多线程爬虫出现报错AttributeError: 'NoneType' object has no attribute 'xpath'
mark一下,本技术小白的第一篇CSDN博客!
最近在捣鼓爬虫,看的是机械工业出版社的《从零开始学Python网络爬虫》。这书吧,一言难尽,优点是案例比较多,说的也还算清楚,但是槽点更多:1、较多低级笔误;2、基础知识一笔带过,简单得不能再简单,对Python基础不好的人不友好;3、代码分析部分,相同的代码反复啰嗦解释多次,而一些该解释的新代码却只字不提;4、这是最重要的一点,但也不全是本书的锅。就是书中用于案例的很多网页经过一段时间(即从书出版时到现在看书),从网站风格和样式都已经发生了很大变化,导致书中很多代码都不能用了。
这两天看到爬虫的多线程部分,用简书网站的网页练手,并对比串行爬虫和多线程爬虫的效率。串行爬虫运行正常,多线程爬虫报错:AttributeError: ‘NoneType’ object has no attribute ‘xpath’。代码如下:
import requests
from lxml import etree
import pymongo
import re
from multiprocessing import Pool
import time
client = pymongo.MongoClient('localhost',27017)
mydb = client['mydb']
jianshu_reping = mydb['jianshu_reping']
def get_reping_infoes(url):
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'
}
res = requests.get(url,headers=headers)
selector = etree.HTML(res.text)
# print("selector type:", type(selector),"response statue code:",res.status_code)
titles = selector.xpath('//a[@class="title"]/text()')
authors = selector.xpath('//a[@class="nickname"]/text()')
abstracts = selector.xpath('//p[@class="abstract"]/text()')
comments = re.findall('iconfont ic-list-comments".*?(.*?)\n',res.text,re.S)
rewards = re.findall('iconfont ic-list-like".*?(.*?)',res.text,re.S)
for title,author,abstract,comment,reward in zip(titles,authors,abstracts,comments,rewards):
info = {
"title":title,
"author":author,
"abstract":abstract.strip(),
"comment":comment.strip(),
"reward":reward.strip()
}
jianshu_reping.insert_one(info)
# time.sleep(1)
if __name__ == '__main__':
urls = ['https://www.jianshu.com/c/e048f1a72e3d?order_by=added_at&page={}'.format(i) for i in range(1,10)]
start_time1 = time.time()
for url in urls:
get_reping_infoes(url)
end_time1 = time.time()
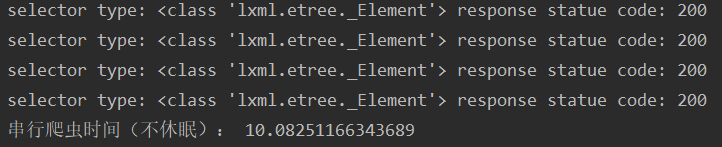
print("串行爬虫时间:",end_time1-start_time1)
start_time2 = time.time()
pool = Pool(processes=2)
pool.map(get_reping_infoes,urls)
end_time2 = time.time()
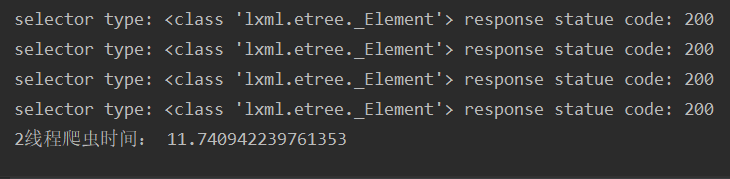
print("2线程爬虫时间:",end_time2-start_time2)
首先想到的是百度,但是翻了几页,都找不到几个跟我类似的情况,就算找到一两个相似的,所提出的方法也不管用。
三、思考和解决问题没办法,只能自己硬着头皮上了。
既然串行爬虫能正常运行,那说明要爬的网页和爬虫函数都是没问题的,问题应该出现在使用多线程库调用爬虫函数的部分。报错说 None类型的对象没有xpath属性。那就是说代码中的 selector 没有xpath属性。为什么 selector 会变成 None,而不是 lxml.etree.Element?
先把 selector 的类型和状态码打出来,奇怪的是,爬的N个网页中竟然也不全是None类型!其中有一部分是正常的Element,状态码也是200。多运行了几次,这种情况竟然是随机的!即有些网页在这一次爬虫运行时是正常的,但是可能下一次就是None了,再看一下 requests.get().text,确实返回的都是空白。为什么会这样呢?完全没有头绪,痛苦~~~~

抓狂了大半天,终于在今晚吃饭时突然灵光一闪,之前看书时看到过爬虫运行太快的话,会因请求网页频率过快而导致爬虫失败爬不到内容,解决方法很简单,在每爬完一次内容时休眠一下就行。
抱着试试无妨的心态,在爬虫函数的最后一行加了一句 time.sleep(1),即上面代码块中被注释的那一句。Bingo!双线程爬虫终于能跑了!感动惨了,哈哈
在这里,串行爬虫不使用休眠也能正常跑,但其他网页就不一定了。在不使用休眠的情况下,串行爬虫会比双线程爬虫(休眠设为1)更快一点。当然,在都休眠的情况下,双线程会比串行快。
注:因本电脑硬件所限,线程数最大只能设为2,睡眠时间设大于1就能正常跑;线程数设大于2都跑不了了。

作者:脑海中的棉花糖