JS实现单个或多个文件批量下载的方法详解
前言
单个文件Download
方案一:location.href or window.open
方案二:通过a标签的download属性
方案三:API请求
多个文件批量Download
方案一:按单个文件download方式,循环依次下载
方案二:前端打包成zip download
方案三:后端压缩成zip,然后以文件流url形式,前端调用download
总结
前言在前端Web开发中,下载文件是一个很常见的需求,也有一些比较特殊的Case,比如下载文件请求是一个POST、url不是同源的、批量下载文件等。本文就介绍下几种download解决方案,以及特殊Case的最佳方案选择。
单个文件Download 方案一:location.href or window.open<a href={url} target="_blank">download</a>
window.location.href = url; // 当前tab
window.open(url); // 新tab
缺点:
1.只支持get请求,不支持post请求。
2.浏览器会根据header的content-type来判断是下载文件还是预览文件。
比如 txt png 等格式文件,会在当前tab或新tab中预览,而不是下载下来。
3.由于只支持get,会有url参数过长问题。
4.不能加request header,无法做权限验证等逻辑。
5.不支持自定义file name。
方案二:通过a标签的download属性通过HTML a标签的原生属性,使用浏览器下载。
https://developer.mozilla.org/zh-CN/docs/Web/HTML/Element/a#attr-download
<a href={url} download={fileName}>download</a>
function downloadFile(url, fileName) {
const a = document.createElement('a');
a.style.display = 'none';
a.href = url;
a.download = fileName;
document.body.appendChild(a);
a.click();
document.body.removeChild(a);
}
优点:
都是走的浏览器下载文件逻辑,不会预览文件。
当前tab打开方式下载。
支持设置file name。
缺点:
只支持get请求,不支持post请求。
不能加request header,无法做权限验证等逻辑。
不支持跨域地址。
方案三:API请求API发送请求的方式,获取文件blog对象,然后通过URL.createObjectURL方法获取download url,然后用方案二的<a download />方式下载。
// 封装一个fetch download方法
async function fetchDownload(fetchUrl, method = "POST", body = null) {
const response = await window.fetch(fetchUrl, {
method,
body: body ? JSON.stringify(body) : null,
headers: {
"Accept": "application/json",
"Content-Type": "application/json",
"X-Requested-With": "XMLHttpRequest",
},
});
const fileName = getFileName(response);
const blob = await response.blob();
const url = URL.createObjectURL(blob);
return { blob, url, fileName }; // 返回blob、download url、fileName
}
// 根据response header获取文件名
function getFileName(response) {
const disposition = response.headers.get('Content-Disposition');
// 本例格式是:"attachment; filename="img.jpg""
let fileName = disposition.split('filename=')[1].replaceAll('"', '');
// 可以根据自己的格式来截取文件名
// 参考https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Headers/Content-Disposition
// let fileName = '';
// if (disposition && disposition.indexOf('attachment') !== -1) {
// const matches = /filename[^;=\n]*=((['"]).*?\2|[^;\n]*)/.exec(disposition);
// fileName = matches?.[1]?.replace(/['"]/g, '');
// }
fileName = decodeURIComponent(fileName);
return fileName;
}
// 页面里调用
// get
fetchDownload('/api/get/file?name=img.jpg', 'GET').then(({ blob, url, fileName }) => {
downloadFile(url, fileName); // 调用方案二的download方法
});
// post
fetchDownload('/api/post/file', 'POST', { name: 'img.jpg' }).then(({ blob, url, fileName }) => {
downloadFile(url, fileName);
});
URL.createObjectURL 生成的url如果过多会有效率问题,可以在合适的时机(download后)释放掉。参考:developer.mozilla.org/zh-CN/docs/…
if (window.URL) {
window.URL.revokeObjectURL(url);
} else {
window.webkitURL.revokeObjectURL(url);
}
优点:
因为最后用的是方案二,所以满足方案二的优点。
支持post请求、支持跨域(fetch本身支持)。
可以加request header。
缺点:
低版本浏览器不支持,可以通过'download' in document.createElement('a')判断是否支持。
浏览器兼容可能有问题,比如Safari、IOS Safari。
多个文件批量Download有些需求是,点一个按钮需要把多个文件同时download下来,有以下几个方案可以实现。
方案一:按单个文件download方式,循环依次下载downloadFile("/files/file1.txt", "file1.txt");
downloadFile("/files/word1.docx", "word1.docx");
downloadFile("/files/img1.jpg", "img1.jpg");
利用上面的方案二的<a download />方式下载,会触发浏览器是Download multiple files提示,如果选了Allow则会正常下载。
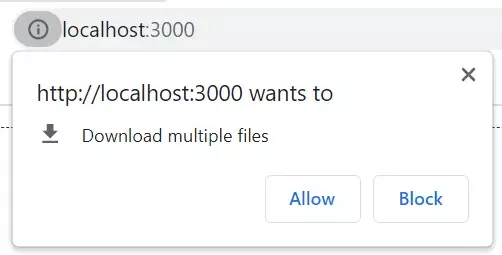
尝试每个download之间加延迟,依然会弹提示。这个应该是浏览器机制问题了,没办法避免了。
方案二:前端打包成zip download前端可以通过一个第三方库 jszip,可以把多个文件以blob、base64或纯文本等形式,按自定义的文件结构,压缩成一个zip文件,然后通过浏览器download下来。
官网:stuk.github.io/jszip/ 用法不难,直接看code:
// 先封装一个方法,请求返回文件blob
async function fetchBlob(fetchUrl, method = "POST", body = null) {
const response = await window.fetch(fetchUrl, {
method,
body: body ? JSON.stringify(body) : null,
headers: {
"Accept": "application/json",
"Content-Type": "application/json",
"X-Requested-With": "XMLHttpRequest",
},
});
const blob = await response.blob();
return blob;
}
const zip = new JSZip();
zip.file("Hello.txt", "Hello World\n"); // 支持纯文本等
zip.file("img1.jpg", fetchBlob('/api/get/file?name=img.jpg', 'GET')); // 支持Promise类型,需要返回数据类型是 String, Blob, ArrayBuffer, etc
zip.file("img2.jpg", fetchBlob('/api/post/file', 'POST', { name: 'img.jpg' })); // 同样支持post请求,只要返回类型正确就行
const folder1 = zip.folder("folder01"); // 创建folder
folder1.file("img3.jpg", fetchBlob('/api/get/file?name=img.jpg', 'GET')); // folder里创建文件
zip.generateAsync({ type: "blob" }).then(blob => {
const url = window.URL.createObjectURL(blob);
downloadFile(url, "test.zip");
});

jszip还支持一些别的类型文件压缩,比如纯文本、base64、binary等等,详见:https://stuk.github.io/jszip/documentation/api_jszip/file_data.html
由于走的是纯前端压缩,所以会有延迟问题,走到最后download时才会调起浏览器下载,所以页面可能需要一个效果来更新压缩进度。zip.generateAsync方法就支持第二个参数,支持进度更新:
zip.generateAsync({ type: "blob" }, metadata => {
const progress = metadata.percent.toFixed(2); // 保留2位小数
console.log(metadata.currentFile, "progress: " + progress + " %");
}).then(blob => ... );
方案三:后端压缩成zip,然后以文件流url形式,前端调用download
后台加个api,然后把需要download的文件在后台压缩成zip,然后把文件流输出出来。然后就和单个文件download一样了。
因为后台会先压缩,会有延迟才会把blob返回前台,而且需要传多个文件信息,一般是post请求,所以建议使用单个文件下载的方案三通过API请求实现,在请求前后加上提示语或loading效果。
总结本文介绍了前端单个文件的下载方案,以及批量多个文件下载的解决方案。最后整理下方案建议:
单个文件下载:
如果url是同源的,并且是一个服务器上的静态文件路径、或者是一个get请求,推荐方案二即 <a download />方式下载。
反之,方案三即API请求方式。
批量文件下载:
如果有zip压缩需求,选方案二或方案三;
如果可以接受弹Download multiple files提示,用方案一;反之方案二或方案三;
以上就是JS实现单个或多个文件批量下载的方法详解的详细内容,更多关于JS文件批量下载的资料请关注软件开发网其它相关文章!