Engineering a Compiler读书笔记(1)
序言:
一个现代的优化器中包含有各式各样的技术。编译器使用贪婪启发式搜索来探索很大的解空间,使用确定性有限自动机来识别输入中的单词,不动点算法用于判断程序的行为,通过定理证明程序和代数化简器来预测表达式的值。编译器使用快速匹配算法将抽象计算映射到机器层次的操作,它们使用线性丢番图方程和普锐斯伯格算术来分析数组下标。编译器使用了大量的经典算法和数据结构,如散列表,图算法,和稀疏集实现方法等
第一章:编译概观
简介
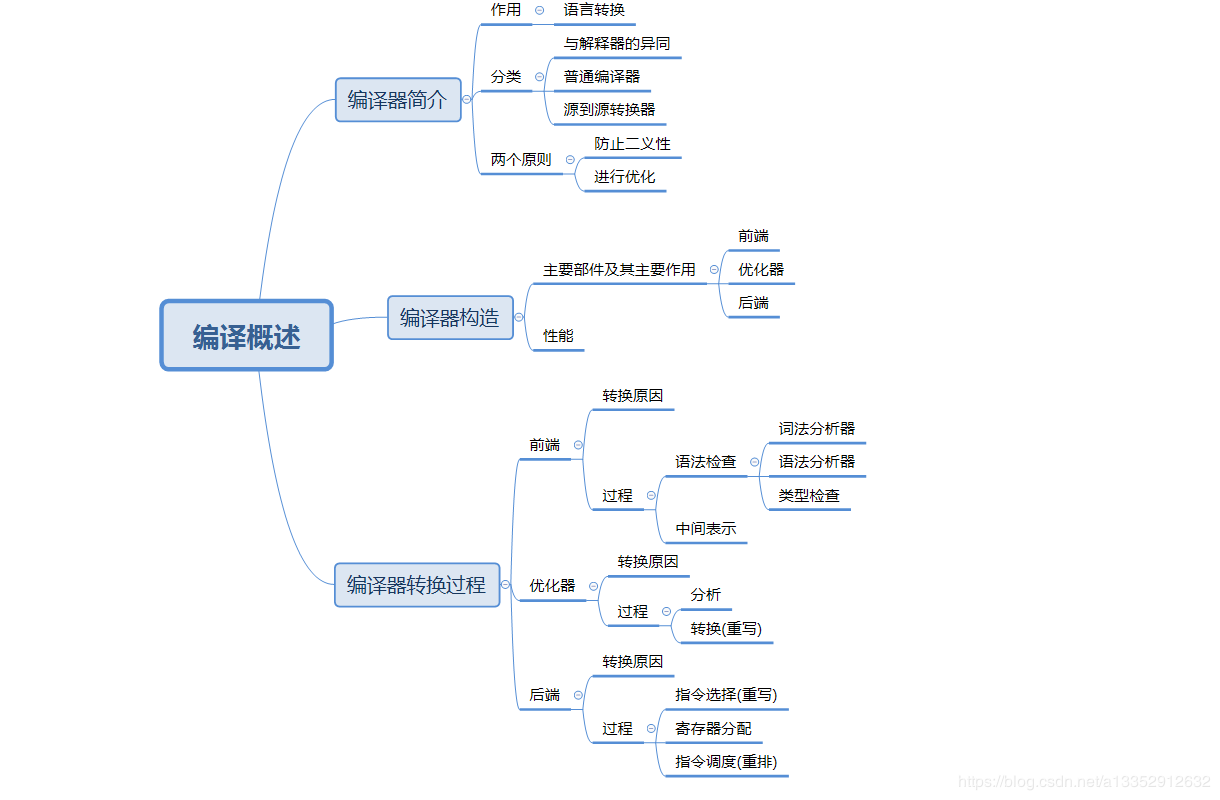
|| 编译器是一个计算机程序(类似OS),负责将一种语言编写的编写程序转换为令一种语言编写的程序。编译器的主要组件有:编译器,解释器,自动转换
|| 概念实现的路线图:
编译器为了实现其语言转换功能,那么就必须有以下功能:
|| 由以上功能需求,我们可以得到编译器的结构:
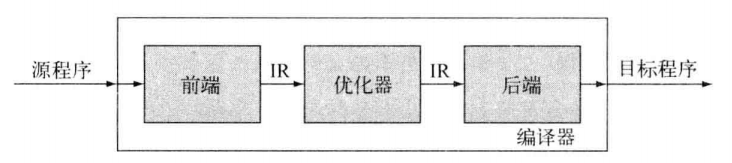
前端:用于处理源语言 后端:用于处理目标语言 中间形式:将前后端连接起来 优化器:改进优化转换,用于分析并重写中间形式|| 有关程序设计语言的说明:
作用:我们使用程序设计语言将计算表达为操作的序列,计算机程序就是一种由程序设计语言编写的抽象操作序列。
特点:1,其中的程序设计语言是用来精确表示计算的形式语言 2,是一种不允许有二义性的语言。3,往往具有较高的抽象性
|| 编译器若输出的仍是面对人类的程序设计语言,而非计算机的汇编语言。则称其为 由源到源的转换器
|| 解释器和编译器的区别:
编译器的输入是一个可执行的规格,输出的是另一种可执行的规格 编译器的输入是一个可执行的规格,输出的是执行该规格的结果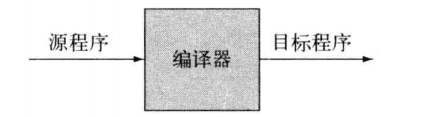
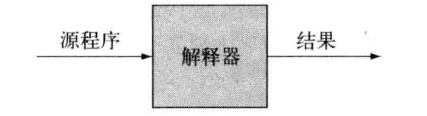
|| 解释器和编译器的共同之处:
都要分析输入的可执行规格,判断是否有效 都会建立一个内部模型,表示输入的结构和语义。 都要确定执行期间何处储存值|| 一些语言在转换方案上的区别:
APL,Scheme,更多的是用解释器实现的,而非编译器
Java,即包括编译,也包括解释来实现:(以下粗略表示过程)
|| 编译器的基本原则:
1:编译器必须保存被编译程序的语义 — 保存是为了在编译过程中保持正确性(防止二义性)
2:编译器必须以某种课察觉的方式来改进输入程序。例如c语言的源到源的转换器一定程度上由于输入程序,将输入程序改进源程序使得其有更好的可用性和一般性
编译器的结构
|| 结构说明:
前端的工作涉及理解源程序并将其分析结果以IR的形式记录下来;
优化器的工作专注于改进IR的形式;
后端的工作则是将转化优化后的IR映射到有限的资源上
|| 编译后代码的实际性能取决于:优化器和后端这两个阶段中使用的技术之间的相互交互的好坏,共同决定(并不是优化功能好,映射功能强,编译效果就好,之间的关联很重要)
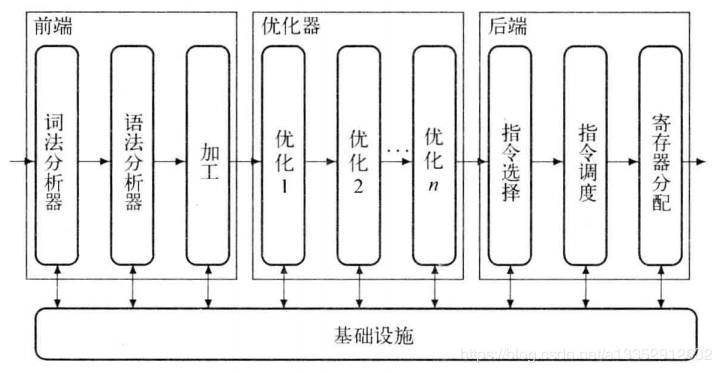
转换概述
前端中:
|| 原因:需要先翻译源代码
|| 前端中进行的转换:
语法检查:
|| 什么是语法:
某种规则的有限集定义,称为“语法”。我们通常将句子按词类划分,这样可以通过单一语法规则描述很多句子![]()
|| 前端中进行的两趟单独处理,分别称为“词法分析器”和“语法分析器”,来判断输入代码实际上是否属于语法定义中的有效集合
|| 词类分析器:
进行划分归类工作:识别一句话中各个单词,并将每个单词归入对应的词类中,以形如(p, s)的对的形式归类(p表示单词s的词类)
作用:将句子划分成已归类的单词构成的流
|| 语法分析器:
进行解析(语法分析工作):根据指定的输入语言的语法规则,匹配已分类单词的流,进行推导
作用:判断输入流是不是源语言中的一个句子(即是否满足源语言语法的句子)。
|| 类型检查
进行类型检查工作:对语法良构的句子进行类型判断(字符串/整型…)
作用:检查输入程序中对名字的使用在类型上是否一致
中间表示
生成出代码的IR形式,由于会生成各种种类的IR形式,故会涉及到选择策略问题
优化器中:
|| 原因:IR程序运行时,语句根据其在源代码中的顺序逐条运行时,代码将在更加有限,更加可预测的上下文中来执行。
功能:为了更加有效地分析IR代码,优化器会分析代码的IR形式,以发现有关上下文的事实,并利用此项有关上下文的知识来重写代码,使之更有效地获得同样的答案。
|| 优化中发生的转换
分析:判断程序在何处安全且有利地应用优化技术
常用的分析技术:数据流分析/相关性分析
转换:重写分析过的代码
|| 实例

后端中:
|| 原因:后端会遍历优化后的IR代码。为每个IR操作其选择对应的目标机操作来实现它,确定哪些值能够驻留在寄存器中,哪些值需要放进内存中,并自行插入代码以实现这些决策,并选择出一种执行高效的次序。
|| 后端中发生的转换
指令选择:
将IR操作重写为目标机操作,这个过程称为指令选择
寄存器分配:(最小化内存)
指令选择阶段,编译器会有意忽略目标机寄存器有限的事实。故这个阶段会重写代码,实现寄存器资源的分配
指令调度(最小化时间)
重排指令的次序,最小化指令在等待操作数撒谎给你所浪费的时间
作者:fang 0 jun