请教各位大侠,这段爬猫眼电影的代码有什么问题?
-- coding: utf-8 --
作者:weixin_46408926
from scrapy.spiders import Spider
from scrapy import Request
class MaoyanSpider(Spider):
name = ‘maoyan’
allowed_domains = [‘maoyan.com’]
maoyan_headers={“User-Agent”:“Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36”}
def start_requests(self):
url="https://maoyan.com/board/4?offset=0"
yield Request(url,headers=self.maoyan_headers)
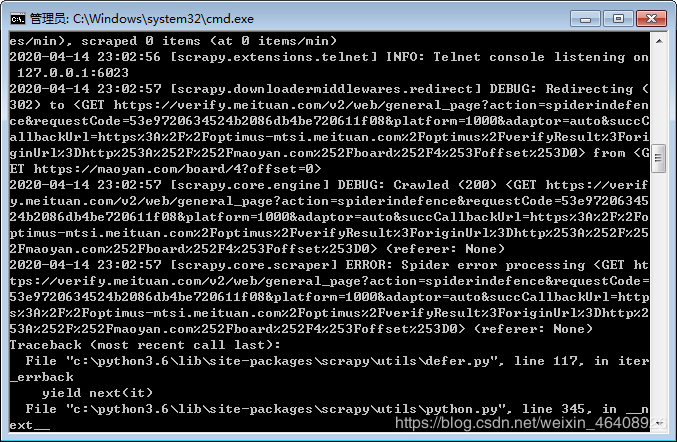
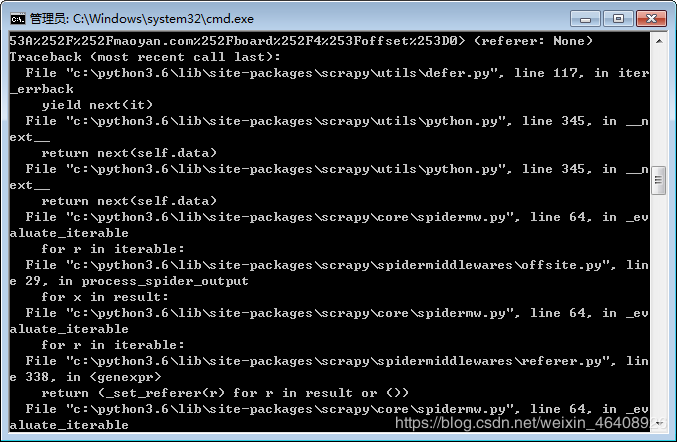
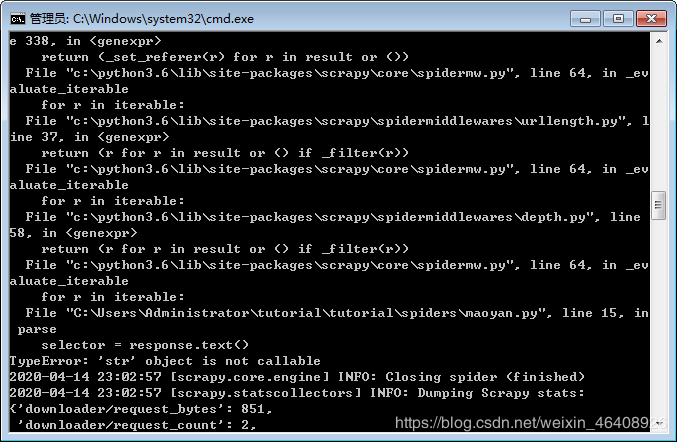
def parse(self, response):
selector = response.text()
print(selector)
for item in selector:
name=item.xpath("div[1]/p[1]/a/text()").extract()[0]
print(name)
star=item.xpath("div[1]/p[2]/text()").extract()[0]
print(star)
releasetime = item.xpath("div[1]/p[3]/text()").extract()[0]
print(releasetime)
score=item.xpath("div[2]/p/i[1]/text()").extract()[0]\
+item.xpath("div[2]/p/i[2]/text()").extract()[0]
hot_dict={"name":name,"star":star,"releasetime":releasetime,"score":score}
yield hot_dict
作者:weixin_46408926