HDFS进阶总结
觉得有帮助的,请多多支持博主,点赞关注哦~
数据量越来越大,在一个操作系统管辖的范围内存不下,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,so需要一种系统来管理多台机器上的文件,分布式文件管理系统. HDFS的概念:
HDFS(Hadoop Distributed File System),分布式文件系统。
HDFS的设计适合一次写入,多次读出的场景,且不支持文件的随机修改。
适合用来做数据分析前的存储介质。 1.2、HDFS特点 1.2.1、优点 高容错性,具有副本机制,同一数据块分别存储在不同副本上,某一副本的数据块出现丢失,都能自动修复。 分布式存储,类似于横向扩容,存储的数据量非常大(文件数量、数据规模)。弹性的可扩展、伸缩性。 hdfs具有很强的兼容性,支持的数据类型非常多。 成本低廉,使用廉价的PC机就可以。 1.2.2、缺点 不适合低延迟数据的读写,对于大数据读写时具有一定的延迟性。 不适合数据量小文件多(大量的小文件)的情况,因为文件的特性信息,每个文件都会记录到内存,所以会浪费内存。 不能并发写入,不支持随机修改,只支持追加修改。 1.3、HDFS角色
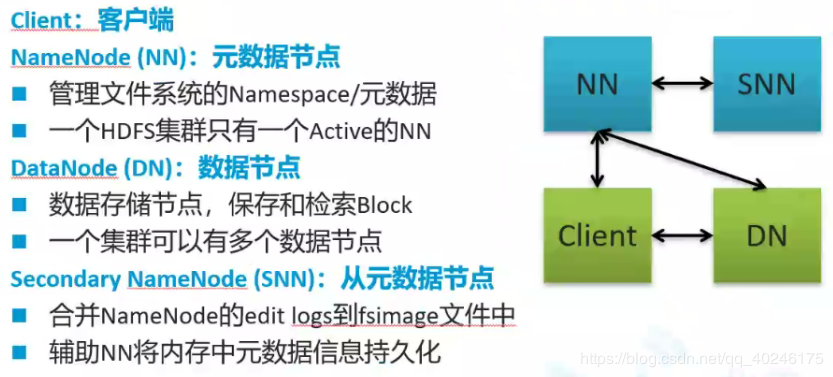
Client客户端节点(市场招生办):
在文件上传到集群时,由Client将文件按照每块128M(hadoop2.x)切分成各个Block,然后存储 与Namenode通信,作用是获取文件的位置信息 与DataNode交互,实现数据的读取与写入 通过hdfs cli命令,操作HDFS 1.3.2、NameNodeNameNode (NN)(老师):元数据节点
管理文件系统的Namespace/元数据 一个HDFS集群只有一个Active的NN 管理数据块信息和副本信息 接收并处理客户端的请求 1.3.3、DataNodeDataNode (DN)(学生):数据节点
数据存储节点,保存和检索Block 一个集群可以有多个数据节点 1.3.4、Secondary NameNodeSecondary NameNode (SNN)(助教):从元数据节点
合并NameNode的edit logs到fsimage文件中 辅助NN将内存中元数据信息持久化 1.4、HDFS结构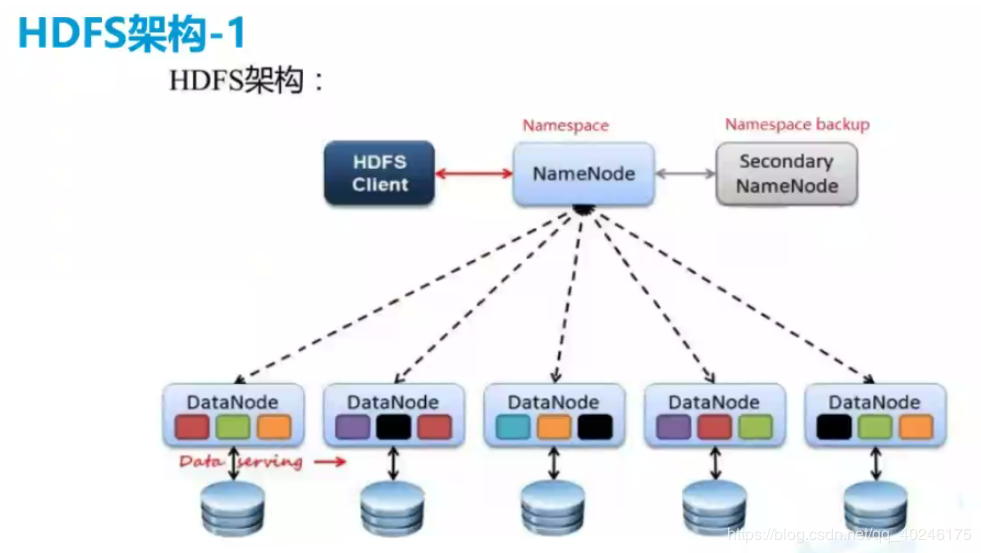
hdfsclient:可以认为不属于集群,他只是外部操作的节点,在哪台机器上操作,哪台就是client.
namenode:主要管理namespace。
宏观上看是管理各个集群的DataNode(如:物理ip地址、存储的块信息、状态等等)
secondarynamenode:相当于namenode的助理
DataNode:存放不同的块数据
整体就是:首先client先询问namenode文件有没有,namenode回复响应,如果没有,client就将文件分割,并询问namenode分割后的数据块连副本要存在哪台机子上,namenode回复存哪存哪,然后client再跟对应的DataNode通信,存储,最后datanode发给namenode执行结果。
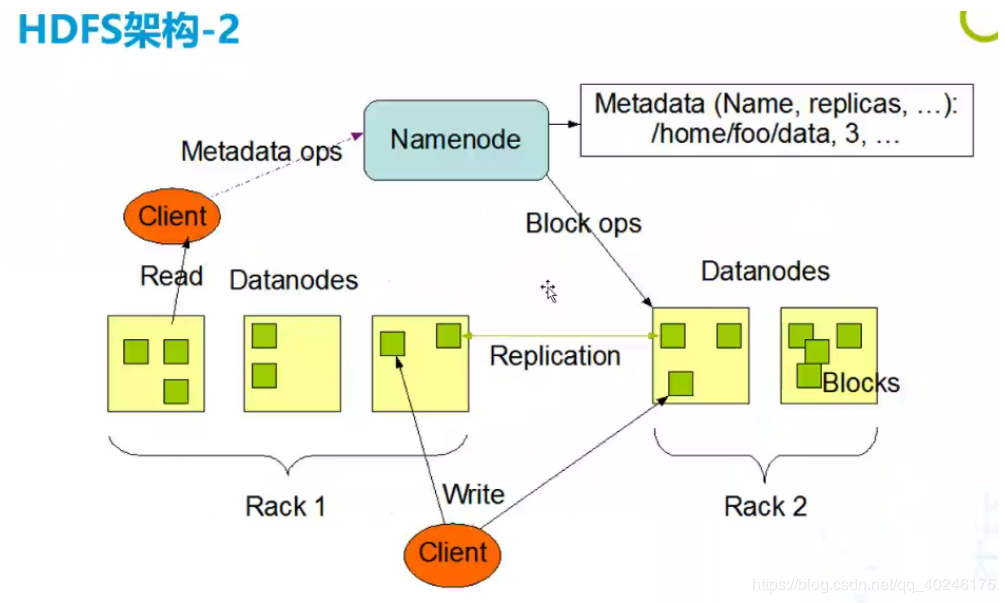
主要侧重文件读写的流程
namenode、DataNode、client没有侧重secondarynamenode
分为两个机架rack1(三台机子)和rack2(两台机子)
client->metadata ops->namenode:client进行元数据操作,与namenode进行通信
metadata(namenode元数据)中包含什么信息:如文件名字、副本、块信息等等
读取的话client先与namenode进行通信,询问文件在什么地方,nn返回响应信息(文件分为几块,以及块信息副本什么的),然后client根据返回的块信息,根据实际的机架,根据就近原则找附近的dn进行读取,最后关闭副本。
写入的话,可以看见是并发的写入
1.5、NN与SNN工作机制
1.5.1、概括
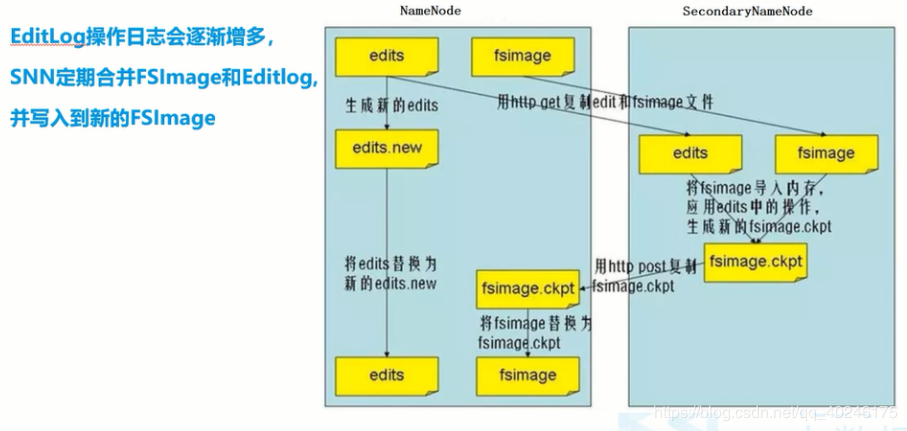
1)NamdeNode生成一个新的文件:edit.new
2)每隔一段时间(默认1小时),SNN将NN上最新的FSImage和积累的edits通过http协议下载到本地,并加载到内存。
3)SNN将fsimage和editlog进行merge(合并),生成一个新的镜像文件(fsimage.ckpt)
这个过程称为checkpoint
4)然后SNN将新生成的fsimage.ckpt通过http协议发送到namenode.
5)NameNode将edits.new重命名为edits,将fsimage.ckpt重命名为fsimage
1.5.2、理解
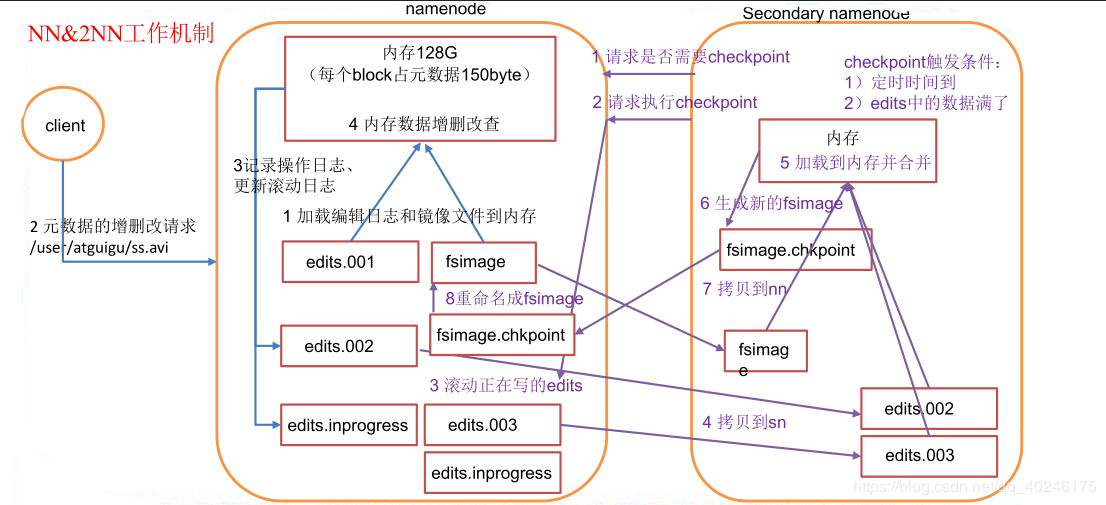
第一阶段:NameNode 启动
第二阶段:Secondary NameNode 工作
Secondary NameNode 询问 NameNode 是否需要 checkpoint。直接带回 NameNode是否检查结果。 Secondary NameNode 请求执行 checkpoint。 NameNode 滚动正在写的 edits 日志。 将滚动前的编辑日志和镜像文件拷贝到 Secondary NameNode。 Secondary NameNode 加载编辑日志和镜像文件到内存,并合并。 生成新的镜像文件 fsimage.chkpoint。 拷贝 fsimage.chkpoint 到 NameNode。 NameNode 将 fsimage.chkpoint 重新命名成 fsimage 1.6、FSImage、EditLog解析 1.6.1、概念namenode 被格式化之后,将在/opt/module/hadoop-2.7.7/data/tmp/dfs/name/current 目录中产生如下文件:
edits_0000000000000000000
fsimage_0000000000000000000.md5
seen_txid
VERSION
Fsimage 文件:HDFS 文件系统元数据的一个永久性的检查点,其中包含 HDFS文件系统的所有目录和文件 idnode 的序列化信息。
Edits 文件:存放 HDFS 文件系统的所有更新操作的路径,文件系统客户端执行的所有写操作首先会被记录到 edits 文件中。
seen_txid 文件保存的是一个数字,就是最后一个 edits_的数字
每次 NameNode 启动的时候都会将 fsimage 文件读入内存,并从 00001 开始到seen_txid 中记录的数字依次执行每个 edits 里面的更新操作,保证内存中的元数据信息是最新的、同步的,可以看成 NameNode 启动的时候就将 fsimage 和 edits 文件进行了合并。
1.6.2、查看fsimage、edits

# 基本语法
hdfs oiv -p 文件类型 -i 镜像文件 -o 转换后文件输出路径
# 案例
[hadoop01@biubiubiu01 current]$ pwd
/opt/model/hadoop_data/dfs/name/current
[hadoop01@biubiubiu01 current]$ hdfs oiv -p XML -i fsimage_0000000000000000025 -o /opt/model/hadoop_data/fsimage.xml
[hadoop01@biubiubiu01 current]$ cat /opt/model/hadoop_data/fsimage.xml
# 可将显示的 xml 文件内容拷贝到可查看xml的软件中,并格式化。打开查看即可。
1.6.2.2、使用oev 查看 edits 文件
# 基本语法
hdfs oev -p 文件类型 -i 编辑日志 -o 转换后文件输出路径
# 案例
[hadoop01@biubiubiu01 current]$ hdfs oev -p XML -i edits_0000000000000000012-0000000000000000013 -o /opt/model/hadoop_data/edits.xml
[hadoop01@biubiubiu01 current]$ cat /opt/model/hadoop_data/edits.xml
# 可将显示的 xml 文件内容拷贝到可查看xml的软件中,并格式化。打开查看即可。
1.6.3、配置

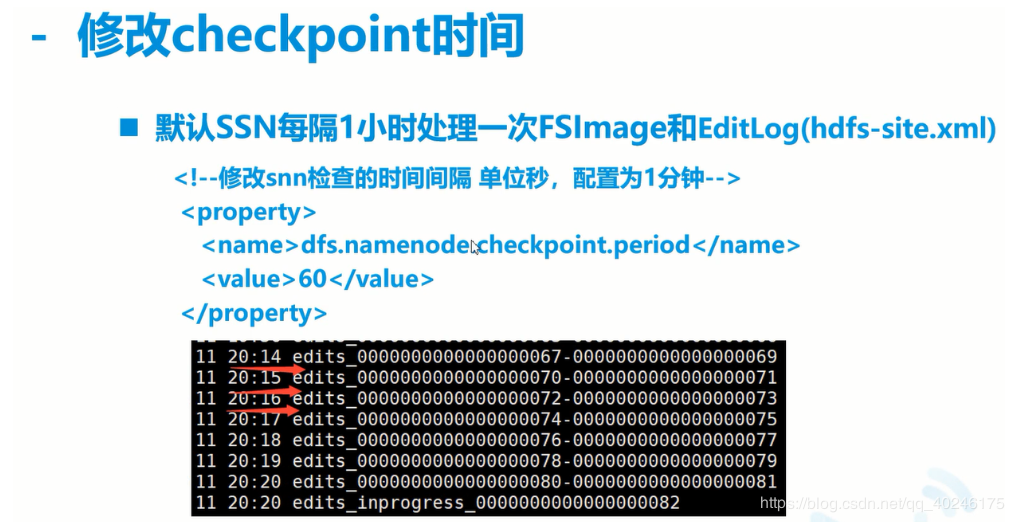
(1)通常情况下,SecondaryNameNode 每隔一小时执行一次。
[hdfs-default.xml]
dfs.namenode.checkpoint.period
3600
(2)一分钟检查一次操作次数,当操作次数达到 1 百万时,SecondaryNameNode 执行
一次。
dfs.namenode.checkpoint.txns
1000000
操作动作次数
dfs.namenode.checkpoint.check.period
60
1 分钟检查一次操作次数
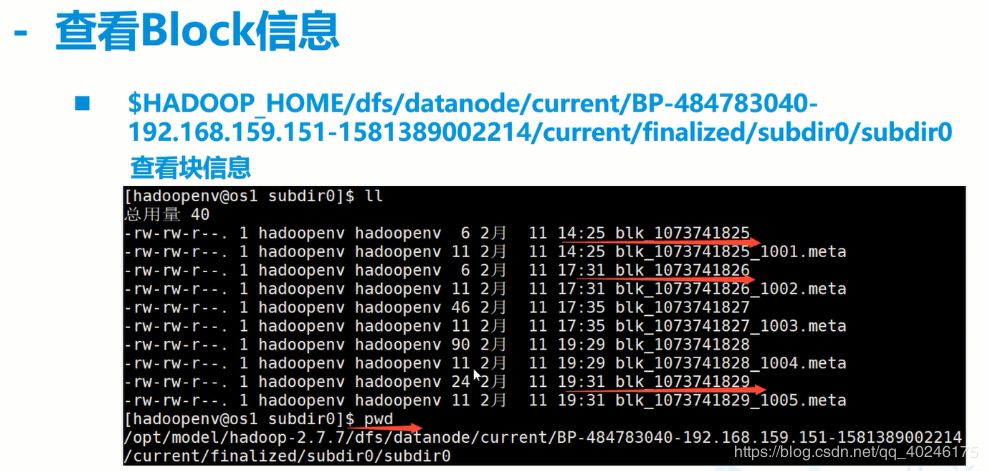
1.7、查看数据块信息

 2、HDFS读写流程
2.1、HDFS读文件的流程
2.1.1、详解
2、HDFS读写流程
2.1、HDFS读文件的流程
2.1.1、详解
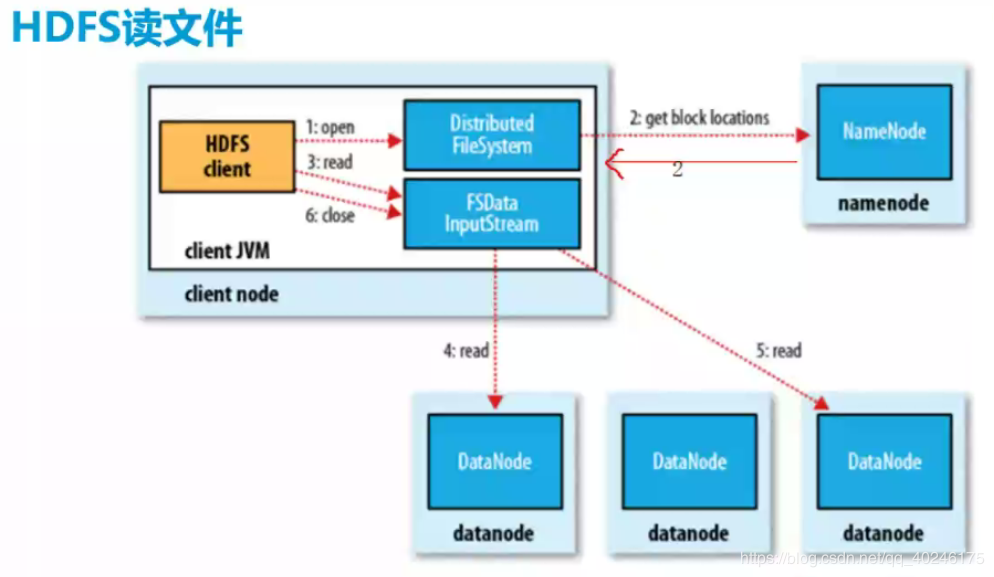
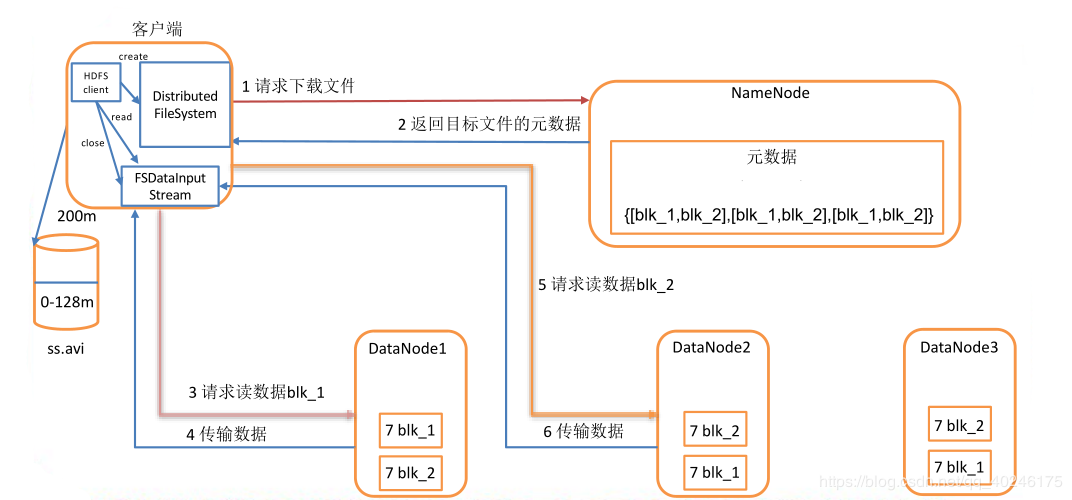
【读文件流程】
1)HDFS Client通过Distributed FileSystem访问NameNode,查询元数据信息,获得这个文件的数据块位置列表,返回输入流对象。
元数据(块列表{blk-01,blk02};
块所在的DataNode列表{blk-01:node1,blk-01:node2,blk-02:node2,blk-02:node3})
2)NameNode通过查询NameSpace的元数据,找到数据块所在的DataNode节点的位置,然后按照就近原则,挑选数据块对应的DataNode节点列表并返回。
元数据(块列表{blk-01,blk02};
块所在的DataNode列表{blk-01:node1,blk-02:node3})
3,4,5)使用底层文件系统的FSDataInputStream,开始并行读取各个数据块(单位packet(64k))。同时,读完一个Block都会进行checksum验证,如果读取DN时出错,client node通知NameNOde,然后再从下一个拥有该block副本的DN继续读取。
6)最终读取完所有的block合并成一个完成的文件,并关闭读取流
2.1.2、理解
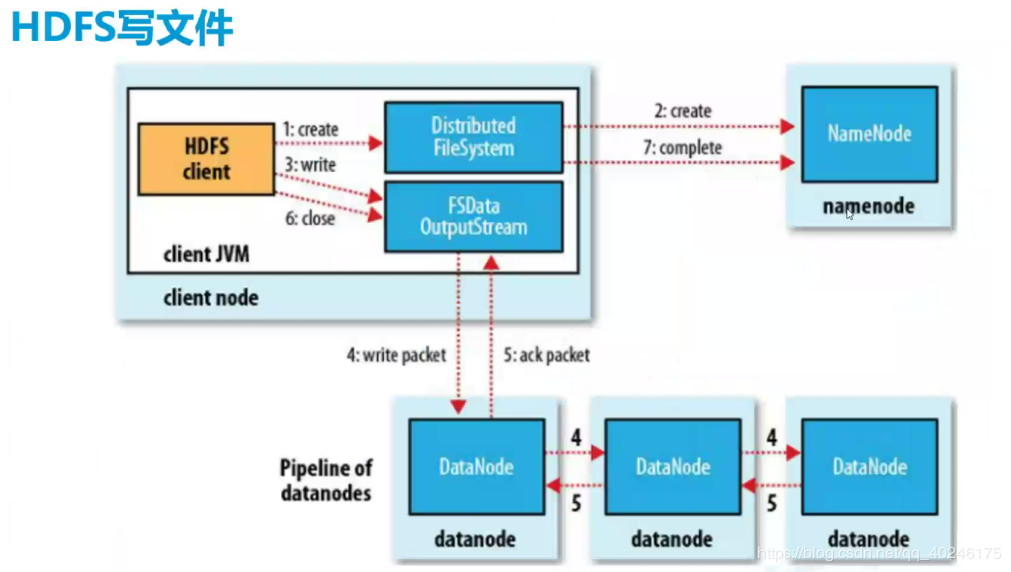
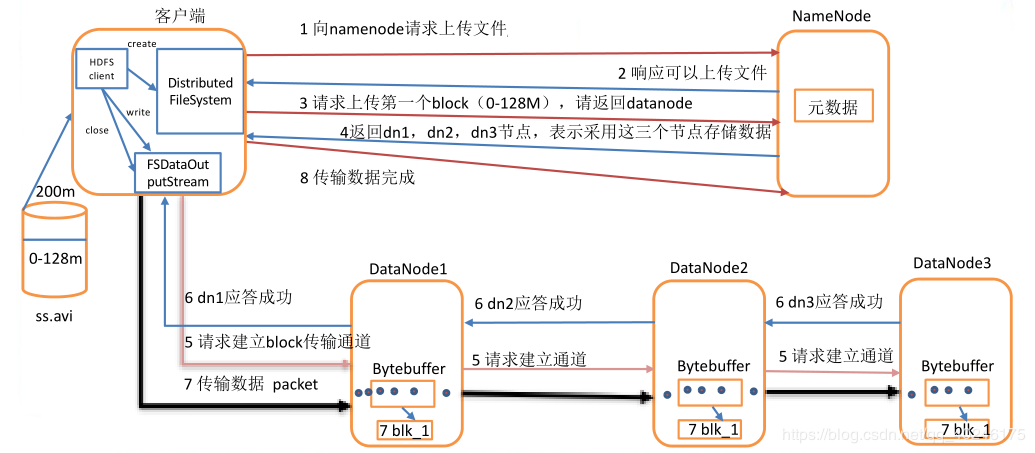
【写文件的流程】
1)HDFS Client调用DistributedFileSystem对象的create方法,创建文件输出流对象 (FSDataOutputStream对象)。
2)client node通过DistributedFileSystem对象与NameNode进行RPC(Remote Procedure Call)远程过程调用,向NN询问是否FS中有该文件
2.1)Namenode响应,文件不存在,可以上传
2.3)NameNode返回文件能存储的节点列表,比如node01、node02、node03
3)通过FSDataOutputStream对象,向DataNode写入数据,数据首先被写入FSDataOutputStream对象内部的Buffer缓冲区中,然后数据被分割成一个个Packet数据包。
4)以Packet最小单位,基于Socket连接发送到按特定算法(MD5)选择的HDFS集群中一组DataNode(正常是3个,可能大于等于1)中的一个节点上,在这组DataNode组成的Pipeline(响应输出流)上依次传输Packet。
5)这组DataNode组成的Pipeline反方向上,发送ack响应,最终由Pipeline中第一个DataNode节点将Pipeline ack响应结果发送给Client。
6)完成向文件写入该数据块写入数据
【备注】第2、3...个block 重复执行2/3/4/5/6(第二步,只询问块所在的节点位置)
7)最后一个数据块写入完毕,
7.1)Client在文件输出流(FSDataOutputStream)对象上调用close方法,关闭流
7.2)调用DistributedFileSystem对象的complete方法,通知NameNode文件写入成功
2.2.2、理解
未完待续~
作者:Biubiubiu!!