Python获取时光网电影数据的实例代码
一、前言
二、准备
2.1 安装库
2.2 原理介绍
三、实例
3.1 完整代码
一、前言有时候觉得电影真是人类有史以来最伟大的发明,我喜欢看电影,看电影可以让我们增长见闻,学习知识。从某种角度上而言,电影凭借自身独有的魅力大大延长了人类的”寿命”。
一部电影如同一本故事书,我可以沉迷到其中,来的一个新的世界,跟着电影主角去经历去感悟。而好的电影是需要慢慢品尝的,不仅提供了各种视觉刺激和情感体验,更能带来思考点,也让我可以懂得在现实生活中穷尽一生也无法明白的道理。电影比书本更直接、更有趣、更精彩。
好的电影可以在潜移默化中塑造我们的三观,在电影中我们可以获得平静、满足和温和,学会坚强、勇气和努力。电影延展了无聊单调、枯燥又稀松平常的生活,让我可以在对现实生活厌倦或失望时至少有一个地方可以逃离。
正因为电影有诸多好处,并且比书本和说教能更好的塑造三观,因此,家长们可以陪同小孩看电影,鼓励孩子从电影中学会坚强和勇敢等优良品质。
既然要看看电影,就要去看优秀的作品,时光网是一个电影各方面素材都比较全面的网站,本次的项目就是要从该网站上获取到指定年份的所有电影数据,并导出成excel表格以供参考。
注意:请勿使用该技术获取网络上敏感、隐私、非公开等数据。电影推荐(爱情类):
假如爱有天意:缘,妙不可言,或许一切早已注定。
灵魂摆渡·黄泉:为情甘愿赴死,为爱执守千年。
你的名字:世上所有的相遇都是久别重逢。电影推荐(亲子类):
机器人总动员:孩子看到的是友情,大人看到的是爱情。很有爱的一部动画片。
寻梦环游记:死亡并不是终点,被人忘却才是真正的死亡。电影推荐(悬疑类):
小岛惊魂
异次元骇客
恐怖游轮
requests:网络数据请求并获取,安装方式:pip install requests
threading:多线程处理(数据量比较大),Python自带库,无需安装。
json:数据处理,Python自带库,无需安装。
pandas:将数据导出成excel表格,安装方式:pip install pandas
1、先通过requests库,通过时光网自带的电影数据API接口,获取到指定的电影数据。
2、将获取到的数据经过简单的加工,通过pandas库存入到excel表格中。
# Encoding: utf-8
# Author: furongbing
# Date: 2021-11-19 20:54
# Project name: FrbPythonFiles
# IDE: PyCharm
# File name: Mtime
import requests
import pandas as pd
from threading import Thread
import time
import json
# 模块说明:
"""
从时光网上按年代获取指定年份电影的数据
"""
# 更新日志:
"""
1、2021-11-19:
a、完成初版
"""
# 待修改:
"""
"""
# 请求头数据
headers = {"Accept": "application/json, text/plain, */*",
"Accept-Encoding": "gzip, deflate",
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Content-Type': 'application/x-www-form-urlencoded',
'Cookie': '_tt_=FB8A3FAD4704D42543B7EC121C2565AA; __utma=196937584.1082595229.1637326918.1637326918.1637326918.1; __utmz=196937584.1637326918.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); Hm_lvt_07aa95427da600fc217b1133c1e84e5b=1637241042,1637326637,1637374129; Hm_lpvt_07aa95427da600fc217b1133c1e84e5b=1637374170',
'Host': 'front-gateway.mtime.com',
'Origin': 'http://film.mtime.com',
'Referer': 'http://film.mtime.com/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36'
}
pagesize = 20 # todo 获取的每页数据条数,一般建议成默认的20就可以了,设置的太大,每页包含的数据量就大,某一条电影数据出错会导致其它数据也被抛弃。
data = []
error = []
def get_data(p_year=1987): # 按照年份获取当年度所有的电影数据
url = 'http://front-gateway.mtime.com/mtime-search/search/unionSearch2' # 请求的url
params = {'year': p_year, 'pageSize': pagesize, 'pageIndex': 1, 'searchType': 0} # 请求的表单数据
# 获取当年度所有的电影的数量,继而计算要获取多少页
try:
r = requests.get(url=url, params=params, headers=headers, timeout=10)
r.encoding = r.apparent_encoding
all_data = json.loads(r.text)
moviesCount = all_data['data']['moviesCount']
pages = round(moviesCount / pagesize)
except Exception:
moviesCount = 1000
pages = round(moviesCount / pagesize)
# 定义变量
来源 = '时光网'
年代 = p_year
ID, 中文名, 英文名, 类型, 形式, 海报url, 评分, 导演, 主演, 详情, 可播放, 国家地区, 上映日期, 片长, 票房, 观看日期 = [''] * 16
for page in range(pages): # todo 一共要获取多少页
if page % 10 == 0: # 每10页输出一次进度
print(f'已完成 {100 * page / pages:.2f}%')
pageindex = page + 1
params = {'year': p_year, 'pageSize': pagesize, 'pageIndex': pageindex, 'searchType': 0} # 请求的表单数据
try: # 获取指定页的电影数据
r = requests.get(url=url, params=params, headers=headers, timeout=10)
r.encoding = r.apparent_encoding
all_data = json.loads(r.text)
movies = all_data['data']['movies']
# 获取电影具体信息
for movie in movies:
ID = movie['movieId']
中文名 = movie['name']
英文名 = movie['nameEn']
类型 = movie['movieType']
形式 = movie['movieContentType']
海报url = movie['img']
其它译名 = movie['titleOthersCn']
评分 = movie['rating']
导演 = movie['directors']
主演 = movie['actors']
详情 = movie['href']
可播放 = movie['canPlay']
国家地区 = movie['locationName']
上映日期 = movie['realTime']
片长 = movie['length']
info = [来源, 年代, ID, 中文名, 英文名, 类型, 形式, 海报url, 其它译名, 评分, 导演, 主演, 详情, 可播放, 国家地区, 上映日期, 片长, 票房, 观看日期]
data.append(info)
except Exception as err:
er_year, er_pagesize, er_pageindex, er_msg = p_year, pagesize, pageindex, err
error.append([er_year, er_pagesize, er_pageindex, er_msg])
print(f"出错啦,出错年份:{p_year},pagesize:{pagesize},page:{pageindex},出错原因:{er_msg}")
continue
if __name__ == '__main__':
begin = time.perf_counter()
threads = []
for year in range(2020, 2021): # todo 此处可以自定义要获取的年份
t = Thread(target=get_data, args=(year,))
threads.append(t)
t.start()
for t in threads:
t.join()
with open('error.txt', 'w', encoding='utf-8') as f:
f.write(str(error))
data.insert(0, ['来源', '年代', 'ID', '中文名', '英文名', '类型', '形式', '海报url', '其它译名', '评分', '导演', '主演', '详情', '可播放', '国家地区', '上映日期', '片长', '票房', '观看日期'])
df = pd.DataFrame(data)
df.to_excel(excel_writer=r'film.xlsx', sheet_name='sheet1', index=None, header=False) # todo film.xlsx为最后保存的文件名
end = time.perf_counter()
runtime = end - begin
print(f'运行时长:{runtime:.3f}秒。')
输出结果:
已完成 0.00%
已完成 11.63%
已完成 23.26%
已完成 34.88%
已完成 46.51%
已完成 58.14%
已完成 69.77%
已完成 81.40%
已完成 93.02%
运行时长:27.906秒。
虽然示例中获取的是2020年的数据,但是由于代码中采用的是多线程,所以如果是获取一段时间的数据时耗费的时间也和这个差不多。
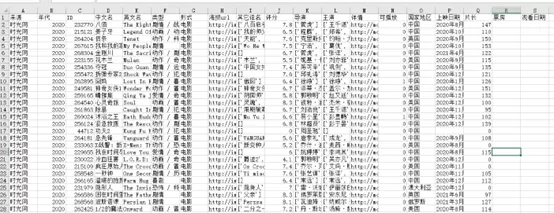
最后保存到excel中的数据如下:
从自动化办公到智能化办公
到此这篇关于Python获取时光网电影数据的文章就介绍到这了,更多相关Python时光网电影内容请搜索软件开发网以前的文章或继续浏览下面的相关文章希望大家以后多多支持软件开发网!