UnOS: Unified Unsupervised Optical-flow and Stereo-depth Estimation by Watching Videos论文解读
本文提出了一个UNOS的框架,即通过光流和深度在刚性场景假设下的内在几何一致性,由CNN来无监督地联合训练光流和深度。它是由来自视频中的连续的图像对,再由UNOS中的三个平行的网络(Stereo Net、Motion Net and Flow Net)来分别估计出深度图、相机自我运动和光流。再由相机的自我运动和深度图就可以计算出刚性光流,然后再与从Flow Net中估计出来的光流作比较;就可以产生满足刚性场景假设的像素。因为要加强在刚性区域内光流和刚性光流之间的几何一致性,所以导出了一个rigid-aware direct visual odometry( RDVO)模块。当然在UNOS的学习中,也考虑到了刚性和遮挡感知流一致性。
介绍:本文主要是由无监督的方法来联合学习光流和深度,通过它们之间的几何一致性来训练参数。而许多其他的论文都是分开学习和训练光流和深度的。UNOS的大体结构框架如下图所示:
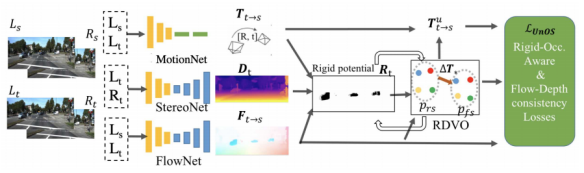
在训练期间,会从视频中获取连续的两对图像对Ls、Rs和Lt、Rt。UNOS将会从Motion Net 、Stereo Net和Flow Net中估计出深度图Dt、相机的自我运动Tt_s和光流Ft_s。然后RDVO将会在Motion Net之后,用来细化并且更新相机的自我运动Tt_s;然后再用深度图Dt和通过RDVO更新后的Tt_s来计算刚流,此时的刚流仅仅是由于相机的自我运动产生的。再把此时产生的刚流与刚才的从Flow Net估计出来的光流Ft_s进行比较,就可以产生一个刚性掩模M(相当于把非刚性都给掩模掉了)。每个网络除了有自己的Loss以外。与Ft_s在刚性区域M内,会保持一致性;利用这个关系可以用约束网络,使得网络估计出来的值更有效。
1.自我监督
(1)找到相应的像素
对于目标图像中的像素Pt可以通过下面3个公式来实现:
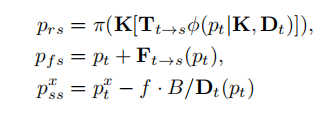
Prs是由目标图像中的像素通过wrapping得到的。
Pfs是由目标像素加上光流得到的;因为目标图像和源图像之间差的就是光流。
而fB/Dt(Pt)是表示水平方向的视差。是表示的左图像素,它是由右图()减去视差得到的。因为在同一水平方向上,左右视图之间就是差了视差。
(2)视图合成作为监督信号
我们通过刚上面的3个公式可以仅仅由网络估计出的一些相关的值(Pose、深度、光流等)和图片1上的像素来计算出图片2上的像素。为了验证由图片1计算出的图片2的真实性。我们一般都是用真实的图片2与计算出来的图片2作差。当然我们肯定是希望这个差是零,所以我们可以根据这个来作为一个约束,其公式如下:
 公式中的号分别是r,f,s.分别对应(1)的三个公式中计算出来的值。
公式中的号分别是r,f,s.分别对应(1)的三个公式中计算出来的值。
2.RDVO简介
局部感性软掩模指的是:在这个区域内的所以像素都满足刚性场景假设的条件。即是前提到过的掩模M。M的计算公式如下:其中M=Rt(Pt)

在RDVO中。最开始已经有了Dt、光流Ft_s,还有Motion Net估计出来的相机自我运动Tt_s,而作者希望通过RDVO来找到一个相关的来更新细化相机的自我运动Tt_s。而计算可以通过(1)的公式来算:

公式中的h(t)是pt的齐次坐标;而在RDVO之后相机的自我运动更新完以后变成了:,再用经过RDVO更新过后相机自我运动去计算Prs,再代入公式:
![]()
经过训连再一直不断的更新,最后可以产生一个刚性分割掩模的阈值,来区分静态背景和运动物体的区域。
所以说RDVO的作用就是:可以更新相机的参数(pose),然后再反馈回去重新计算Pfs,然后再重新计算R(t)产生一个阈值, 以便于区分静态背景和运动物体的区域。
3.损失函数
为了更好检测两张图片的相似度,以便于刚好约束网络进行训练,像素匹配采取了下面的Loss:

对于监督深度,Lt是来自Pss, Vs是用视差计算的。监督光流,Lt是来自于Pfs, Vf是由反向光流Fs_t来计算的;为了监督连续的图像对,L*t是来自Prs(在RDVO之前),而Vr代表的是刚性和非遮挡的区域,它的计算是
![]()
用来分别代表不同的视图合成的Loss.
边缘感知局部Loss是:

对于深度用来表示。对于光流用来表示。
在RDVO更新完相机的自我运动的参数(pose)之后,用更新完后计算的刚流和光流具有一致性在满足刚性场景假设的条件下,所以它的Loss为:
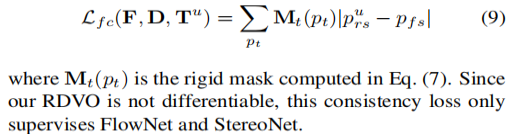
最后再加入左右一致性,加上前面的这些Loss,那么整个UNOS的Loss为:
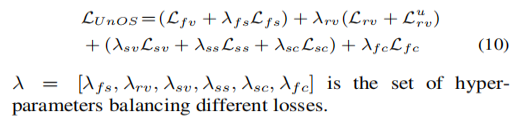
其中:
Lfv是光流的像素匹配的Loss,
Lfs是光流的边缘感知局部Loss
Lrv是相机自我运动(在RDVO之前)计算刚流的像素匹配的Loss
是相机自我运动(在RDVO之后)计算刚流的像素匹配的Loss
Lsv是深度的像素匹配的Loss,Lss是深度边缘感知局部的Loss,Lsc是左右一致性的Loss。
Lfc是在RDVO更新完相机的参数再反过来计算出的刚流 和 光流一致性的Loss。
这篇论文的主要就是把相机的自我运动,深度和光流最后动通过RDVO来联合起来一起训练。它的训练主要是分成了三个阶段:第一阶段是先单独训练Flow Net出来的光流,把这个作为它的base-line;然后第二阶段再训练Motion Net 和Stereo Net ,这个是在RDVO之前的。先在这两个阶段训练取得了一定的合理的光流和深度的时候;最后再加上RDVO,联合一起进行总的训练。
总得来说,这篇文章,就是先用了Motion Net 估计出一个相机的自我运动,和Motion Net估计出深度图,再用RDVO来细化更新相机的运动。这样再把细化过后和相机运动和深度一起计算出刚流,再在刚性掩模的基础上,让光流和刚流相等,以此来约束模型的训练。当然这只是其中的一个约束。但是我觉得这是最重要的一个约束,就是因为它才让三个网络联合在一起训练。
作者:春江水暖谁先知