解决sklearn中使用OrdinalEncoder编码测试集的类别特征中的未知类别时会报错的问题
当数据集中存在类别特征时(categorical/discrete features),我们一般的想法是将其转变为数值型的特征,比如如果是不存在内在高低顺序的类别特征,便可以使用sklearn中的OneHotEncoder方法将其转变为数值型的特征,但是OneHotEncoder也会令数据集中的特征数量激增,以至于模型复杂度升高。
而另一种将类别特征转变为数值型特征的方法则为OrdinalEncoder。OrdinalEncoder方法的一个特点是其可以根据标签y来对类别特征进行顺序编码,比如[ [“北京”, 9], [“上海”,11], [“深圳”, 8] ]这个数据中,第一个特征为地点类别特征,第二个假设为标签,在这里可以看出不同的地点其标签是有顺序上的差异的,这种情况下的类别特征就很适合使用OrdinalEncoder方法来进行数值型编码。
但是sklearn中的OrdinalEncoder方法根据训练集的数据调用其内部的fit_transform()函数进行拟合之后,如果在用其对测试集中的类别特征进行数值型编码转换时,测试集的类别特征中有未知类别(即训练集中此类别特征中未出现过的类别)时,OrdinalEncoder方法内的transform函数则会报错。sklearn中的OrdinalEncoder方法如下所示,在初始化时是没有指定怎么处理测试集中未见类别的参数的 (而OneHotEncoder方法在初始化时则有指定处理测试集中未见类别的参数)。
解决这个问题的方法可以从OrdinalEncoder的源码中找到, OrdinalEncoder方法中的transform函数如下所示:

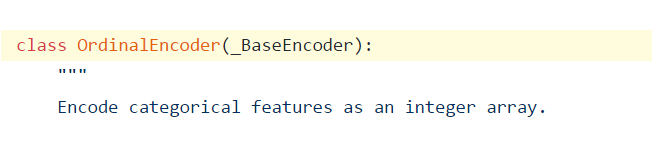
从上图可以看出OrdinalEncoder类中的transform函数是直接调用OrdinalEncoder类的父类中的self._transform()函数以及一些后续操作来对测试集中的类别特征进行转化的,而OrdinalEncoder类则是继承自_BaseEncoder类:
因此去查看_BaseEncoder类中的_transform()函数时可以发现其实_BaseEncoder类中的_transform()函数中是有指定怎么处理测试集中未见类别的参数 handle_unknown 的,如下图:

从_BaseEncoder类中的_transform()函数源码中可以看出,当将handle_unknown参数由"error"值改成别的任意值时,测试集类别特征中的未见类别将被编码为0,而不是直接报错。
因此当使用OrdinalEncoder去对含有未见类别特征的测试集进行编码时,可以不使用OrdinalEncoder类中的transform()函数,而是直接调用OrdinalEncoder类所继承的_BaseEncoder类中的_transform()函数来对测试集进行编码。此时_transform()函数返回的为一个元组对象,这个元组对象中的第一个元素为我们想要的对于测试集的编码结果;而第二个元素则为编码过程中的副产品mask矩阵,可以舍弃。再对测试集的编码结果进行astype()操作,最后得到的即为最终的测试集编码结果。
详细操作代码如下:
初始化训练集与测试集:
from sklearn.preprocessing import OrdinalEncoder
import pandas as pd
import numpy as np
train_data = [["北京","互联网" ,9],
["北京","金融" ,10],
["上海","金融" ,11],
["深圳","互联网" ,8],
["广州","互联网" ,7.5],
["天津","银行" ,6],]
test_data = [["杭州","金融"],]
train = pd.DataFrame()
test = pd.DataFrame()
for item in train_data:
train = train.append({"location": item[0], "occupation": item[1], "salary":item[2]}, ignore_index=True)
for item in test_data:
test = test.append({"location": item[0], "occupation": item[1]}, ignore_index=True)
# OrdinalEncoder()先拟合训练集
ordinal_encoder = OrdinalEncoder()
train = ordinal_encoder.fit_transform(X=train.iloc[:,0:-1], y=train.iloc[:,-1])
当用OrdinalEncoder类中的transform()函数对含有未见类别特征的测试集进行编码时,会报如下错误,可以看出测试集的地点特征中的 “杭州” 为未见类别。
test = ordinal_encoder.transform(test)
# 报错如下
ValueError Traceback (most recent call last)
in
----> 1 test = ordinal_encoder.transform(test)
2 test
/opt/conda/lib/python3.7/site-packages/sklearn/preprocessing/_encoders.py in transform(self, X)
955
956 """
--> 957 X_int, _ = self._transform(X)
958 return X_int.astype(self.dtype, copy=False)
959
/opt/conda/lib/python3.7/site-packages/sklearn/preprocessing/_encoders.py in _transform(self, X, handle_unknown)
120 msg = ("Found unknown categories {0} in column {1}"
121 " during transform".format(diff, i))
--> 122 raise ValueError(msg)
123 else:
124 # Set the problematic rows to an acceptable value and
ValueError: Found unknown categories ['杭州'] in column 0 during transform
当使用OrdinalEncoder类所继承的_BaseEncoder类中的_transform()函数,令handle_unknown参数为 ‘ignore’ ,再对测试集的编码结果进行astype()操作,结果如下:
test = ordinal_encoder._transform(test, handle_unknown='ignore')[0].astype(np.float64, copy=False)
test
# 结果如下
array([[0., 1.]])
可以看出_transform()函数将测试集中地点类别特征中的未见类别 “杭州” 可以编码为0,而不会直接报错。
以上过程即为解决方法, 在最后再重复强调一下解决办法:
使用OrdinalEncoder去对含有未见类别特征的测试集进行编码时,可以不使用OrdinalEncoder类中的transform()函数,而是直接调用OrdinalEncoder类所继承的_BaseEncoder类中的_transform()函数来对测试集进行编码。此时_transform()函数返回的为一个元组对象,这个元组对象中的第一个元素为我们想要的对于测试集的编码结果;而第二个元素则为编码过程中的副产品mask矩阵,可以舍弃。再对测试集的编码结果进行astype()操作,最后得到的即为最终的测试集编码结果。
作者:料理菌