【Scrapy爬虫项目】爬取books.toscrape.com上书籍的相关信息并存储为csv文件
此处准备使用Scrapy爬虫框架对 http://books.toscrape.com/(一个专门用来被爬取的网站)上书籍的相关信息进行爬取。
相关信息包括:书名、价格、评价等级、库存量、产品编码、评价数量。
这里补充一下,通常现在的浏览器都会对html文本进行一定的规范化, 所以在使用Chrome等浏览器自带的XPath路径的时候, 有可能会导致读取失败。
虽然很多时候用view命令加载出的页面和浏览器打开的是一样的,但是前者是Scrapy爬虫下载的页面,后者是由浏览器下载的页面,有时它们是不同的。
在进行页面分析时,使用view命令更加可靠:
在命令提示符窗口输入
scrapy shell url
view(response)
然后就打开了Scrapy爬虫下载的页面,此时在F12开发者工具中看的路径就是原始路径。
这里我们以第一本书为例进行分析:
首先输入scrapy shell http://books.toscrape.com/catalogue/a-light-in-the-attic_1000/index.html

运行这条命令后,scrapy shell会使用url参数构造一个Request对象,并提交给Scrapy引擎,页面下载完成后,程序进入Scrapy终端,在此环境中已经创建好了一些变量(对象和函数),我们可以在这里调试爬取代码。
状态码为200,表示请求成功:
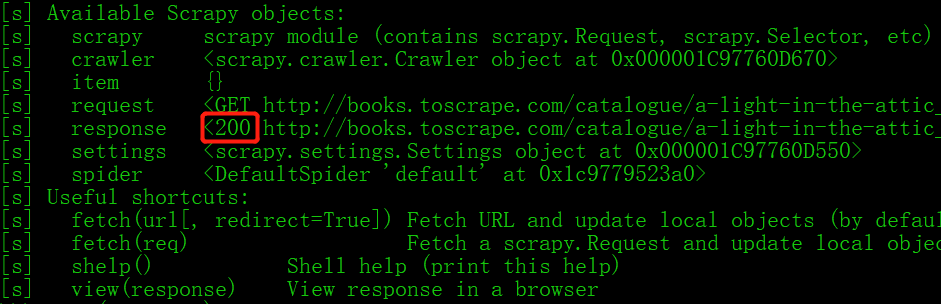
然后输入view(response)
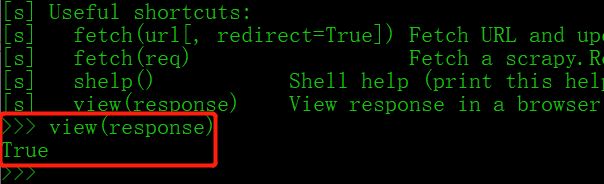
然后就自动打开页面了:
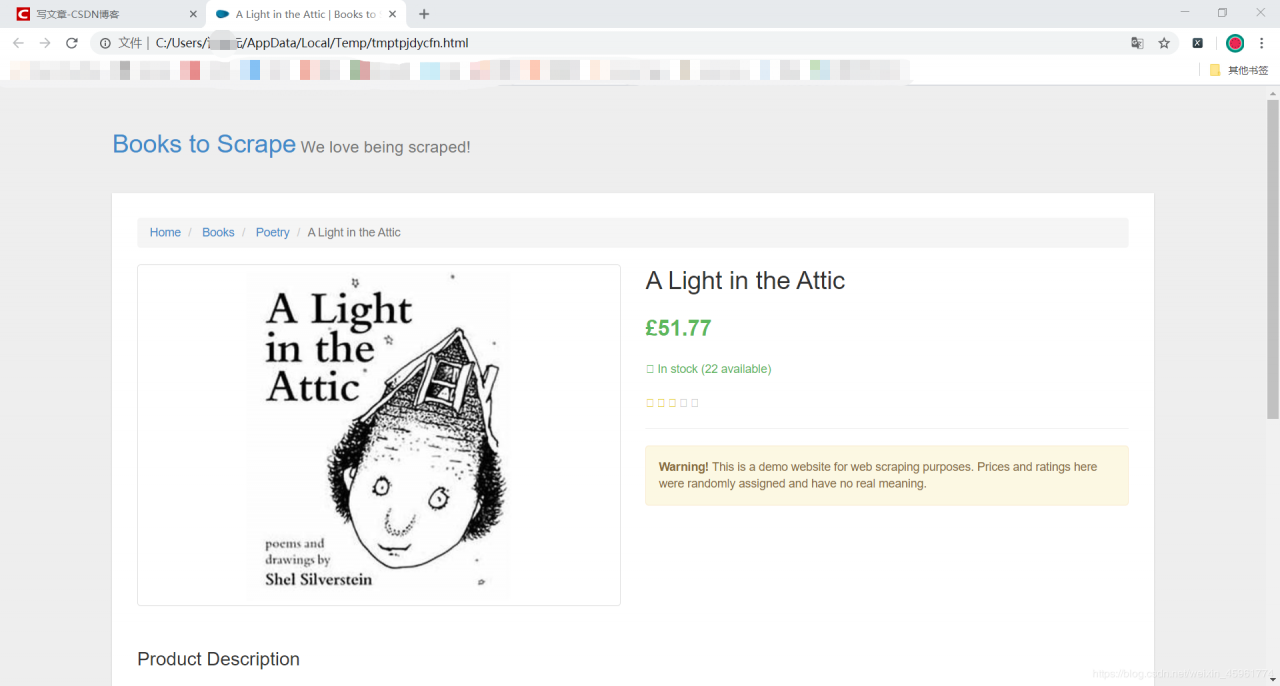
(XPath Helper 的安装教程在我的文章中有,辅助工具专栏)
首先是书名:
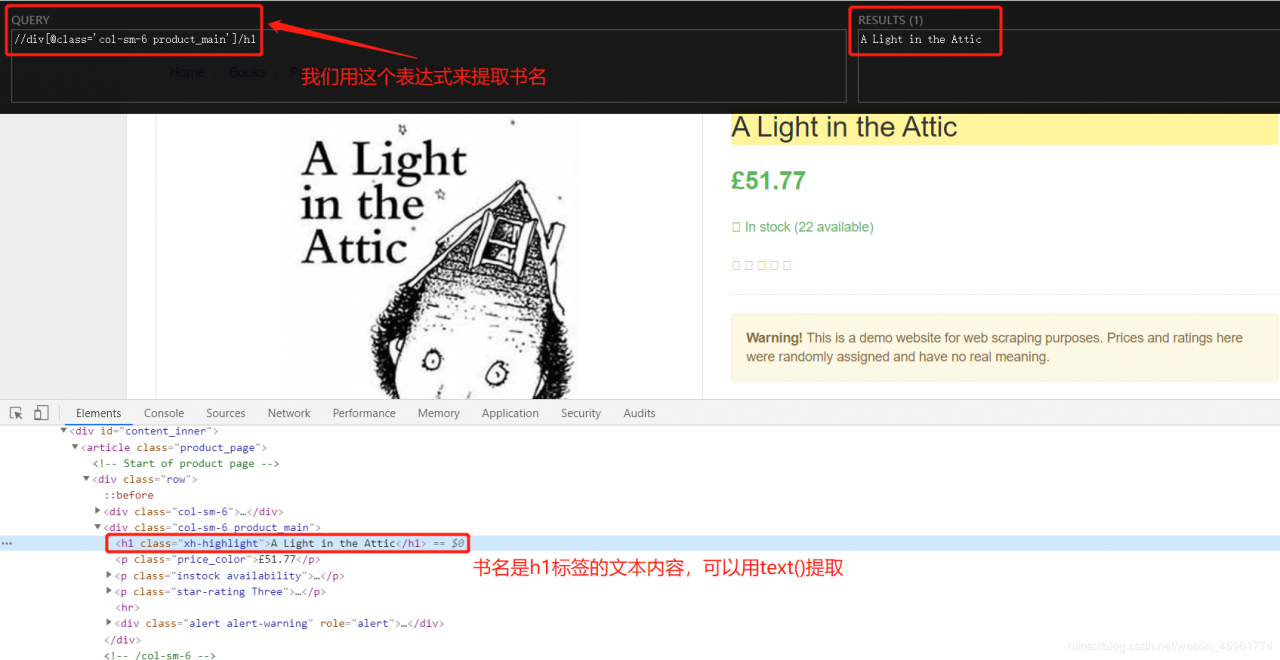
在Scrapy终端里测试一下:

extract()与extract_first()区别:
extract()返回的所有数据,存在一个list里。
extract_first()返回的是一个string,是extract()结果中第一个值。
接下来是价格:
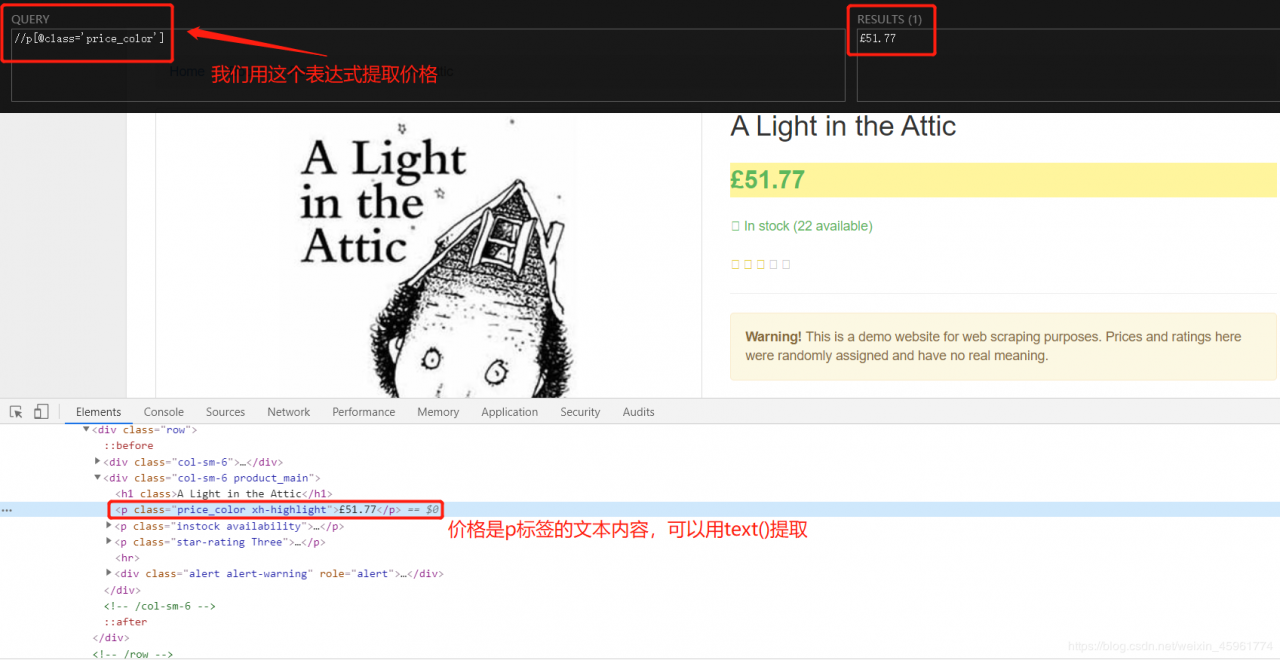
然后是评价等级:
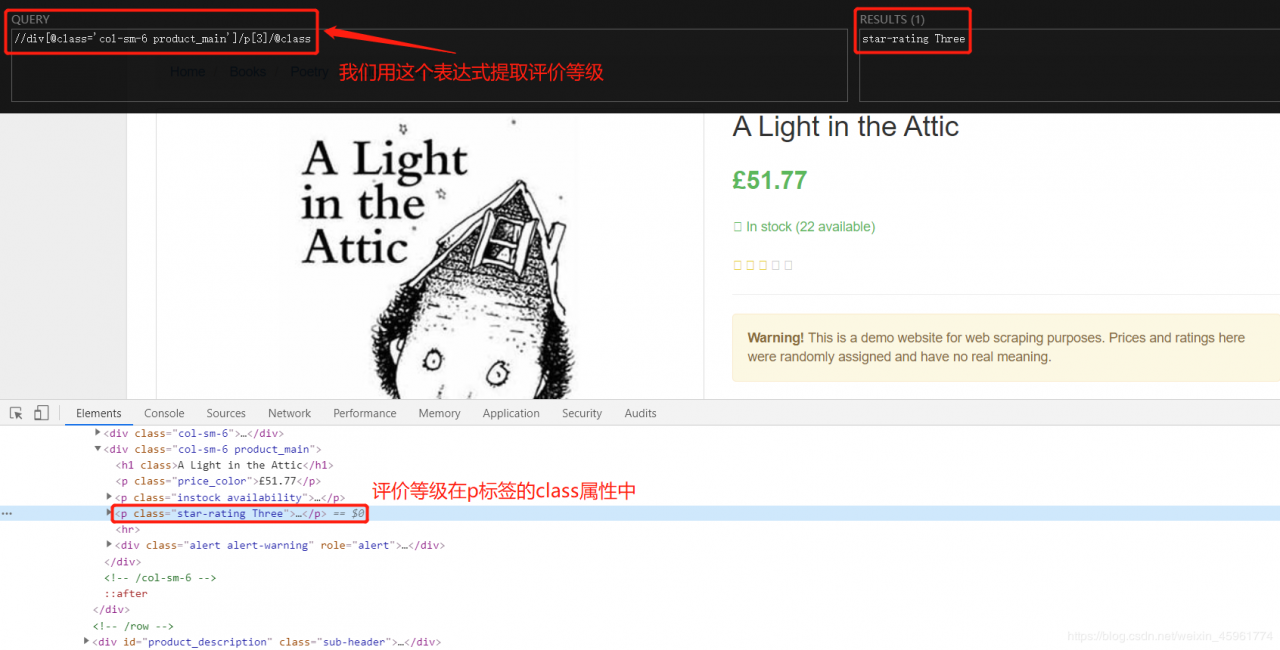
我们用正则表达式去除字符串中的star-rating:

接下来是库存量:
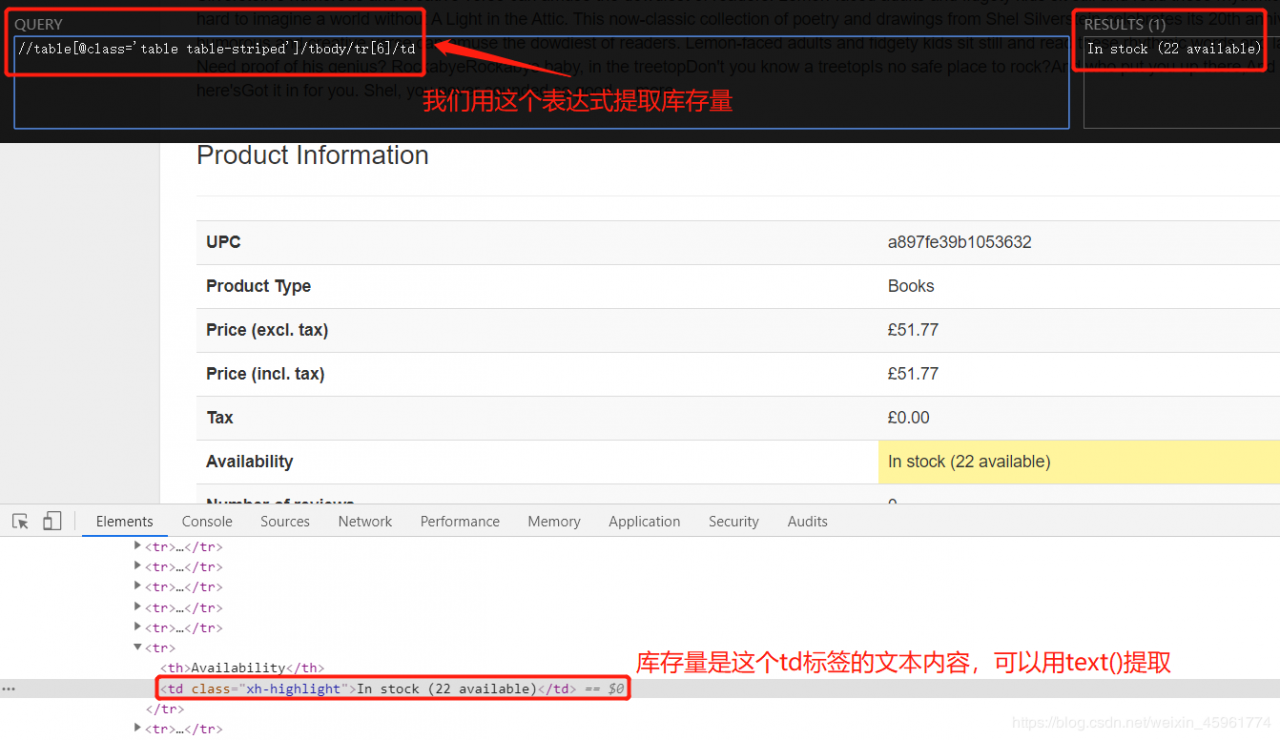
我们依然使用正则表达式对库存量进行提取:

这里我们会发现,按照我们直接分析的XPath是提取不到内容的,我们得删去tbody标签,为什么呢?
因为浏览器本身自动为table新增了tbody标签内容,但是在xpath中是不需要的(试试看把tbody标签去掉,依然表示对应的信息),需要在进行xpath查询之时移除掉。
然后是产品编码:
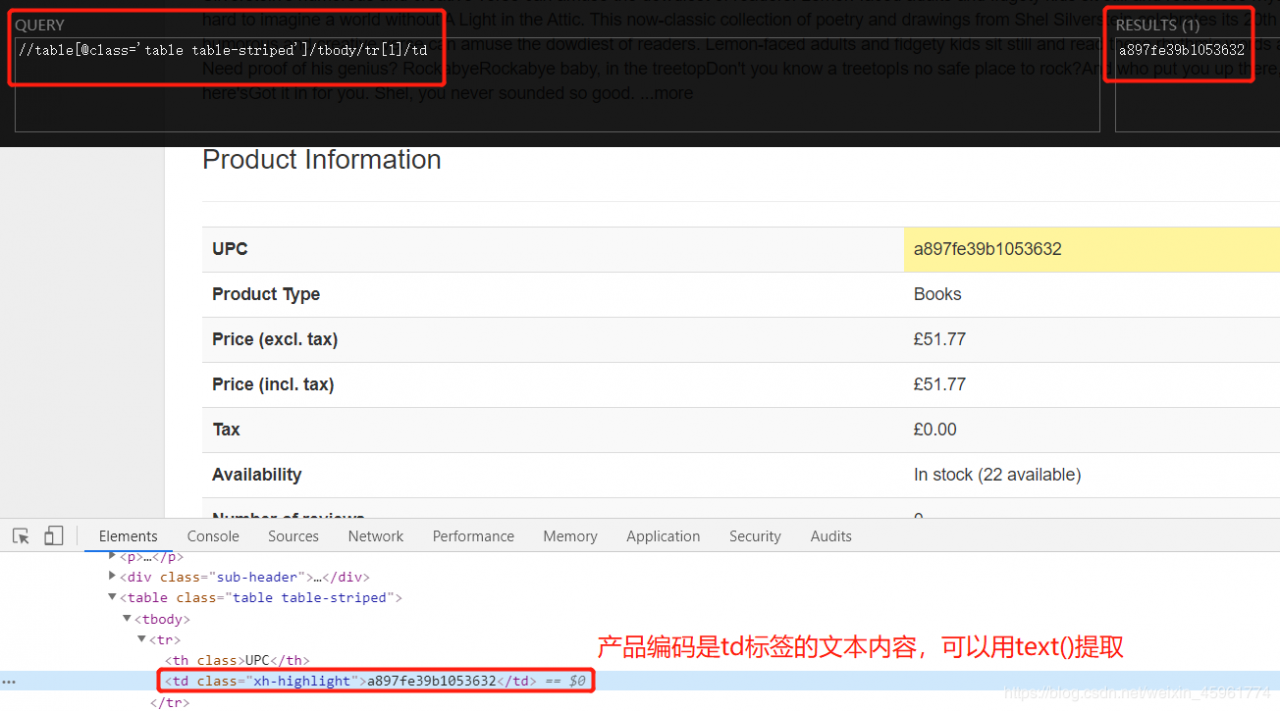
同理,我们可以这样提取:

最后是评价数量:
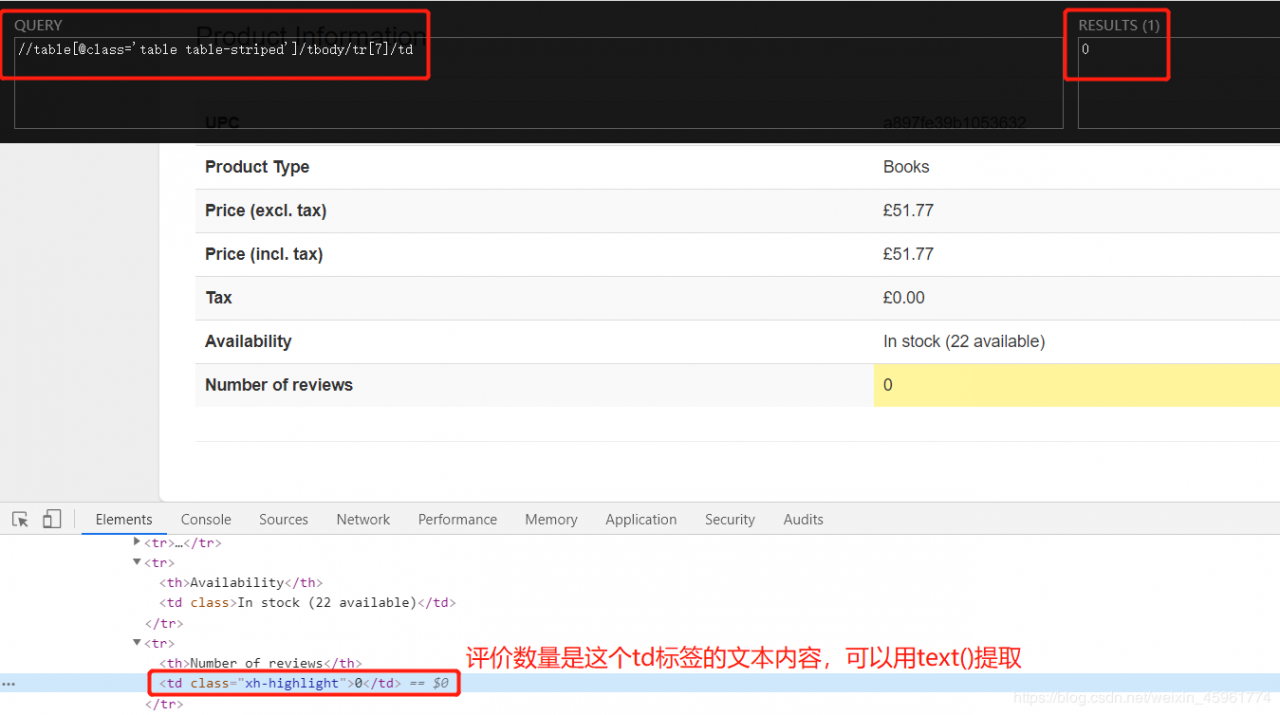
同理,我们可以这样提取:

至此,我们已经分析完了一本书的页面,接下来我们考虑一下如何获取一个页面所有书籍的链接以及获取下一页的链接。
首先我们使用fetch命令下载书籍列表页面,然后用view命令打开页面进行分析:

经过分析,一个页面所有书籍的链接如下:
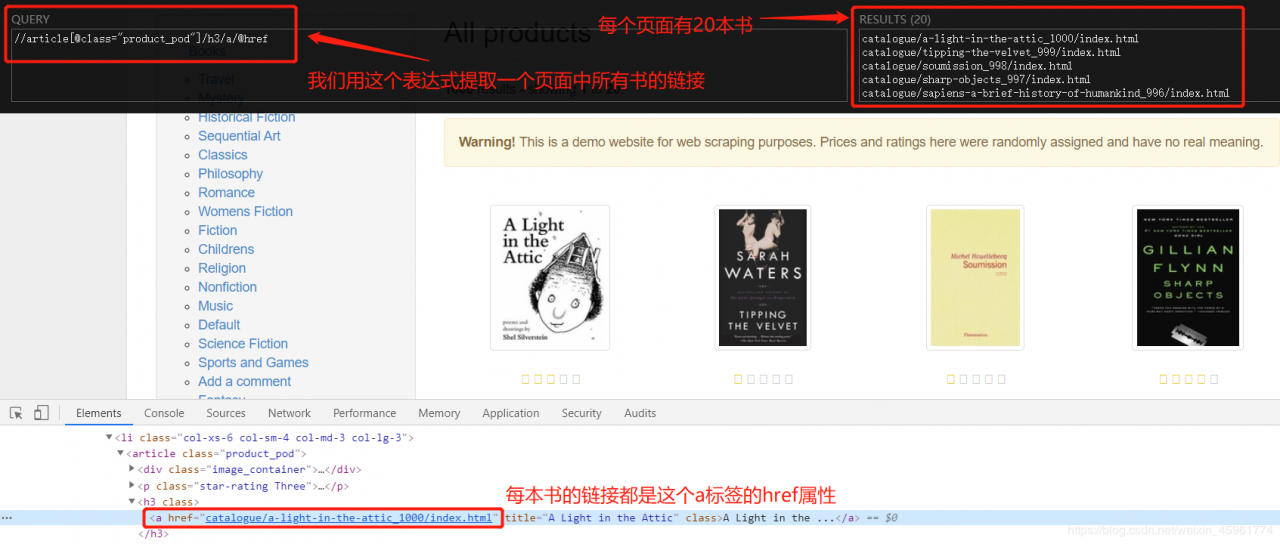
接下来分析下一页的链接:
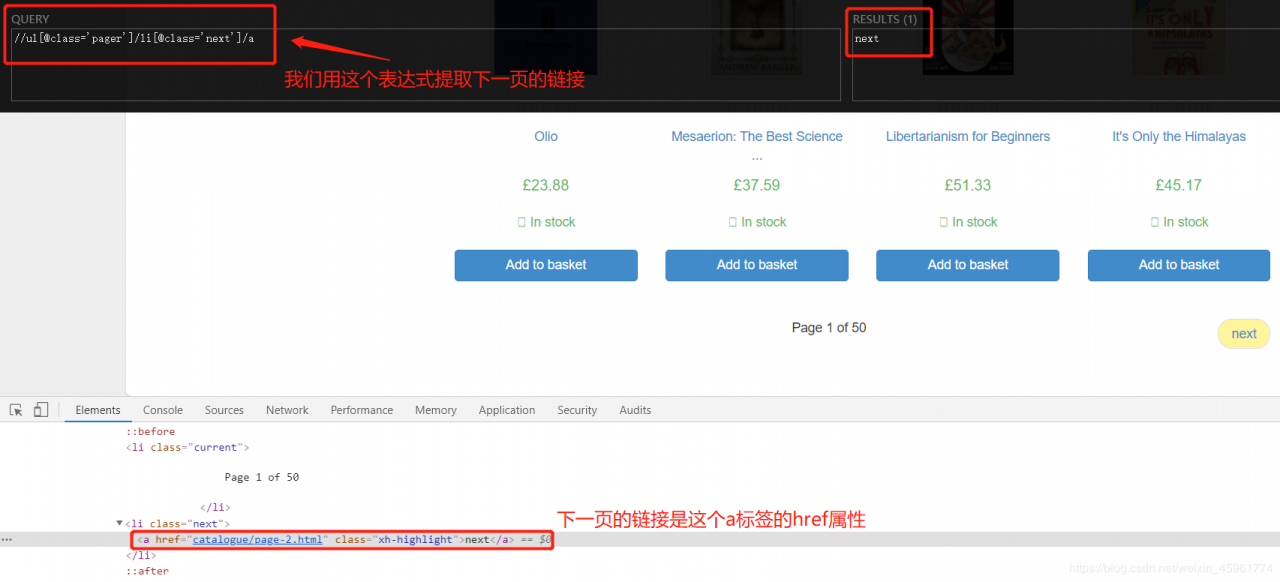
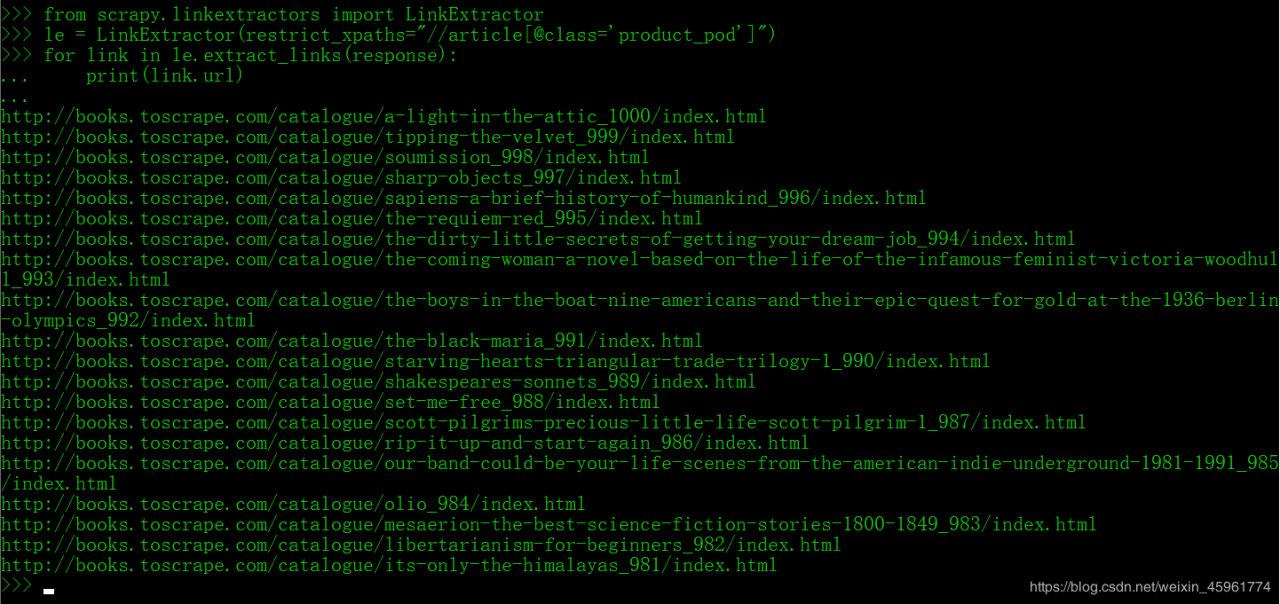
然后我们使用LinkExtractor提取这些链接:
因为href中的链接跟该站点有联系,直接获取出来的不是绝对url,需要拼接计算。
如 catalogue/page-2.html 是标签中的内容,而正确地址为 http://books.toscrape.com/catalogue/page-2.html
我们分析一下如何提取一个页面中所有书的绝对链接:
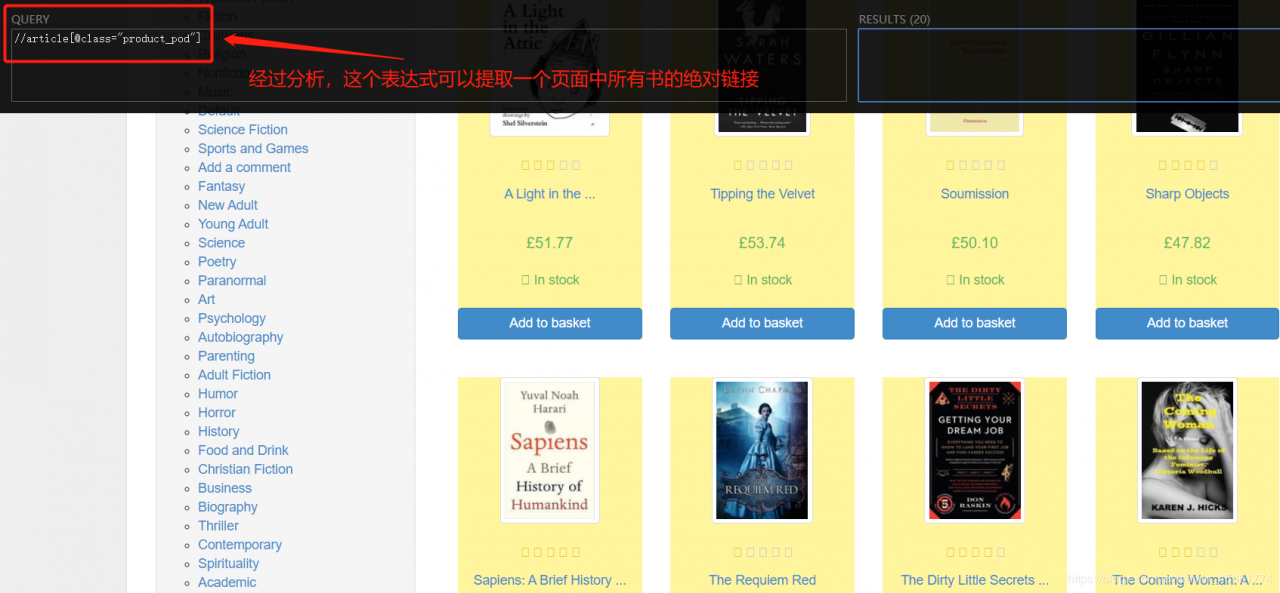
接下来用Scrapy终端测试一下:
这里有个细节要注意,在使用双重引号的时候,要么外面是双引号,里面是单引号;要么反过来。否则就会报错:SyntaxError: invalid syntax
然后用Scrapy终端测试下一页的链接:
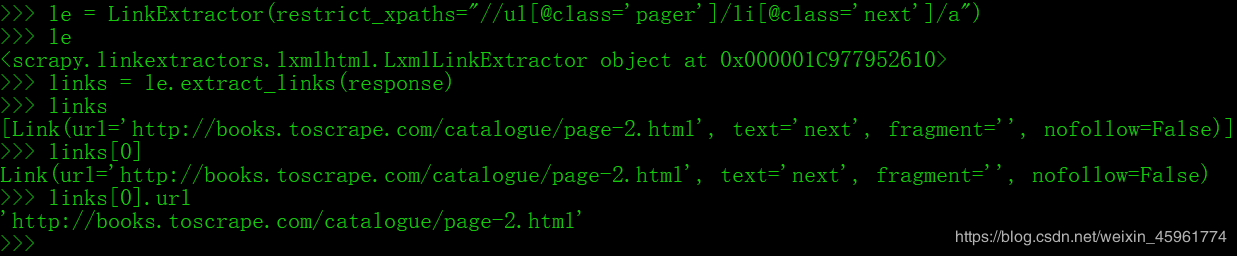
这里详细分析一下这些对象:
le 是 LinkExtractor对象,起到选择器作用,定义选取规则
links 是 le 调用 extract_links方法,传入当前页面 response,在当前页面中根据 le规则寻找 links,返回Link对象组成的列表
links[0]是一个 Link对象
links[0].url 是对象的一个属性,即我们要的绝对url地址(无需再拼接计算)
接下来我们就开始创建Scrapy爬虫工程:此处使用 Pycharm 实现,首先在 Pycharm 创建一个新的项目 MyScrapy:
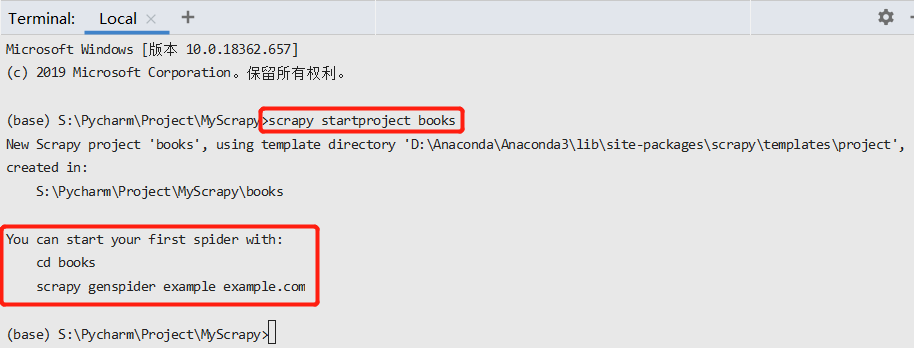
接下来打开 Pycharm 的终端 Terminal,输入scrapy startproject books创建一个Scrapy爬虫项目:
然后进入 books目录,输入scrapy genspider books_spider books.toscrape.com创建 Spider文件以及 Spider类:

在实现 Spider 之前,先定义封装书籍信息的 Item类,在 items.py 中添加如下代码:
# 书籍项目
class BooksItem(scrapy.Item):
name = scrapy.Field() # 书名
price = scrapy.Field() # 价格
review_rating = scrapy.Field() # 评价等级
review_num = scrapy.Field() # 评价数量
upc = scrapy.Field() # 产品编码
stock = scrapy.Field() # 库存量
接下来我们在爬虫类中要实现两个页面解析函数,一个是每一页的页面解析函数,一个是每本书的页面解析函数,打开 books.py,根据我们前面的分析,编辑代码如下:
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from ..items import BooksItem # ..表示上级目录
class BooksSpider(scrapy.Spider):
name = 'books'
allowed_domains = ['books.toscrape.com']
start_urls = ['http://books.toscrape.com/']
# 每一页的页面解析函数
def parse(self, response):
# 提取当前页面所有书的url
le = LinkExtractor(restrict_xpaths='//article[@class="product_pod"]')
for link in le.extract_links(response):
yield scrapy.Request(url=link.url, callback=self.parse_book)
# 提取下一页的url
le = LinkExtractor(restrict_xpaths='//ul[@class="pager"]/li[@class="next"]/a')
links = le.extract_links(response)
if links:
next_url = links[0].url
yield scrapy.Request(url=next_url, callback=self.parse)
# 每一本书的页面解析函数
def parse_book(self, response):
book = BooksItem() # 将信息存入BooksItem对象
book['name'] = response.xpath('//div[@class="col-sm-6 product_main"]/h1/text()').extract_first()
book['price'] = response.xpath('//p[@class="price_color"]/text()').extract_first()
book['review_rating'] = response.xpath('//div[@class="col-sm-6 product_main"]/p[3]/@class') \
.re_first('star-rating ([A-Za-z]+)') # \是续行符
book['stock'] = response.xpath('//table[@class="table table-striped"]//tr[6]/td/text()').re_first('\((\d+) available\)')
book['upc'] = response.xpath('//table[@class="table table-striped"]//tr[1]/td/text()').extract_first()
book['review_num'] = response.xpath('//table[@class="table table-striped"]//tr[7]/td/text()').extract_first()
yield book
此处是优化步骤:
接下来配置文件 settings.py,使用 FEED_EXPORT_FIELDS 指定各列的次序:
FEED_EXPORT_FIELDS=['upc','name','price','stock','review_rating','review_num']
另外,评价等级字段的值是One、Two、Three……这样的英语单词,我们可以将它们改为阿拉伯数字,下面实现一个 Item Pipeline,将单词映射到数字。在 pipelines.py 中实现 BookPipeline,代码如下:
class BooksPipeline(object):
review_rating_map = {
'One': 1,
'Two': 2,
'Three': 3,
'Four': 4,
'Five': 5,
}
def process_item(self,item,spider):
rating = item.get('review_rating')
if rating:
item['review_rating'] = self.review_rating_map[rating]
return item
然后在配置文件 settings.py 中启用 BooksPipeline:
ITEM_PIPELINES = {
'books.pipelines.BooksPipeline': 300,
} # books是 Scrapy爬虫项目的名字
最后运行整个爬虫项目:
在 Pycharm终端输入scrapy crawl books_spider -o books.csv --nolog:
这里加上 - -nolog 就可以不显示运行日志

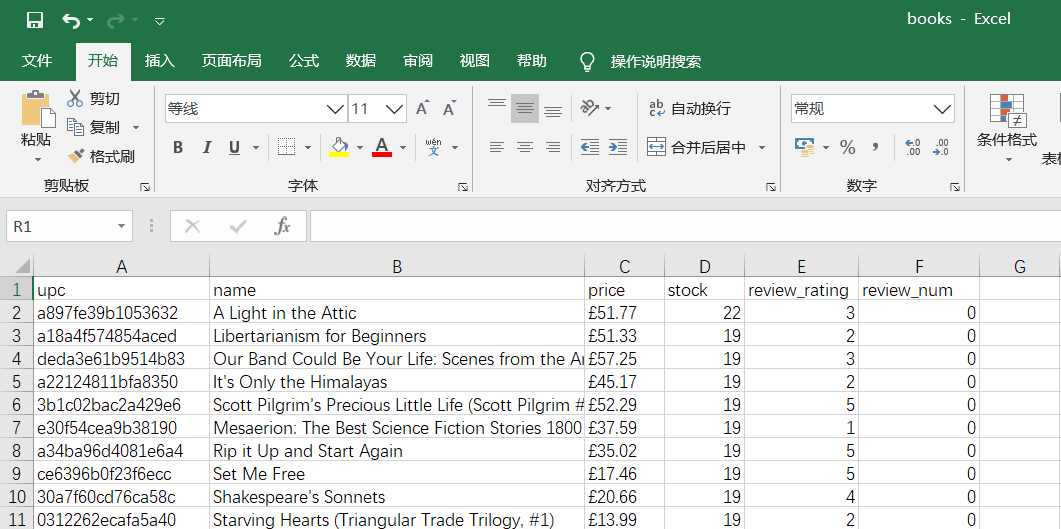
至此,整个爬虫项目就完成了。
作者:Giyn