Hadoop整合Hbase案列详解
需求:编写mapreduce程序实现将hbase中的一张表的数据复制到另一张表中
要求:读取HBase当中user这张表的f1:name、f1:age数据,将数据写入到另外一张user2表的f1列族里面去==***

**注意:**两张表的列族一定要相同
/**
create 'user','f1'
put 'user','rk001','f1:name','tony'
put 'user','rk001','f1:age','12'
put 'user','rk001','f1:address','beijing'
put 'user','rk002','f1:name','wangwu'
create 'user2','f1'
*/
第二步:创建maven工程并导入jar包
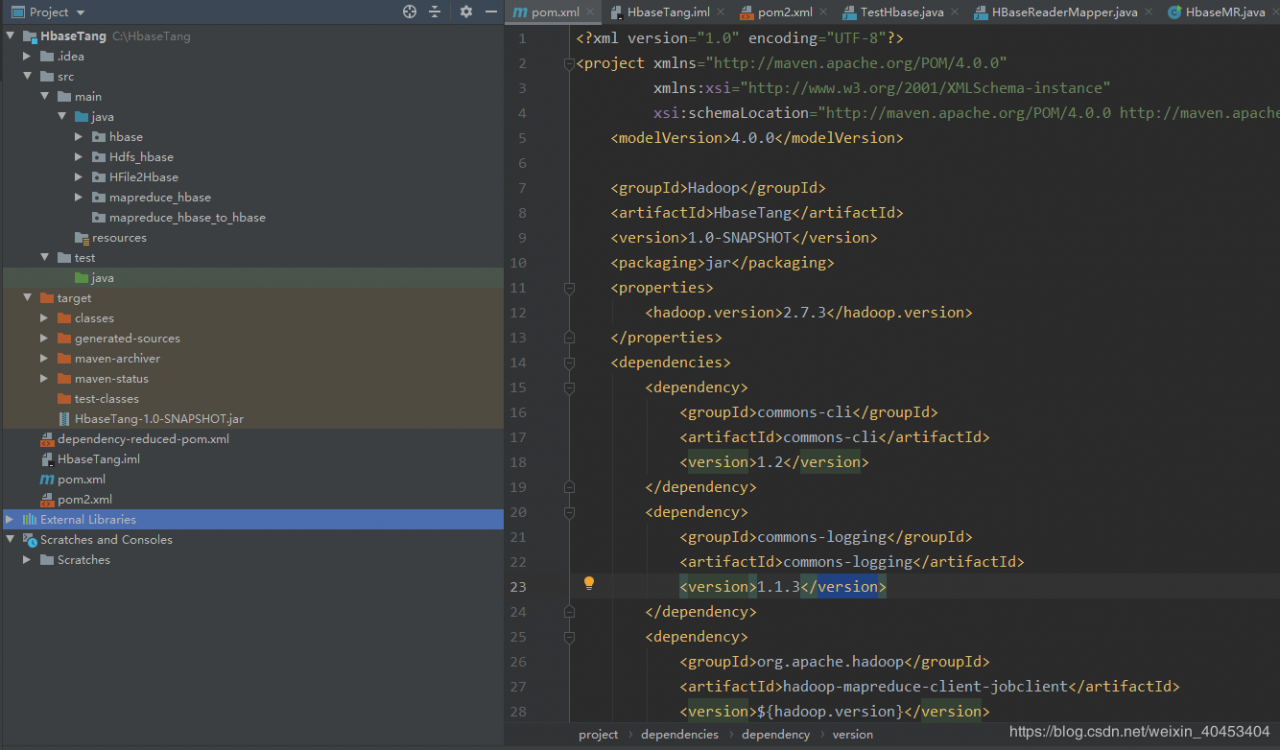
pom.xml文件内容如下:
4.0.0
Hadoop
HbaseTang
1.0-SNAPSHOT
jar
2.7.3
commons-cli
commons-cli
1.2
commons-logging
commons-logging
1.1.3
org.apache.hadoop
hadoop-mapreduce-client-jobclient
${hadoop.version}
org.apache.hadoop
hadoop-common
${hadoop.version}
org.apache.hadoop
hadoop-hdfs
2.7.3
org.apache.hadoop
hadoop-hdfs
${hadoop.version}
org.apache.hadoop
hadoop-mapreduce-client-app
${hadoop.version}
org.apache.hadoop
hadoop-mapreduce-client-hs
${hadoop.version}
org.apache.hbase
hbase-client
1.2.1
org.apache.hbase
hbase-common
1.2.1
org.apache.hbase
hbase-server
1.2.1
junit
junit
4.12
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.Text;
import java.io.IOException;
/**
myuser f1: name&age => myuser2 f1
*/
public class HBaseReadMapper extends TableMapper {
/**
*
@param key rowkey
@param value rowkey此行的数据 Result类型
@param context
@throws IOException
@throws InterruptedException
*/
@Override
protected void map(ImmutableBytesWritable key, Result value, Context context) throws IOException, InterruptedException {
/**
ImmutableBytesWritable key:Mapper接收数据值是Put对象,key是hbase中一条数据Put对应的rowkey(可序列化)
Result value:hbase中读取的result对象
获取rowkey的字节数组*/
//获得roweky的字节数组
byte[] rowkey_bytes = key.get();
String rowkeyStr = Bytes.toString(rowkey_bytes);
Text text = new Text(rowkeyStr);
//输出数据 -> 写数据 -> Put 构建Put对象
Put put = new Put(rowkey_bytes);
//获取一行中所有的Cell对象
Cell[] cells = value.rawCells();
//将f1 : name& age输出
for(Cell cell: cells) {
//当前cell是否是f1
//列族
byte[] family_bytes = CellUtil.cloneFamily(cell);
String familyStr = Bytes.toString(family_bytes);
if("f1".equals(familyStr)) {
//在判断是否是name | age
byte[] qualifier_bytes = CellUtil.cloneQualifier(cell);
String qualifierStr = Bytes.toString(qualifier_bytes);
if("name".equals(qualifierStr)) {
put.add(cell);
}
if("age".equals(qualifierStr)) {
put.add(cell);
}
}
}
//判断是否为空;不为空,才输出
if(!put.isEmpty()){
context.write(text, put);
}
}
}
package com.kaikeba.hbase.demo01;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableReducer;
import org.apache.hadoop.io.Text;
import java.io.IOException;
/**
* TableReducer第三个泛型包含rowkey信息
*/
public class HBaseWriteReducer extends TableReducer {
//将map传输过来的数据,写入到hbase表
/**
Text:map端输出键类型
Put:map端输出值类型
ImmutableBytesWritable:reduce端输出键类型
*/
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
/**
*Text key:接收map端输出键
*Iterable values:接收map端输出值,put对象封装成的迭代器
*/
//rowkey
ImmutableBytesWritable immutableBytesWritable = new ImmutableBytesWritable();
immutableBytesWritable.set(key.toString().getBytes());
//遍历put对象,并输出
for(Put put: values) {
context.write(immutableBytesWritable, put);
}
}
}
(3)main入口类
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class HBaseMR extends Configured implements Tool {
public static void main(String[] args) throws Exception {
Configuration configuration = HBaseConfiguration.create();
//设定绑定的zk集群
configuration.set("hbase.zookeeper.quorum", "node01:2181,node02:2181,node03:2181");
int run = ToolRunner.run(configuration, new HBaseMR(), args);
System.exit(run);
}
@Override
public int run(String[] args) throws Exception {
Job job = Job.getInstance(super.getConf());
job.setJarByClass(HBaseMR.class);
//mapper
TableMapReduceUtil.initTableMapperJob(TableName.valueOf("myuser"), new Scan(),HBaseReadMapper.class, Text.class, Put.class, job);
//reducer
TableMapReduceUtil.initTableReducerJob("myuser2", HBaseWriteReducer.class, job);
boolean b = job.waitForCompletion(true);
return b? 0: 1;
}
}
第四步:打成jar包提交到集群运行
打包:
执行命令:
hadoop jar HbaseTang-1.0-SNAPSHOT.jar mapreduce_hbase.HbaseMR
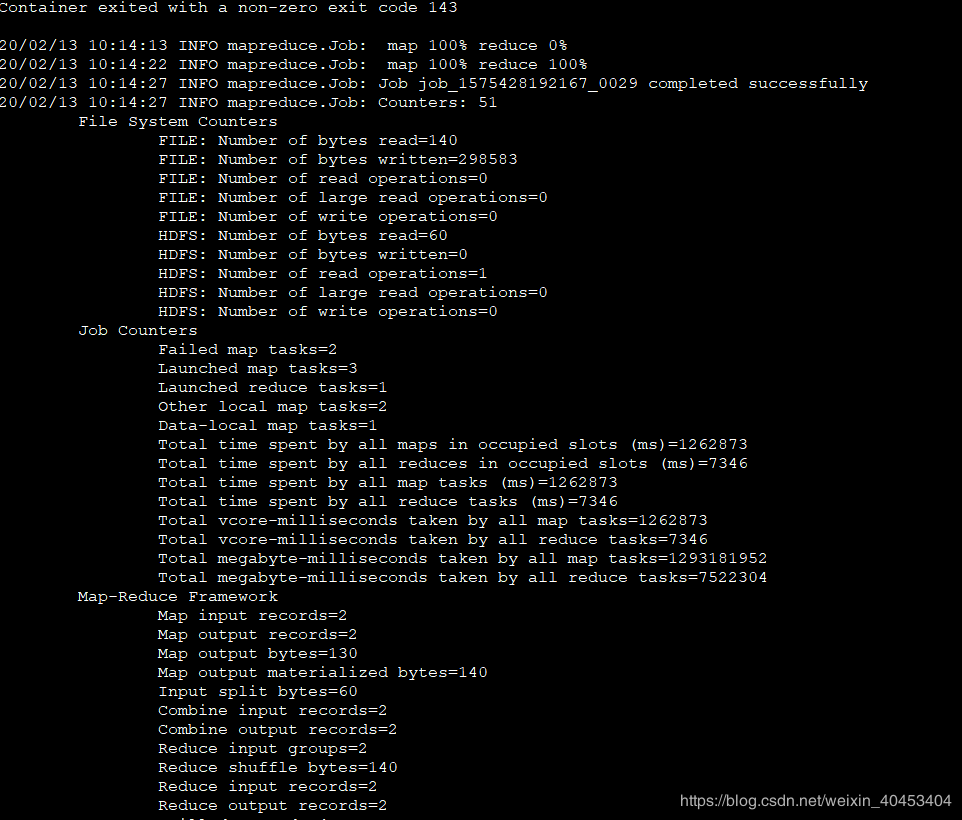
执行结果:
作者:Victor大数据