knn分类iris数据
knn分类iris数据
题目
作者:龙晨天
Sklearn中的datasets方法导入iris鸢尾花训练样本并用train_test_split产生测试样本,用KNN分类并输出分类精度。
data = sklearn.datasets.iris.data
label = sklearn.datasets.iris.target
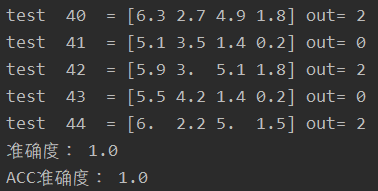
输出
代码
from sklearn import datasets
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
#导入数据集
iris=datasets.load_iris()
data = iris.data
label = iris.target
#x1,x2,y1,y2=train_test_split(data,label,test_size=0.3)
#train_test_split函数用于将矩阵随机划分为训练子集和测试子集,并返回划分好的训练集测试集样本和训练集测试集标签。
#X_train,X_test, y_train, y_testcross_validation.train_test_split(train_data,train_target,test_size=0.3, random_state=0)
#test_size:如果是浮点数,在0-1之间,表示样本占比;如果是整数的话就是样本的数量
##划分数据集
x1,x2,y1,y2=train_test_split(data,label,test_size=0.3)
clf = KNeighborsClassifier(n_neighbors=15)
#训练
clf.fit(x1, y1)
#预测
x3=clf.predict(x2)
k=0
for i in range(len(x2)):
print("test ",i," =",x2[i],"out=",y2[i])
if x3[i]==y2[i]:
k=k+1
#求分类精度
ACC=accuracy_score(y2,x3)
print("准确度:",(k/len(y2)))
print("ACC准确度:",
作者:龙晨天