速看,三分钟带你了解IP协议!
我的目的非常简单,就是和大家一起进步,无论啥时候,我们都会觉得需要学习的知识太多了,而且还时不时感觉自己啥都不会!你说扎心不,好了。废话不多说,直接进入正题。
首先电信网的成功经验让网络负责可靠交付
面向连接的通信方式 建立虚电路(Virtual Circuit),以保证双方通信所需的一切网络资源。 如果再使用可靠传输的网络协议,就可使所发送的分组无差错按序到达终点。在了解IP协议之前先带你了解一些基础知识。 1.一些基础知识 1.1虚电路是逻辑连接
虚电路表示这只是一条逻辑上的连接,分组都沿着这条逻辑连接按照存储转发方式传送,而并不是真正建立了一条物理连接。
请注意,电路交换的电话通信是先建立了一条真正的连接。因此分组交换的虚连接和电路交换的连接只是类似,但并不完全一样
1.2因特网采用的设计思路 网络层向上只提供简单灵活的、无连接的、尽最大努力交付的数据报服务。 网络在发送分组时不需要先建立连接。每一个分组(即 IP 数据报)独立发送,与其前后的分组无关(不进行编号)。 网络层不提供服务质量的承诺。即所传送的分组可能出错、丢失、重复和失序(不按序到达终点),当然也不保证分组传送的时限。 1.3尽最大努力交付的好处 由于传输网络不提供端到端的可靠传输服务,这就使网络中的路由器可以做得比较简单,而且价格低廉(与电信网的交换机相比较)。 如果主机(即端系统)中的进程之间的通信需要是可靠的,那么就由网络的主机中的运输层负责(包括差错处理、流量控制等)。 采用这种设计思路的好处是:网络的造价大大降低,运行方式灵活,能够适应多种应用。 因特网能够发展到今日的规模,充分证明了当初采用这种设计思路的正确性。 1.4虚电路服务与数据报服务的对比| 对比的方面 | 虚电路服务 | 数据报服务 |
|---|---|---|
| 思路 | 可靠通信应当由网络来保证 | 可靠通信应当由用户主机来保证 |
| 连接的建立 | 必须有 | 不需要 |
| 终点地址 | 仅在连接建立阶段使用,每个分组使用短的虚电路号 | 每个分组都有终点的完整地址 |
| 分组的转发 | 属于同一条虚电路的分组均按照同一路由进行转发 | 每个分组独立选择路由进行转发 |
| 当结点出故障时 | 所有通过出故障的结点的虚电路均不能工作 | 出故障的结点可能会丢失分组,一些路由可能会发生变化 |
| 分组的顺序 | 总是按发送顺序到达终点 | 到达终点时不一定按发送顺序 |
| 端到端的差错处理和流量控制 | 可以由网络负责,也可以由用户主机负责 | 由用户主机负责 |
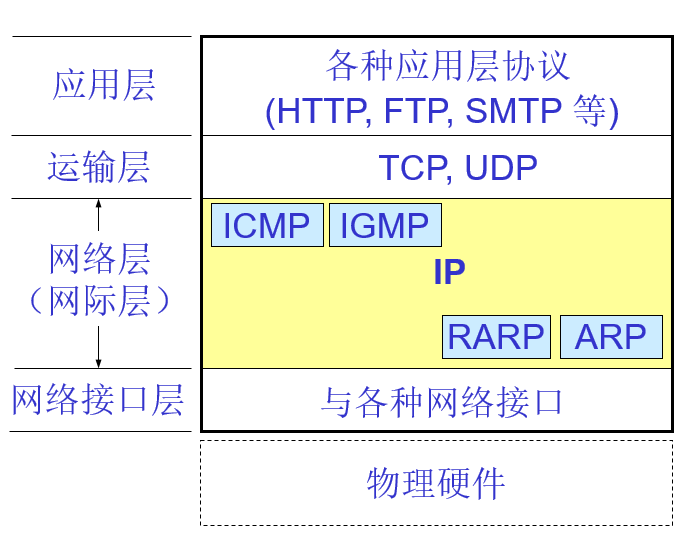
互连在一起的网络要进行通信,会遇到许多问题需要解决,如:
不同的寻址方案 不同的最大分组长度 不同的网络接入机制 不同的超时控制 不同的差错恢复方法 不同的状态报告方法 不同的路由选择技术 不同的用户接入控制 不同的服务(面向连接服务和无连接服务) 不同的管理与控制方式 1.8 网络互相连接起来需要的中间设备| 中间设备又称为中间系统或中继(relay)系统。 | |
|---|---|
| 物理层中继系统 | 转发器(repeater)。 |
| 数据链路层中继系统 | 网桥或桥接器(bridge)。 |
| 网络层中继系统 | 路由器(router)。 |
| 网桥和路由器的混合物 | 桥路器(brouter)。 |
| 网络层以上的中继系统 | 网关(gateway)。 |
我们把整个因特网看成为一个单一的、抽象的网络。IP 地址就是给每个连接在因特网上的主机(或路由器)分配一个在全世界范围是唯一的 32 位的标识符。
IP 地址现在由因特网名字与号码指派公司ICANN (Internet Corporation for Assigned Names and Numbers)进行分配
2.1.2 IP 地址的编址方法分类的 IP 地址。这是最基本的编址方法,在 1981 年就通过了相应的标准协议。
子网的划分。这是对最基本的编址方法的改进,其标准[RFC 950]在 1985 年通过。
构成超网。这是比较新的无分类编址方法。1993 年提出后很快就得到推广应用。
2.1.3 分类 IP 地址每一类地址都由两个固定长度的字段组成,其中一个字段是网络号 net-id,它标志主机(或路由器)所连接到的网络,而另一个字段则是主机号 host-id,它标志该主机(或路由器)。
2.1.4点分十进制记法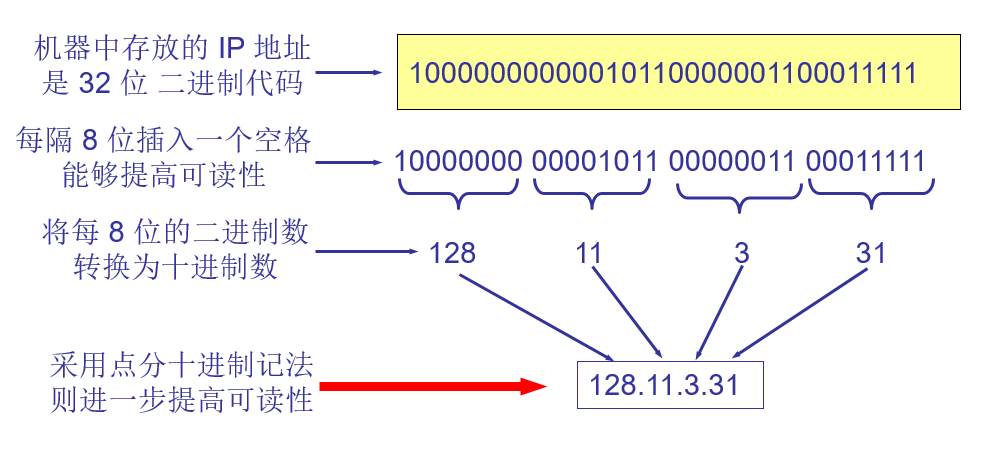

(1) IP 地址是一种分等级的地址结构。
分两个等级的好处是:
第一,IP 地址管理机构在分配 IP 地址时只分配网络号,而剩下的主机号则由得到该网络号的单位自行分配。这样就方便了 IP 地址的管理。 第二,路由器仅根据目的主机所连接的网络号来转发分组(而不考虑目的主机号),这样就可以使路由表中的项目数大幅度减少,从而减小了路由表所占的存储空间。(2) 实际上 IP 地址是标志一个主机(或路由器)和一条链路的接口。
当一个主机同时连接到两个网络上时,该主机就必须同时具有两个相应的 IP 地址,其网络号 net-id 必须是不同的。这种主机称为多归属主机(multihomed host)。 由于一个路由器至少应当连接到两个网络(这样它才能将 IP 数据报从一个网络转发到另一个网络),因此一个路由器至少应当有两个不同的 IP 地址。(3) 用转发器或网桥连接起来的若干个局域网仍为一个网络,因此这些局域网都具有同样的网络号 net-id。
(4) 所有分配到网络号 net-id 的网络,范围很小的局域网,还是可能覆盖很大地理范围的广域网,都是平等的。
(5)在同一个局域网上的主机或路由器的IP 地址中的网络号必须是一样的。
(6)路由器总是具有两个或两个以上的 IP 地址。路由器的每一个接口都有一个不同网络号的 IP 地址。
2.3 IP地址与硬件地址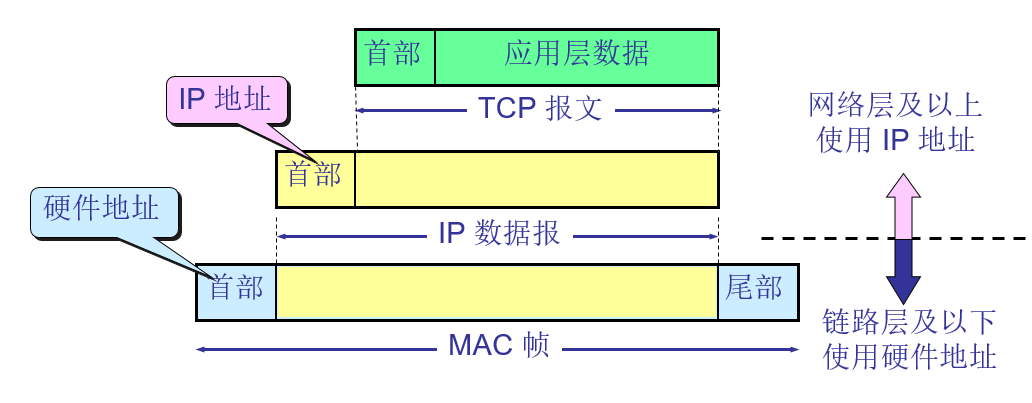
在具体的物理网络的链路层只能看见 MAC 帧而看不见 IP 数据报
IP层抽象的互联网屏蔽了下层很复杂的细节,在抽象的网络层上讨论问题,就能够使用统一的、抽象的 IP 地址研究主机和主机或主机和路由器之间的通信
2.4 地址解析协议 ARP 和 逆地址解析协议 RARP 2.4.1 地址解析协议 ARP不管网络层使用的是什么协议,在实际网络的链路上传送数据帧时,最终还是必须使用硬件地址。
每一个主机都设有一个 ARP 高速缓存(ARP cache),里面有所在的局域网上的各主机和路由器的 IP 地址到硬件地址的映射表。
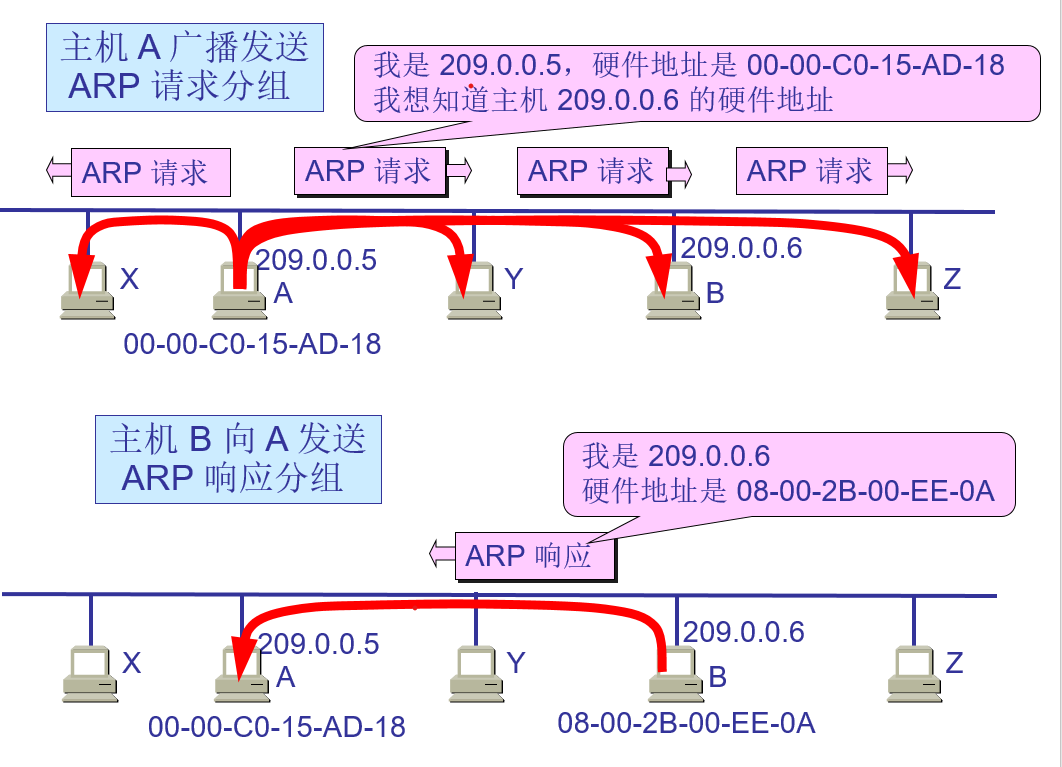
由于全世界存在着各式各样的网络,它们使用不同的硬件地址。要使这些异构网络能够互相通信就必须进行非常复杂的硬件地址转换工作,因此几乎是不可能的事。
连接到因特网的主机都拥有统一的 IP 地址,它们之间的通信就像连接在同一个网络上那样简单方便,因为调用 ARP 来寻找某个路由器或主机的硬件地址都是由计算机软件自动进行的,对用户来说是看不见这种调用过程的。
2.4.5 逆地址解析协议 RARP 逆地址解析协议 RARP 使只知道自己硬件地址的主机能够知道其 IP 地址。 这种主机往往是无盘工作站。 因此 RARP协议目前已很少使用。 2.5 IP数据报的格式 一个 IP 数据报由首部和数据两部分组成。 首部的前一部分是固定长度,共 20 字节,是所有 IP 数据报必须具有的。 在首部的固定部分的后面是一些可选字段,其长度是可变的。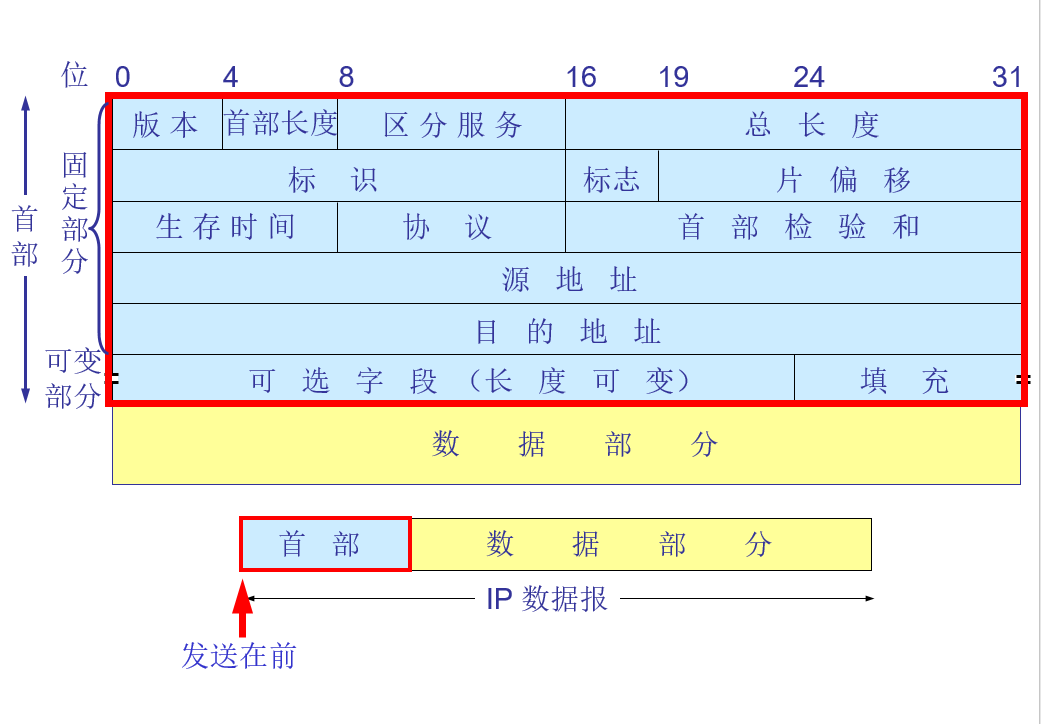
版本——占 4 位,指 IP 协议的版本,目前的 IP 协议版本号为 4 (即 IPv4)
首部长度——占 4 位,可表示的最大数值是 15 个单位(一个单位为 4 字节)因此 IP 的首部长度的最大值是 60 字节
区分服务——占 8 位,用来获得更好的服务,在旧标准中叫做服务类型,但实际上一直未被使用过。1998 年这个字段改名为区分服务。只有在使用区分服务(DiffServ)时,这个字段才起作用。在一般的情况下都不使用这个字段 。
总长度——占 16 位,指首部和数据之和的长度,单位为字节,因此数据报的最大长度为 65535 字节。总长度必须不超过最大传送单元 MTU。
标识(identification) 占 16 位,它是一个计数器,用来产生数据报的标识。
标志(flag) 占 3 位,目前只有前两位有意义。
标志字段的最低位是 MF (More Fragment)。MF = 1 表示后面“还有分片”。MF = 0 表示最后一个分片。
标志字段中间的一位是 DF (Don’t Fragment) 。只有当 DF = 0 时才允许分片。
片偏移(12 位)指出:较长的分组在分片后,某片在原分组中的相对位置。片偏移以 8 个字节为偏移单位
生存时间(8 位)记为 TTL (Time To Live),数据报在网络中可通过的路由器数的最大值。
协议(8 位)字段指出此数据报携带的数据使用何种协议,以便目的主机的 IP 层将数据部分上交给哪个处理过程。
首部检验和(16 位)字段只检验数据报的首部,不检验数据部分。这里不采用 CRC 检验码而采用简单的计算方法。
源地址和目的地址都各占 4 字节
2.5.2 IP数据报的首部可变部分 IP 首部的可变部分就是一个选项字段,用来支持排错、测量以及安全等措施,内容很丰富。 选项字段的长度可变,从 1 个字节到 40 个字节不等,取决于所选择的项目。 增加首部的可变部分是为了增加 IP 数据报的功能,但这同时也使得 IP 数据报的首部长度成为可变的。这就增加了每一个路由器处理数据报的开销。 实际上这些选项很少被使用。 2.5.3 IP 层转发分组的流程 有四个 A 类网络通过三个路由器连接在一起。每一个网络上都可能有成千上万个主机。 可以想像,若按目的主机号来制作路由表,则所得出的路由表就会过于庞大。 但若按主机所在的网络地址来制作路由表,那么每一个路由器中的路由表就只包含 4 个项目。这样就可使路由表大大简化。 在路由表中,对每一条路由,最主要的是(目的网络地址,下一跳地址) 2.5.4查找路由表根据目的网络地址就能确定下一跳路由器,这样做的结果是:
IP 数据报最终一定可以找到目的主机所在目的网络上的路由器(可能要通过多次的间接交付)。 只有到达最后一个路由器时,才试图向目的主机进行直接交付。 2.5.5特定主机路由 这种路由是为特定的目的主机指明一个路由。 采用特定主机路由可使网络管理人员能更方便地控制网络和测试网络,同时也可在需要考虑某种安全问题时采用这种特定主机路由。 2.5.6 默认路由(default route) 路由器还可采用默认路由以减少路由表所占用的空间和搜索路由表所用的时间。 这种转发方式在一个网络只有很少的对外连接时是很有用的。 默认路由在主机发送 IP 数据报时往往更能显示出它的好处。 如果一个主机连接在一个小网络上,而这个网络只用一个路由器和因特网连接,那么在这种情况下使用默认路由是非常合适的。 2.5.7需要强调指出 IP 数据报的首部中没有地方可以用来指明“下一跳路由器的 IP 地址”。 当路由器收到待转发的数据报,不是将下一跳路由器的 IP 地址填入 IP 数据报,而是送交下层的网络接口软件。 网络接口软件使用 ARP 负责将下一跳路由器的 IP 地址转换成硬件地址,并将此硬件地址放在链路层的 MAC 帧的首部,然后根据这个硬件地址找到下一跳路由器。 2.5.8 分组转发算法 (1)从数据报的首部提取目的主机的 IP 地址 D, 得出目的网络地址为 N。 (2) 若网络 N 与此路由器直接相连,则把数据报直接交付目的主机 D;否则是间接交付,执行(3)。 (3) 若路由表中有目的地址为 D 的特定主机路由,则把数据报传送给路由表中所指明的下一跳路由器;否则,执行(4)。 (4) 若路由表中有到达网络 N 的路由,则把数据报传送给路由表指明的下一跳路由器;否则,执行(5)。 (5) 若路由表中有一个默认路由,则把数据报传送给路由表中所指明的默认路由器;否则,执行(6)。 (6) 报告转发分组出错。D, 得出目的网络地址为 N。
(2) 若网络 N 与此路由器直接相连,则把数据报直接交付目的主机 D;否则是间接交付,执行(3)。 (3) 若路由表中有目的地址为 D 的特定主机路由,则把数据报传送给路由表中所指明的下一跳路由器;否则,执行(4)。 (4) 若路由表中有到达网络 N 的路由,则把数据报传送给路由表指明的下一跳路由器;否则,执行(5)。 (5) 若路由表中有一个默认路由,则把数据报传送给路由表中所指明的默认路由器;否则,执行(6)。 (6) 报告转发分组出错。作者:萌小肆