【kettle抽取Orecle/Mysql数据至HDFS】诸如‘\u0001’等特殊分隔符表示法
【kettle抽取Orecle/Mysql数据至HDFS】诸如‘\u0001’等特殊分隔符表示法前言设计问题分析解决办法后记
前言
作者:Jack_Roy
由于需要设计一个每天多批次的定时作业,由于单端逻辑不能抽取出目标数据,其中涉及了跨库问题,因此需要从mysql、Oracle数据库中将数据同步至一个统一的环境中(hive),那么由于数据量大(百亿级),关联数据要从各个业务部门自有的数据库导入,kettle无疑成了最好的选择。
设计由于要推张业务支持表出去,因为在这里我根据四张业务表的前置表依赖关系做了个聚类,把四项业务的数据导入流程分在了四个方向上,方便日后有针对性的修改,效果如下:
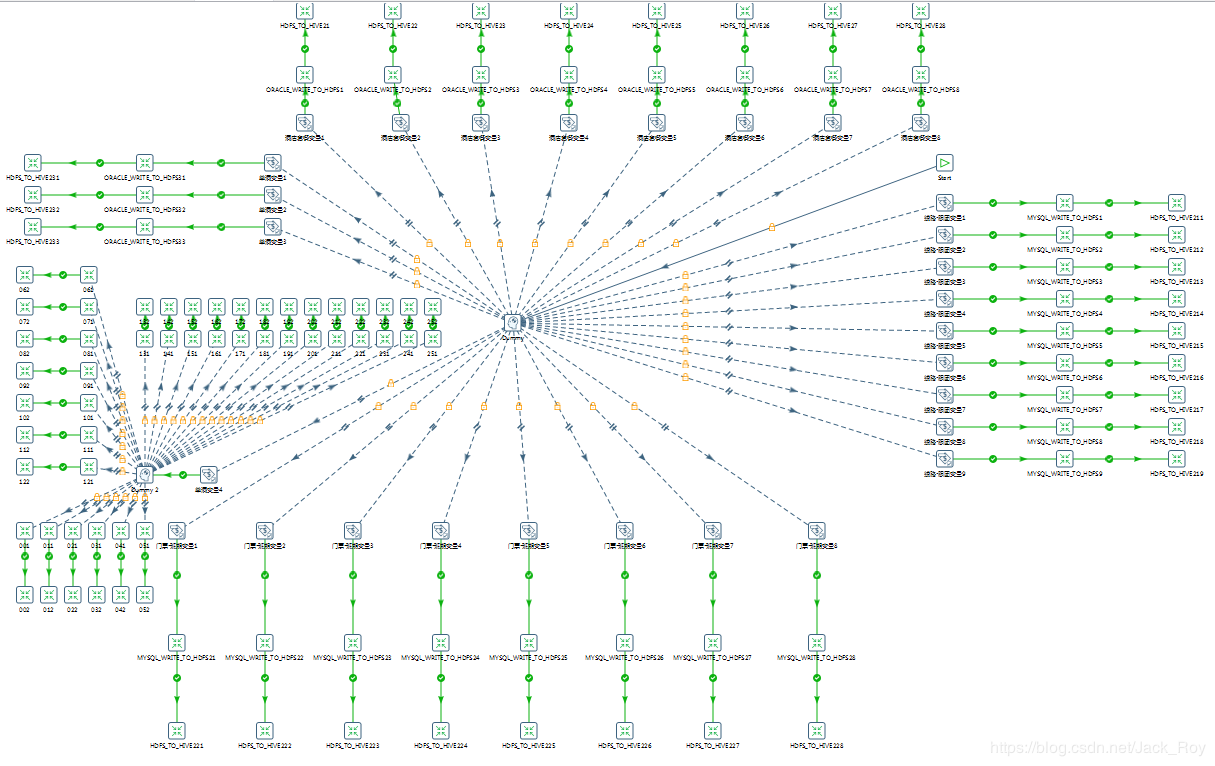
设计完成后提交生产集群上跑,一切都很顺利:
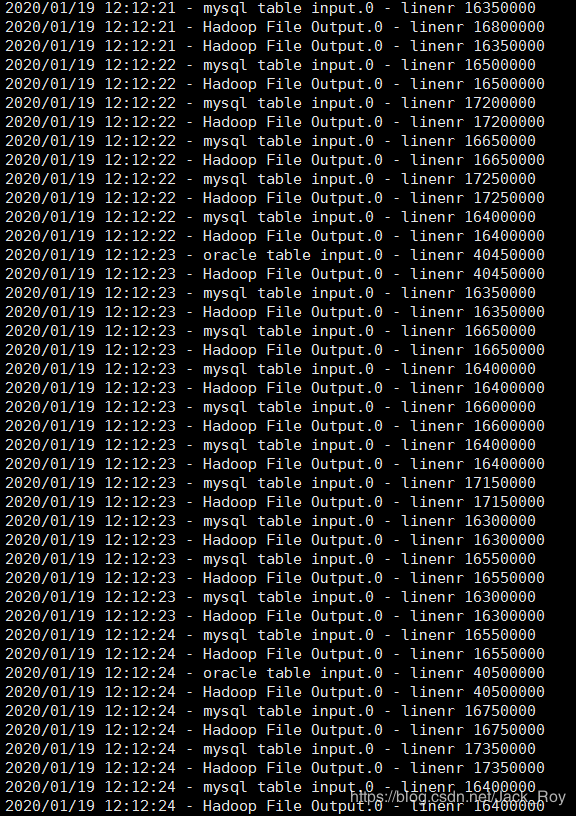
查看了一下中间文件,问题来了:
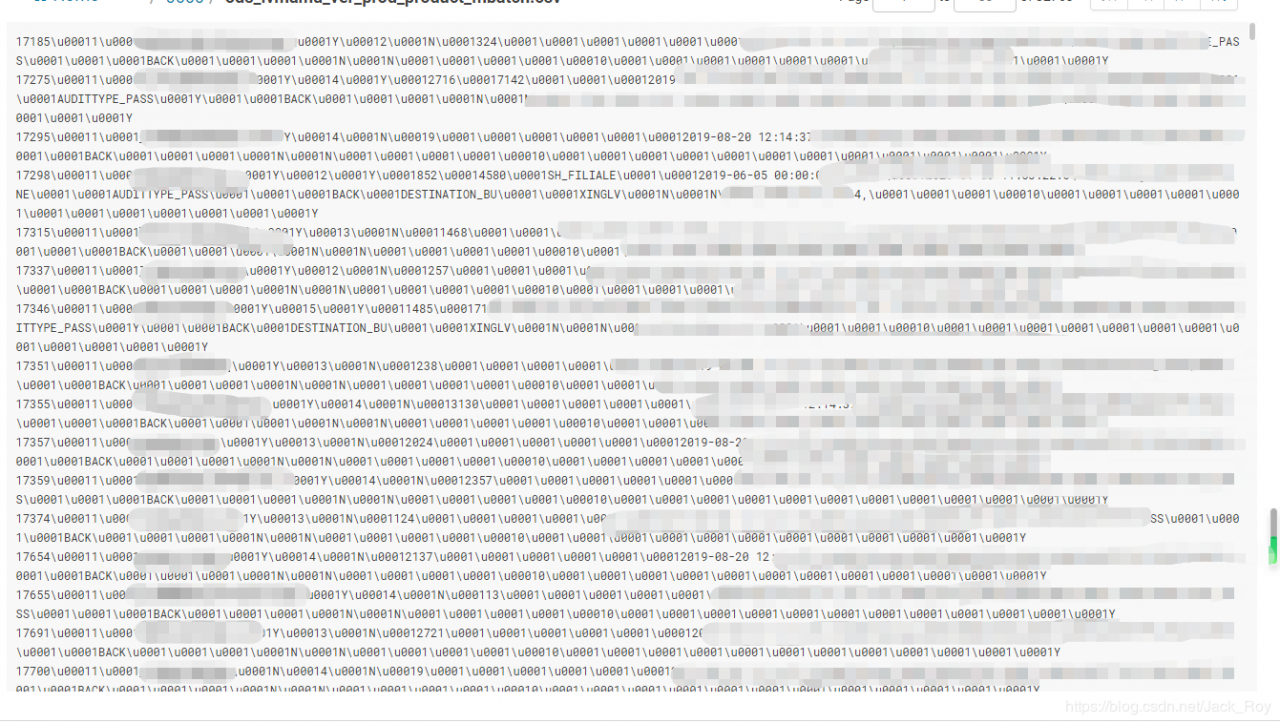
‘\u0001’分隔符失效!
按照公司的规范,hive外部表的文件分隔符统一使用‘\u0001’,但是笔者在job中设置的变量失效了,很明显kettle不支持特殊字符的这种写法:
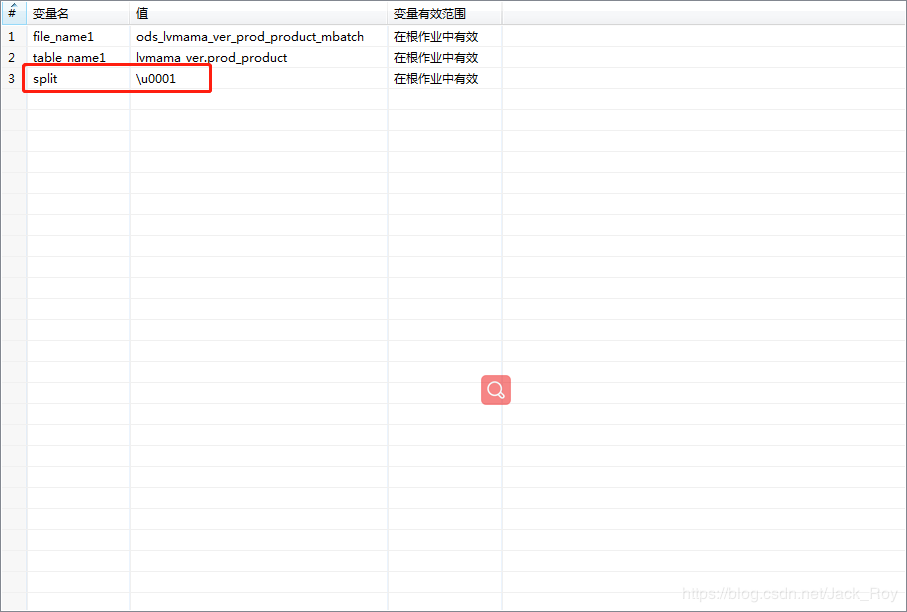
问题的关键在于,找到一种kettle支持的特殊字符的写法。
查阅网上的一些现有资料后,笔者找到了解决办法,根据ASCII码表,我们在kettle中采用$[十六进制值]方式来表示:
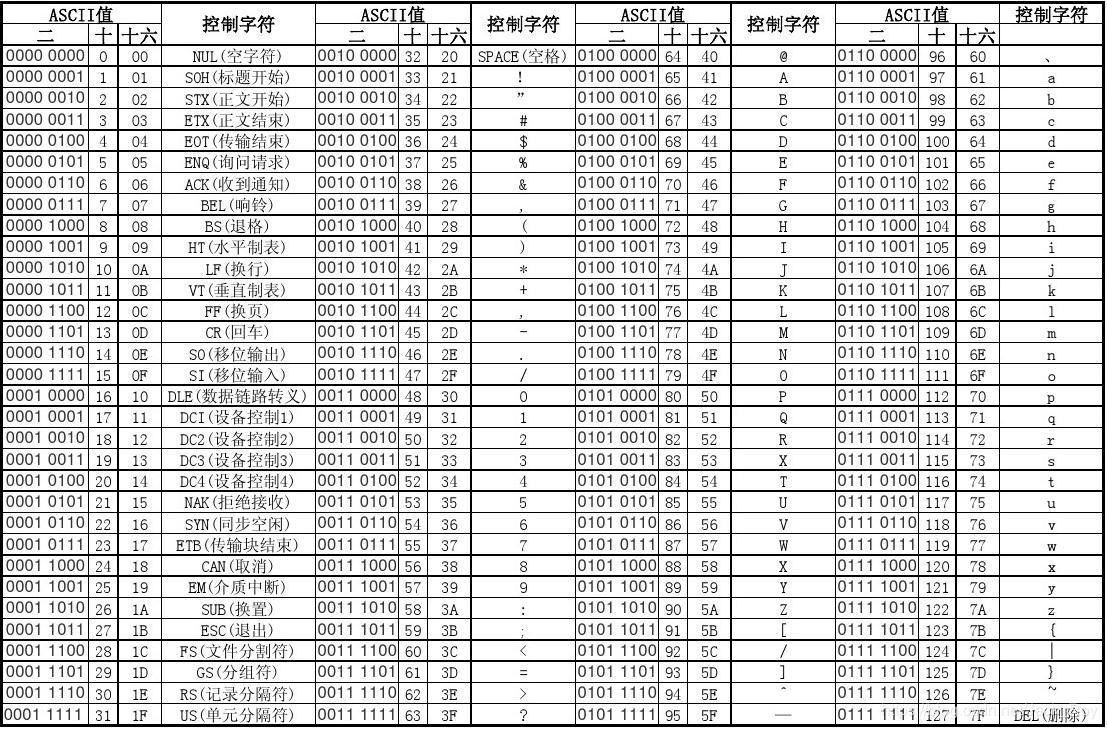
比如‘\u0001’的十六进制是01,就用$[01]来表示:
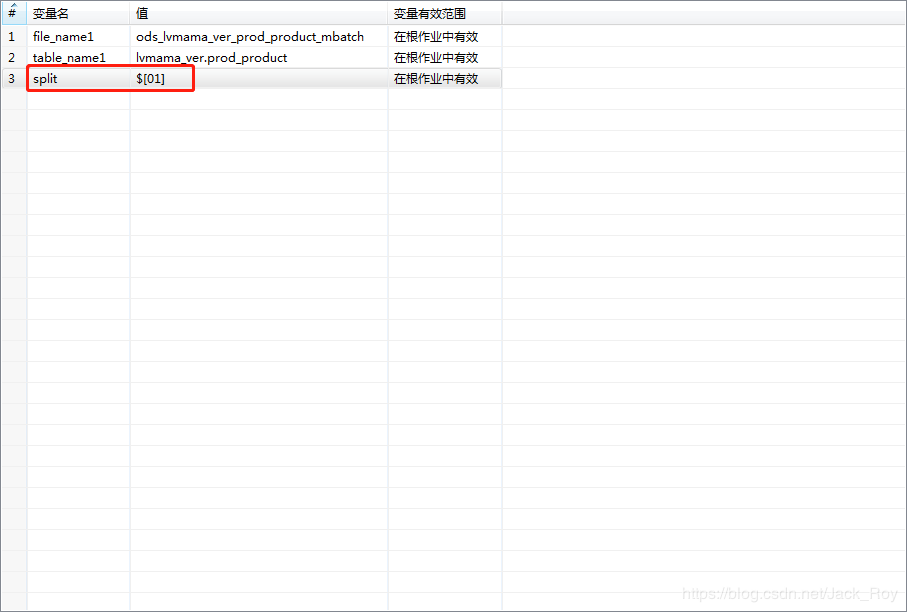
随后再执行,去hdfs上查看文件就看到可以正常分隔了:

根据自己的需要,需要什么样的分隔符,就在ASCII码表上找到对应的分隔符十六进制数,写入$[]即可。
作者:Jack_Roy
相关文章
Fawn
2020-01-20
Vanora
2020-02-14
Olathe
2023-07-20
Talia
2023-07-20
Serafina
2023-07-20
Hazel
2023-07-20
Ebony
2023-07-20
Olga
2023-07-20
Elizabeth
2023-07-20
Ianthe
2023-07-20
Valora
2023-07-20
Phemia
2023-07-20
Tia
2023-07-20
Summer
2023-07-20
Fredrica
2023-07-20
Maha
2023-07-21
Edie
2023-07-21
Bonnie
2023-07-21