通过Github仓库链接爬取其star的数量
今天在处理Ghtorrent的projects数据表时,发现里面竟然没有star的数量,于是就想捣鼓着通过数据表里提供的链接把star数量爬下来。
没想到在爬取的过程中碰到了一个火狐浏览器的神坑,在这里写篇博客记录一下。
为了不失访问的普遍性,我把Ghtorrent提供的链接改成了访问原仓库的链接(原链接是这种形式 https://api.github.com/repos/owner_name/repository_name,改后的链接是这种形式 https://github.com/owner_name/repository_name)。原本的链接是可以通过爬取json文件来获得信息的,但是我这里就不写了。
// 需要导入的包
from lxml import etree
import requests
lxml是常用的爬虫解析包,requests是因为需要通过url进行访问。
接下来就得获取star数量对应的xpath的值了,右键检查元素,找到目标标签然后复制xpath的值。最终得到star数量所在标签的xpath的值为:“/html/body/div[4]/div/main/div[2]/div/ul/li[2]/div/form[2]/a”。
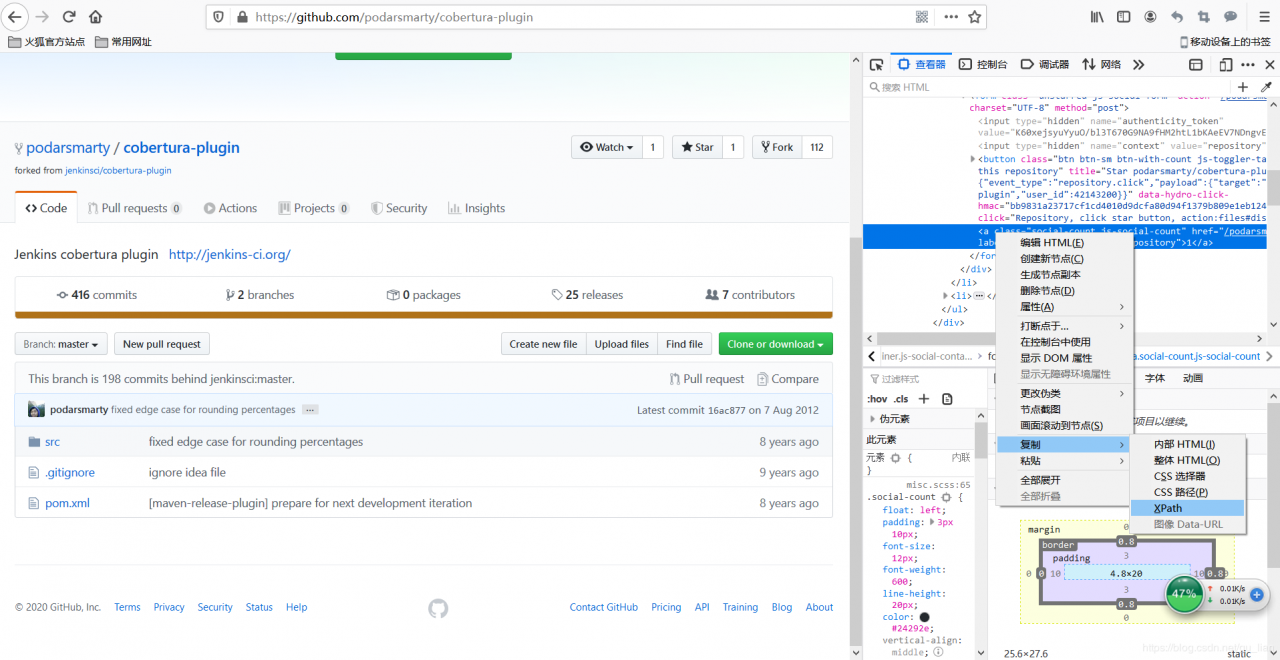 于是便兴高采烈地开爬:
于是便兴高采烈地开爬:
// 爬取url对应repository的star数量
url = "https://github.com/podarsmarty/cobertura-plugin"
response = requests.get(url)
text = response.text
html = etree.HTML(text)
html_data = html.xpath('/html/body/div[4]/div/main/div[2]/div/ul/li[2]/div/form[2]/a/text()')
print(html_data)
但是,html_data结果却为空。。。
在一脸懵逼的时候我尝试着修改一下xpath的值,看看究竟是什么问题。当我把xpath调整为"/html/body/div[4]/div/main/div[2]/div/div[1]/@class"时,html_data获得的结果是[‘signup-prompt-bg rounded-1 js-signup-prompt’]。我把这一串字符复制到原网页查看目前的定位信息的时候,原网页竟然找不到!这???原网页不认识这个class???这个class难不成是隔壁穿越过来的???
猜测网页可能进行了某些“神秘”的转换,最后我决定将原网页下载到本地一看究竟,发现如果参照本地下载下来的网页的话,star数量对应的xpath值应该是"/html/body/div[4]/div/main/div[1]/div[1]/ul/li[2]/a[2]"!
这火狐浏览器是在和我开玩笑吗???
复制谷歌浏览器的xpath为"//*[@id=“js-repo-pjax-container”]/div[1]/div/ul/li[2]/a[2]",结果可以正常返回。呃,所以能用一哥还是优先用一哥吧。
最后附上完整代码:
from lxml import etree
import requests
url = "https://github.com/podarsmarty/cobertura-plugin"
response = requests.get(url)
text = response.text
html = etree.HTML(text)
html_data = html.xpath('//*[@id="js-repo-pjax-container"]/div[1]/div/ul/li[2]/a[2]/text()')
stars_num = (html_data[0].replace("\n","").replace(" ",""))
print(stars_num)
作者:gu_lian