行识别,具体实现与登陆相同,即将验证手机号码键入即可。
if 'https://twitter.com/account/login_challenge' in browser.current_url:
print("该账号需进行身份验证,正在进行中")
call_number = browser.find_element_by_xpath('//input[@id="challenge_response"]')
call_number.send_keys(login_callnumber)
browser.find_element_by_xpath('//input[@id="email_challenge_submit"]').click()
time.sleep(2)
browser.get(url)
time.sleep(2)
if 'https://twitter.com/account/access' in browser.current_url:
print("该账号已被锁定,需要从存储文件中将其删除")
break
用户主页的推文爬取
在进行爬取之前,需要根据我们自身的需求去锁定页面里对应元素的位置所在,下图为推特新版用户页面的示意图:
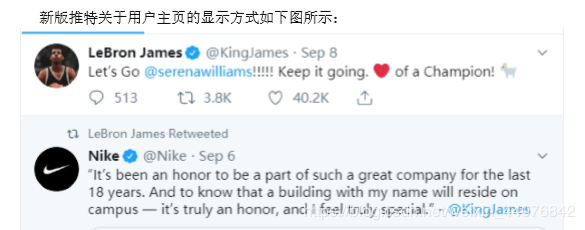 我们想要获得的是推文的发布者昵称、发布者id号、推文内容、发布时间、评论数、点赞数、转发数等。因此,需要在网页结构里找到这些元素的位置,实现爬取。
我们想要获得的是推文的发布者昵称、发布者id号、推文内容、发布时间、评论数、点赞数、转发数等。因此,需要在网页结构里找到这些元素的位置,实现爬取。
具体步骤如下:
(1)创建存储数据的文件
#首先是创建存储数据的文件
csv_path_1 = (file_path +'{}/'.format(input_name)+ '{}的推文数据.csv'.format(input_name))
with open(csv_path_1, 'w', newline='', encoding="utf_8_sig") as f:
writer = csv.writer(f)
head = ["用户id", "推文内容", "推文时间", "评论数", "转发数", "喜欢数", "链接"]
writer.writerow(head)
(2)模拟浏览器的向下滚动:
由于推特采用的是异步加载数据的形式来显示网页,而相对应的存储异步数据的链接无法获取,因此只能在selenium中对其进行向下滚动的操作从而使得数据得到不断地加载,直到页面尽头。
old_scroll_height = 0 #表明页面在最上端
js1 = 'return document.body.scrollHeight'#获取页面高度的javascript语句
js2 = 'window.scrollTo(0, document.body.scrollHeight)'#将页面下拉的Javascript语句
while (browser.execute_script(js1) > old_scroll_height):#将当前页面高度与上一次的页面高度进行对比
old_scroll_height = browser.execute_script(js1)#获取到当前页面高度
browser.execute_script(js2)#操控浏览器进行下拉
time.sleep(1.5)#空出加载的时间
通过一个while循环让浏览器执行javascript语句来不断下拉滚动,循环终止条件是页面高度不再发生变化。
(3)推文数据的爬取:
由于selenium模拟浏览器的过程中对内存的消耗过大,倘若等所有内容加载完毕后再进行数据的输出,可能在加载过程中便由于内存不足而出现页面崩溃的情况。
因此在推文数据的爬取过程中的规则是:每模拟下拉浏览器一次,便进行一次推文数据的输出,具体实现代码如下:
#由于转发、评论、点赞的爬取代码一样,故以函数方法表示
def count(crd):
if "千" in crd.text:
comment_number = int(float((crd.text)[:-1]) * 1000) # 将带有千字的数据转化为整数
elif "万" in crd.text:
comment_number = int(float((crd.text)[:-1]) * 10000) # 将带有万字的数据转化为整数
else: # 没有带千字或万字
if crd.text:
comment_number = int(crd.text)
else: # 若不存在数据,则设为0
comment_number = 0
return comment_number
content = bs(browser.page_source, 'html.parser')
#使用Beautifulsoup读取selenium获取到的网页内容
tw_user_1=content.find_all('article',re.compile('css-1dbjc4n r-1loqt21 r-1udh08x'))
#采用正则表达式re来实现用户推文的搜索,避免因为后续标签属性的改变而导致无法定位
print("已获取到{}条推文(可能有重复推文)".format(len(tw_user_1)))
#获取用户发布的推文数据
user_content=content.find_all('article',re.compile('css-1dbjc4n r-1loqt21 r-1udh08x'))#获取到当前加载的所有推文数据
for i in range(len(user_content)):#遍历所有数据
w_text=user_content[i].find('div',re.compile('r-a023e6 r-16dba41 r-ad9z0x r-bcqeeo r-bnwqim r-qvutc0'))
#获取到当前推文的内容
if w_text:#判断是否有推文内容,因为存在转推的情况
tw_text=w_text.text
else:
tw_text='该推文无文字内容(编号:{})'.format(m)
m=m+1
if tw_text not in tw_list:#可能存在同一推文被再次爬取,因此需要判断。
tw_number = tw_number + 1
tw_list.append(tw_text)
tw_data['user']=user_content[i].find('div','css-1dbjc4n r-18u37iz r-1wbh5a2 r-1f6r7vd').text#获取推特用户id
tw_data['text']=tw_text.rstrip()
#获取评论数,转发数,点赞数
crd=user_content[i].find_all('div','css-1dbjc4n r-1iusvr4 r-18u37iz r-16y2uox r-1h0z5md')
#定位到评论数,点赞数,转发数所在的标签
comment_number=count(crd[0])
tw_data['comment'] = comment_number
return_number=count(crd[1])
tw_data['return'] = return_number
like_number=count(crd[2])
tw_data['like'] = like_number
tw_data['time'] = user_content[i].find('time')['datetime'][:-5]#推文时间
tw_data['href']= 'http://twitter.com/'+user_content[i].find('a',
'css-4rbku5 css-18t94o4 css-901oao r-1re7ezh r-1loqt21'
' r-1q142lx r-1qd0xha r-a023e6 r-16dba41 r-ad9z0x r-bcqeeo r-3s2u2q r-qvutc0')['href']
#将每一次循环爬取到的数据以追加的方式写入已经创建好的csv文件中
tw_data.to_csv(file_path + '\\{}'.format(input_name) + '\\{}的推文数据.csv'.format(input_name), mode='a',
header=False, index=False, encoding="utf_8_sig")
else:
continue
至此,完成对推特指定用户主页的推文爬取过程!
指定用户的粉丝关注爬取接下来对指定用户的粉丝关注进行爬取。
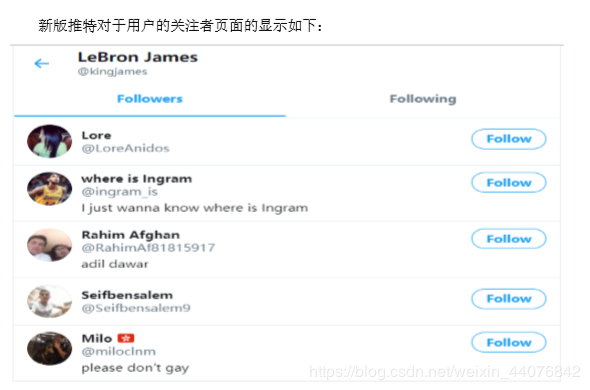
需要获得的内容是用户的昵称,id,以及用户自我简介
具体步骤如下:
(1)创建存储数据的文件,与上一部分的代码无异,修改生成的文件名以及列名即可
def follower_crawl(panduan_2,browser,url,run_number,second_href_list=0):#跳转到关注者界面,开始进行爬取
#panduan_2:判断是否达到指定的爬取数量,达到则跳出循环
#browser:为selenium的浏览器
#run_number:为运行的次数,用来区分是否是已重启过的
#second_href_list:传入需爬取的用户链接列表
if run_number==0:#一旦出现异常后,无需再重新创建新的文件,也无需进行关注用户的数目的重新爬取
csv_path = (file_path + '{}/'.format(input_name)+'{}的关注者.csv'.format(input_name))
with open(csv_path, 'w', newline='', encoding="utf_8_sig") as f:
writer = csv.writer(f)
head = ["用户id","用户说明"]
writer.writerow(head)
(2)获得该用户的粉丝
url=url+'/followers'#在原本用户主页的尾部加上/followers进入关注者界面
browser.get(url)#从主页跳转到关注者的页面
time.sleep(3)
global name_list
#定义全局变量,用来记录当下总共爬取到的粉丝数量,可用于指定粉丝数量后停止循环
name_list=0
old_scroll_height = 0
href_list=[]
namelist=[]#用于判断用户是否已经被爬取,实现去重的功能
while(browser.execute_script(js1) > old_scroll_height):#模拟浏览器进行滚动下拉
if name_list>=int(panduan_2):#判断是否达到指定的爬取数量,达到则跳出循环
print("{}名关注者爬取完毕".format(str(panduan_2)))
break
old_scroll_height = browser.execute_script(js1)
browser.execute_script(js2)
time.sleep(2.5)
content=bs(browser.page_source,'html.parser')#解析网页
all_followers=content.find_all('div','css-1dbjc4n r-1iusvr4 r-46vdb2 r-1777fci r-5f2r5o r-bcqeeo')#找到所有用户数据
user_data=pd.DataFrame(data=np.zeros(shape=(1,2)),columns=['id','introduction'])#创建存储数据的Dataframe
id_text=i.find('div','css-901oao css-bfa6kz r-1re7ezh r-18u37iz r-1qd0xha'
' r-a023e6 r-16dba41 r-ad9z0x r-bcqeeo r-qvutc0')
if id_text:#存在用户将主页锁定的情况,导致无法获取到id,因此需要进行判断
id_text_i=id_text.text
if id_text.text not in namelist:#实现去重的判断语句
user_data['id'] = id_text_i
name_list = name_list + 1 # 统计当下爬取到的用户数量
introduction = i.find('div', 'css-901oao r-hkyrab r-1qd0xha r-a023e6 r-16dba41'
' r-ad9z0x r-bcqeeo r-glunga r-1jeg54m r-qvutc0')
if introduction: # 爬取用户简介
user_data['introduction'] = introduction.text
else:
user_data['introduction'] = ''
#将数据导出
user_data.to_csv(file_path + '\\{}'.format(input_name) + "\\{}的关注者.csv".format(input_name),
mode='a',
header=False, index=False, encoding="utf_8_sig")
href_list.append('http://twitter.com/' + id_text_i[1:])#将用户主页统计起来,用于下一步关于用户的关注爬取
namelist.append(id_text_i)#将已经爬取好的用户加入到列表中
else:
continue
(3)在获取到指定数量的粉丝后,对每个粉丝的关注页面也进行爬取,得到其关注喜好
同样是创建对应的文件进行存储
#爬取关注者的信息,即用户的关注喜好
if run_number==0:#若是第一次,则需要创建文件
second_csv_path=(file_path+ '{}/'.format(input_name)+'{}关注者的信息.csv'.format(input_name))
with open(second_csv_path, 'w',newline='',encoding="utf_8_sig") as f:
writer = csv.writer(f)
head = ["{}的关注者id".format(input_name),"该关注者关注的其他用户id",]
writer.writerow(head)
对每个粉丝进行单独的爬取,以下部分在后续实现程序重复运行时可以定义为一个函数体,使过程更为简洁清晰
for i in range(len(href_list)):#循环遍历粉丝列表
print("开始爬取第{}个关注者的关注信息".format(str(i+1)))
second_name_list = []
browser.get(href_list[i])#进入该粉丝的主页
time.sleep(2)
fnumber=browser.find_elements_by_xpath('//a[@class="css-4rbku5 css-18t94o4 css-901oao r-hkyrab'
' r-1loqt21 r-1qd0xha r-a023e6 r-16dba41 r-ad9z0x '
'r-bcqeeo r-qvutc0"]')
#获取到该粉丝的关注量,超500的不予爬取,可能为僵尸推特,无实际爬取意义
if fnumber:
if fnumber[0].text:
following_number = fnumber[0].get_attribute('title')
print("该用户关注量为:{}".format(following_number))
else:
following_number = 0
print("该用户关注量为:{}".format(following_number))
else:
print("该用户的Id已更新,无法访问")
continue
if len(following_number)>=4 or int(following_number)>500:
#len(...)>4是因为可能存在关注为0的情况,页面上不会出现关注字样
print("用户关注数量超过500,不进行爬取")
continue
else:
second_head_name = browser.find_element_by_xpath('//div[@class="css-901oao css-bfa6kz r-1re7ezh r-18u37iz'
' r-1qd0xha r-a023e6 r-16dba41 r-ad9z0x r-bcqeeo r-qvutc0"]').text
second_data = pd.DataFrame(data=np.zeros(shape=(1, 2)), columns=['head_name', 'id'])
second_data['head_name'] = second_head_name
second_data['id'] = input_name
second_name_list.append(input_name)
second_data.to_csv(
file_path + '\\{}'.format(input_name) + "\\{}关注者的信息.csv".format(input_name),
mode='a', header=False, index=False, encoding="utf_8_sig")
#获取到该粉丝的id
url=href_list[i]+'/following'
browser.get(url)#进入该粉丝的关注页面
time.sleep(2)
.........
注:接下来的程序部分也是实现滚动下拉去获得该粉丝所有的关注用户,因此代码与前面无异。因此在这儿不进行重复说明
至此,爬虫功能的实现部分已基本完成~
程序的异常重启但由于使用selenium的过程中容易受到其他因素的干扰,如页面崩溃、网络状态不佳、内存不足的情况,会导致程序的突然中断,无法达到爬取要求。程序需要在遇到异常的时候从未完成的爬取位置重新开始爬取。
具体实现方式是借助在Try…Except语句的基础上加多一个while循环,实现异常后的重处理。代码如下:
由于报错位置基本出现在爬取粉丝喜好的过程中,因此异常处理不针对爬取推文的功能
while True:
try:#由于崩溃报错的位置基本出现在爬取粉丝关注喜好的时候,因此爬取推文部分未放进此循环中
if panduan_1=='y':
if run_number==0:#第一次正常爬取
follower_crawl(panduan_2,browser,url,run_number)
#第一次爬取无需更改其他参数。
elif run_number>0:#产生异常后
refile=open(file_path + '\\{}'.format(input_name) + "\\{}关注者的信息.csv".format(input_name),
encoding="utf_8_sig")#
redata=pd.read_csv(refile)#读取已爬到的数据
last_user=redata.iloc[-1,0]#锁定上次报错时的爬取位置
print("中断前爬取的用户为:{}".format(last_user))#找到最后一个用户id
#将未进行爬取的用户id写进一个列表中
renew_f = open(file_path + '\\{}'.format(input_name) + "\\{}的关注者.csv".format(input_name),
encoding="utf_8_sig")
renew_data = pd.read_csv(renew_f)
for i in range(len(renew_data)):#搜索最后一个已爬取用户的位置
if last_user == renew_data['用户id'][i]:
renew_href = renew_data.iloc[i:,0]#得到未进行爬取的用户id
else:
continue
second_href_list = []#重新构造出一个新的用户链接列表
renew_href=renew_href.reset_index(drop=True)
for i in range(len(renew_href)):
second_href = 'https://twitter.com/' + renew_href[i][1:]
second_href_list.append(second_href)
#将未爬取的用户链接加入到列表里
follower_crawl(panduan_2,browser,url,run_number,last_user,second_href_list)
#再次调用粉丝爬取函数
except Exception as e:#若产生异常
run_number=run_number+1 #用于判断是否是异常后的再次爬取请求
print("产生异常,重新爬取,异常原因为:{}".format(traceback.print_exc()))#打印出报错位置,原因
browser.close()#关闭浏览器
browser = Chrome_activate()#重新打开浏览器
time.sleep(2)
continue
else:
#当程序满足指定条件后退出。
print("程序运行正常,结束爬取")
break
以上即为推特指定用户及其粉丝、粉丝的关注喜好爬取功能的实现代码。
程序工具化为方便后续直接使用,将其封装为一个exe文件,但未进行操作界面的优化。封装时使用的是Pyinstaller模块。
作者:你在天堂遇到的五个人