Hadoop概述及CentOS安装和使用
Hadoop是一个分布式系统基础架构,用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算。
1.HDFSHDFS是一个分布式文件系统,且是一个高度容错性的系统,适合部署在廉价的机器上。HDFS采用master/slave架构。一个HDFS集群是由一个Namenode和一定数目的Datanodes组成服务器。Namenode是一个中心服务器,负责管理文件系统的名字空间(namespace)以及客户端对文件的访问。集群中的Datanode一般是一个节点一个,负责管理它所在节点上的存储。
2.MapReduce最简单的 MapReduce应用程序至少包含 3 个部分:一个 Map 函数、一个 Reduce 函数和一个 main 函数。main 函数将作业控制和文件输入/输出结合起来。在这点上,Hadoop 提供了大量的接口和抽象类,从而为 Hadoop应用程序开发人员提供许多工具,可用于调试和性能度量等 。MapReduce 本身就是用于并行处理大数据集的软件框架。MapReduce 的根源是函数性编程中的 map 和 reduce 函数。它由两个可能包含有许多实例(许多 Map 和 Reduce)的操作组成。Map 函数接受一组数据并将其转换为一个键/值对列表,输入域中的每个元素对应一个键/值对。Reduce 函数接受 Map 函数生成的列表,然后根据它们的键(为每个键生成一个键/值对)缩小键/值对列表。
二.准备工作 1.安装虚拟机软件 Vmware Workstation Pro直接到官网下载合适的版本: VMware官网.第一次运行会要求输入密钥,密钥直接百度即可。
2.安装Linux操作系统(CentOS7.4) 下载CentOS镜像文件1 进入CentOS官网,找到7.4版本对应的文件夹,进入/isos/x86_64/,然后下载CentOS-7-x86_64-DVD-1708.torrent

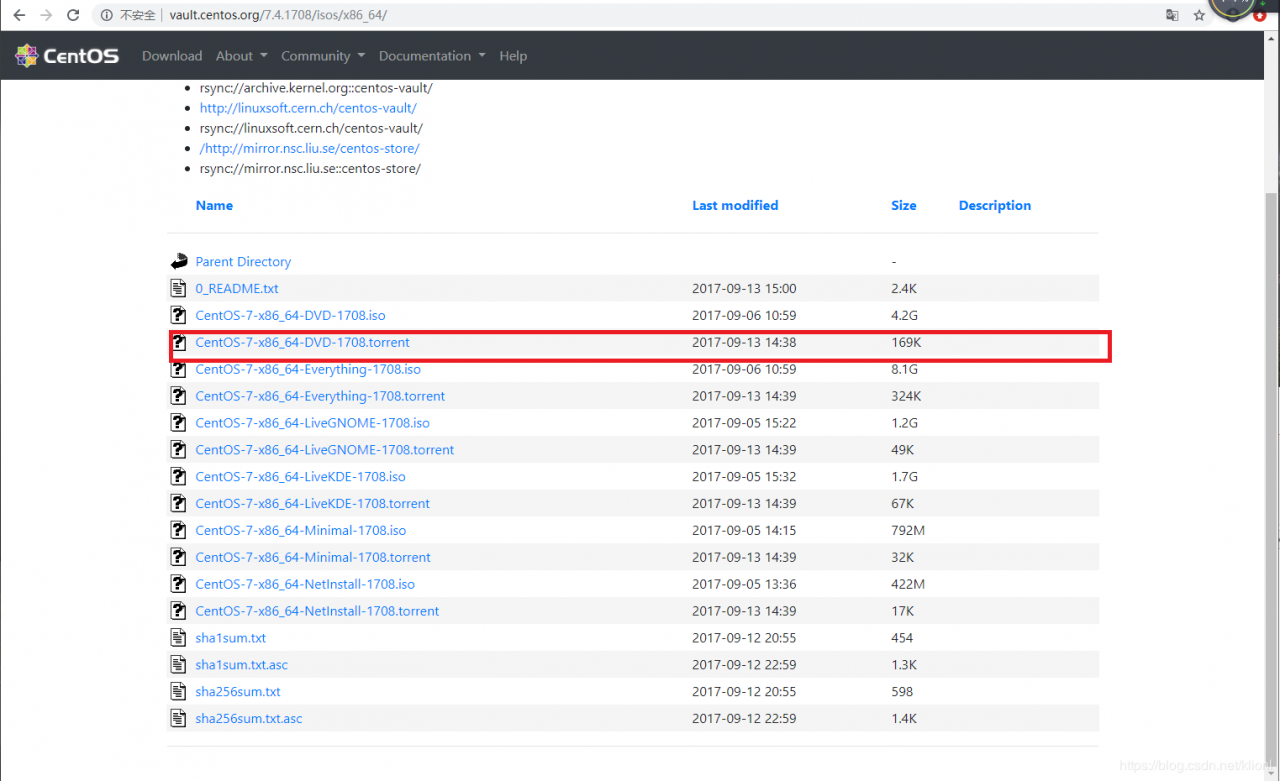
2 这里的CentOS-7-x86_64-DVD-1708.torrent只是一个BT种子,我们需要用迅雷对其重新下载得到镜像文件CentOS-7-x86_64-DVD-1708.iso
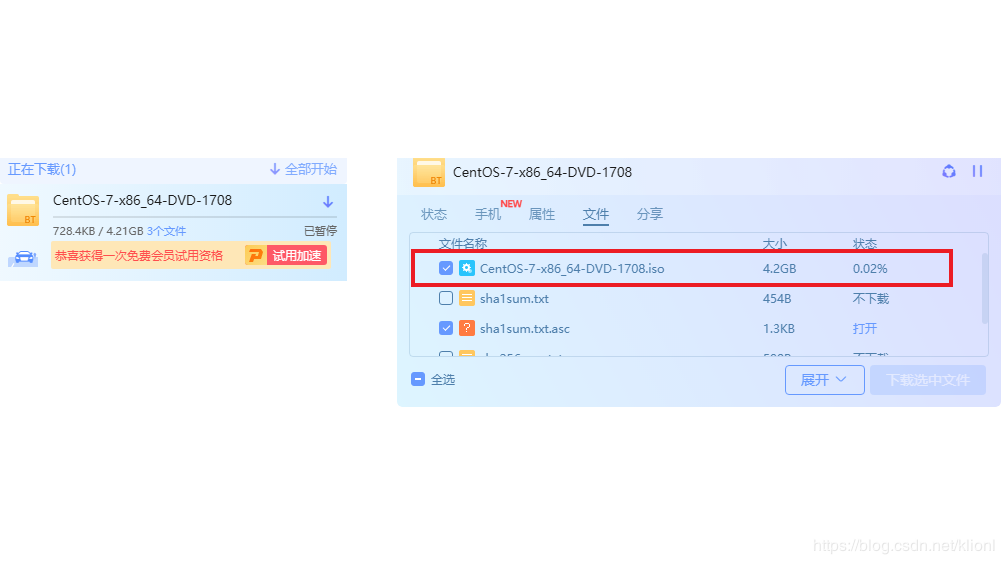
参考https://blog.csdn.net/qq_39135287/article/details/83993574
1 打开VMware,选择创建新的虚拟机,选择典型,下一步,稍后安装操作系统
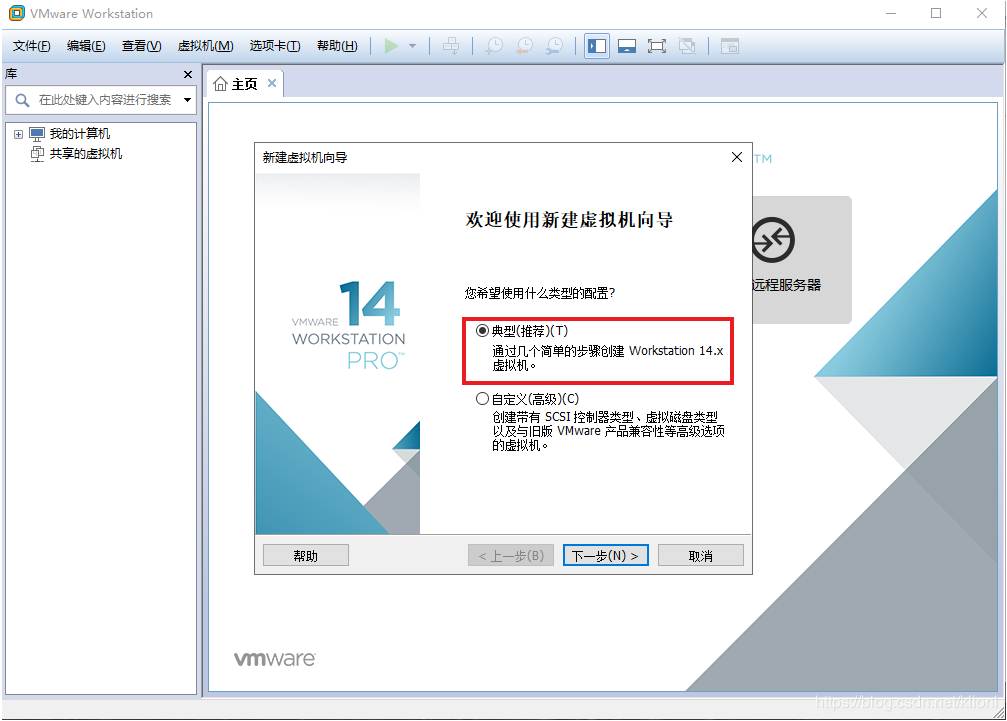
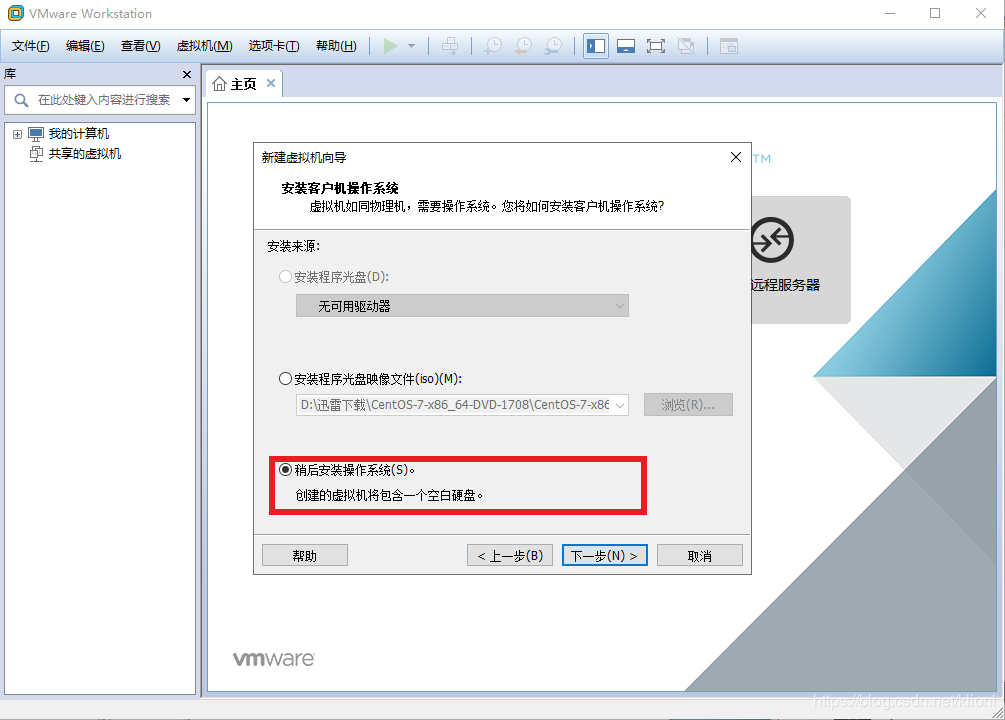
2 选择Linux系统和你下载的镜像文件相匹配的版本
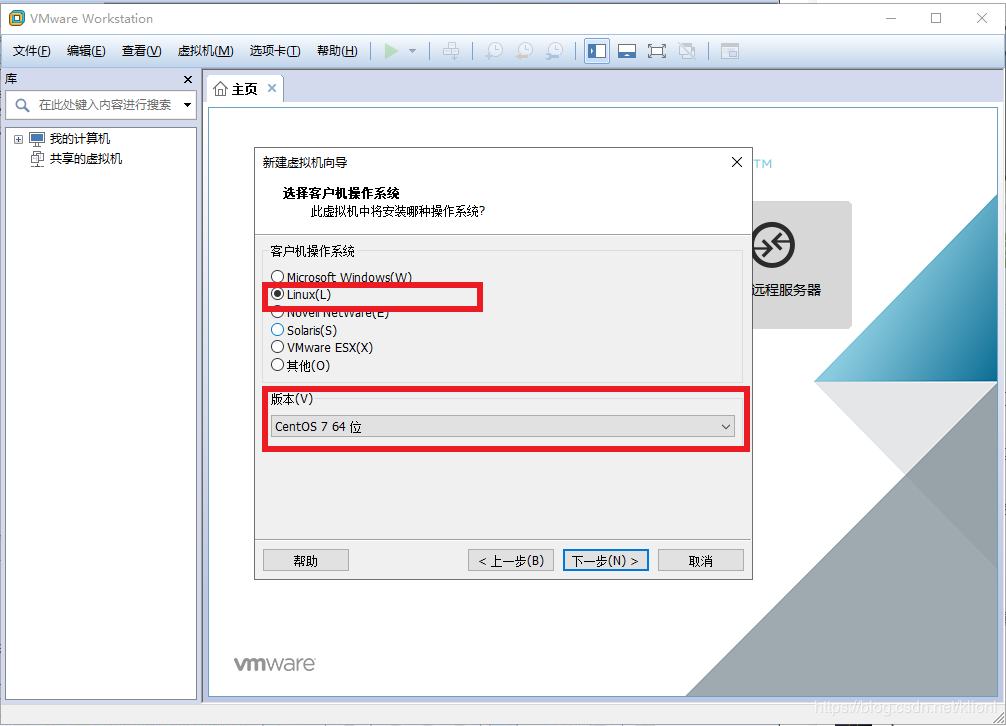
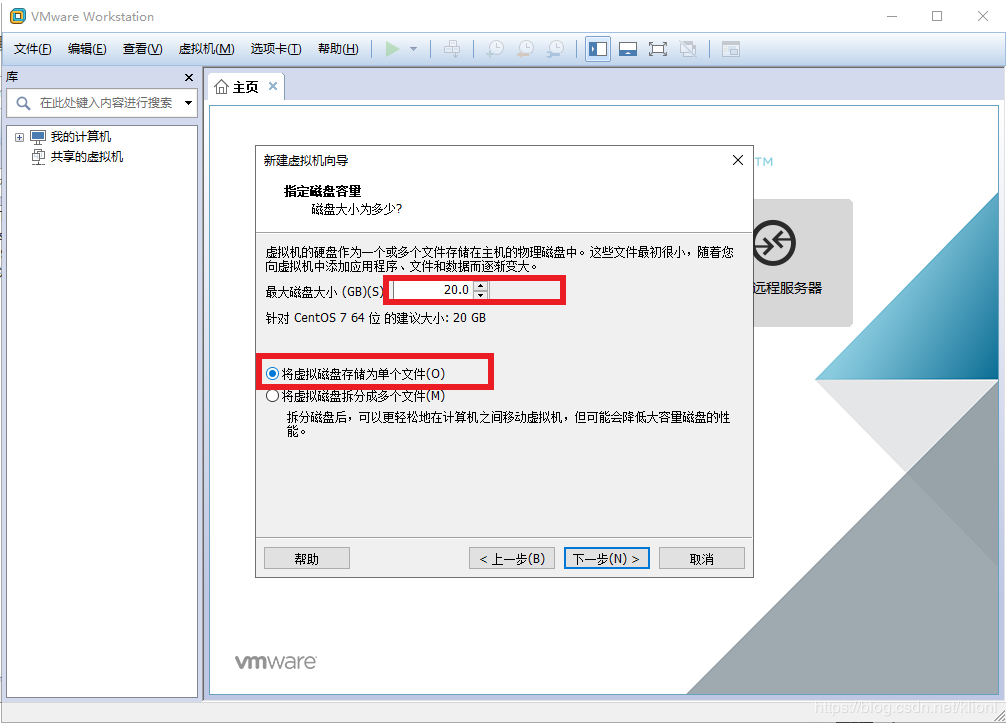
3 这里可以更改虚拟机名称和存储位置,然后选择默认的20GB,将虚拟机磁盘储存为单个文件,点击下一步,点击完成

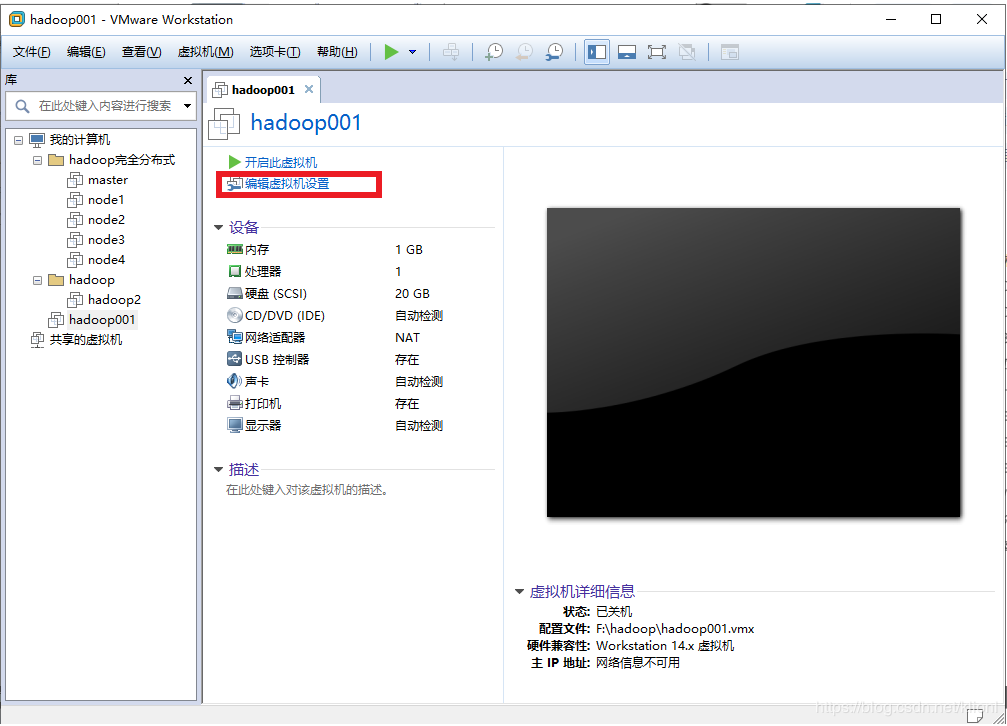
4 编辑虚拟机设置
5 点击CD/DVD,使用ISO映像文件,加载之前下载的CentOS镜像文件
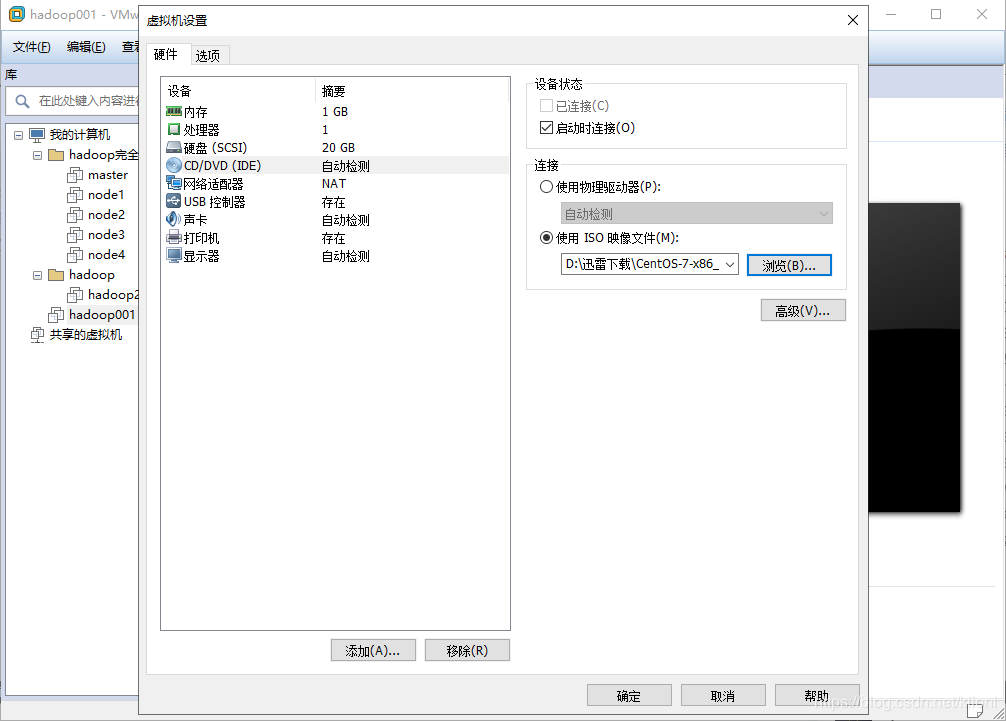
6 点击网络适配器,选择默认的NAT模式(和主机共享IP地址)
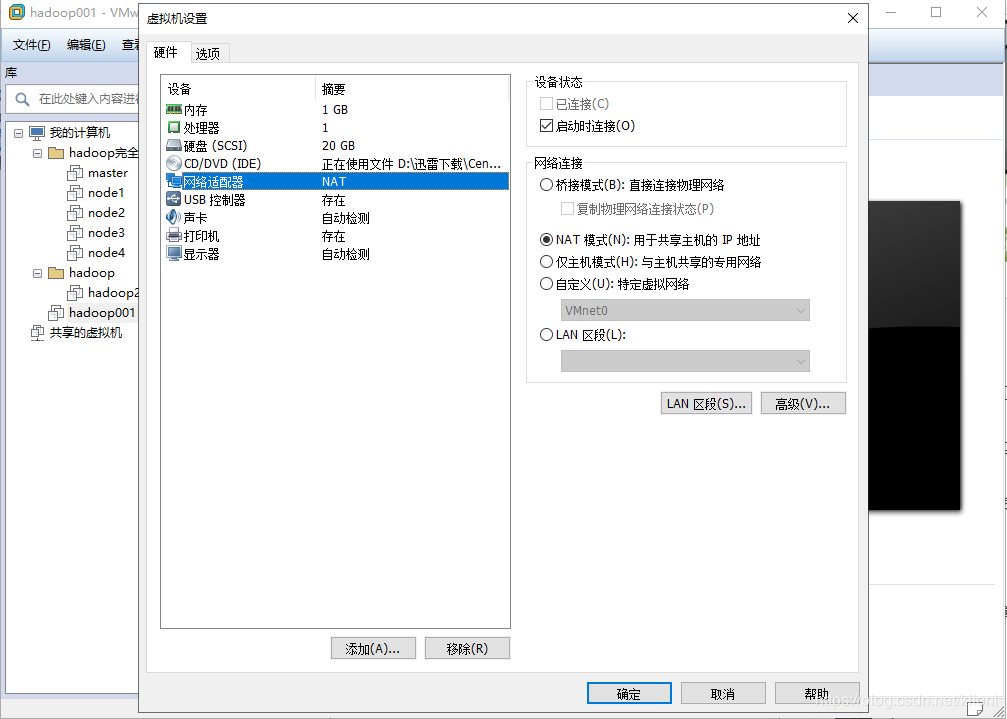
7 USB控制器,声卡和打印机可以移除,也可以不移除,移除为了省出更多的资源空间,然后就可以开启虚拟机了,开启虚拟机后,鼠标点进虚拟机屏幕(Ctrl + G也可以进入虚拟机,按Ctrl + Alt可将鼠标移出虚拟机),才可对虚拟机进行操作,然后按下 ↑ ,选择Install CentOS 7,按下enter键
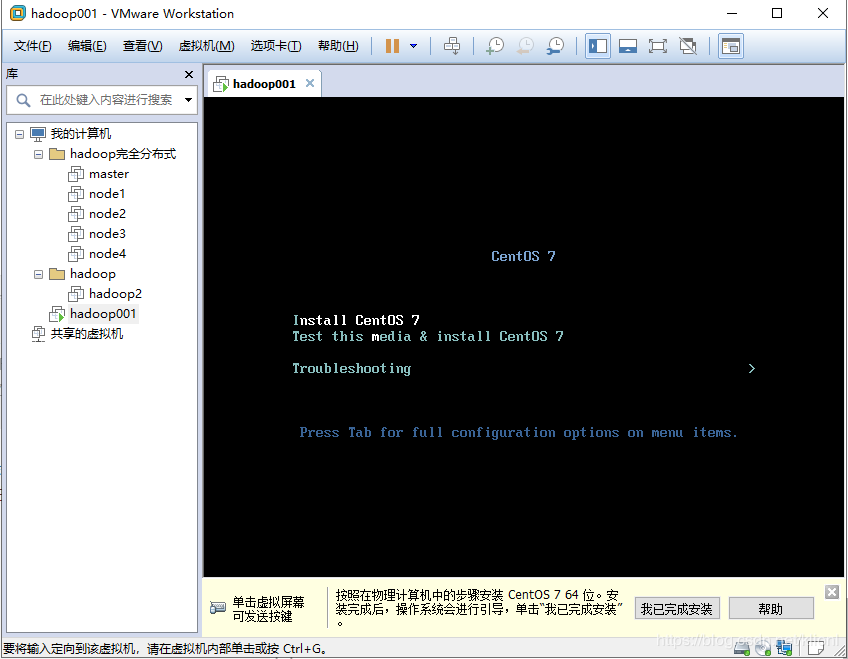
8 来到安装页面,选择语言
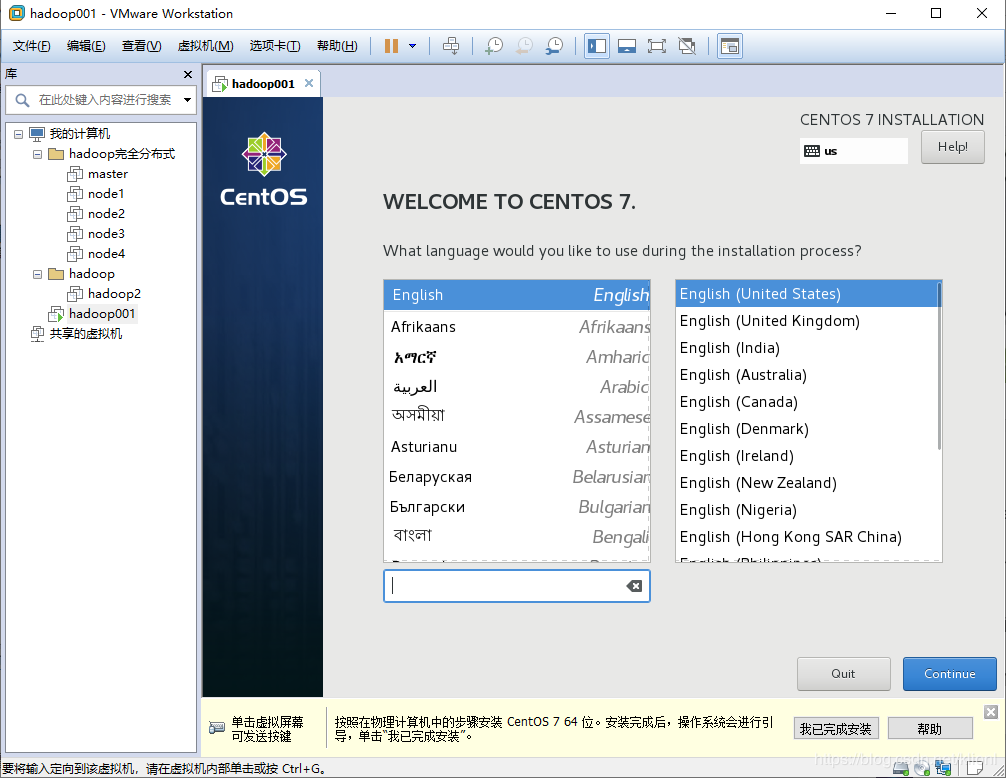
9 配置时区,选择上海,调整时间,点击完成
10 设置软件选择
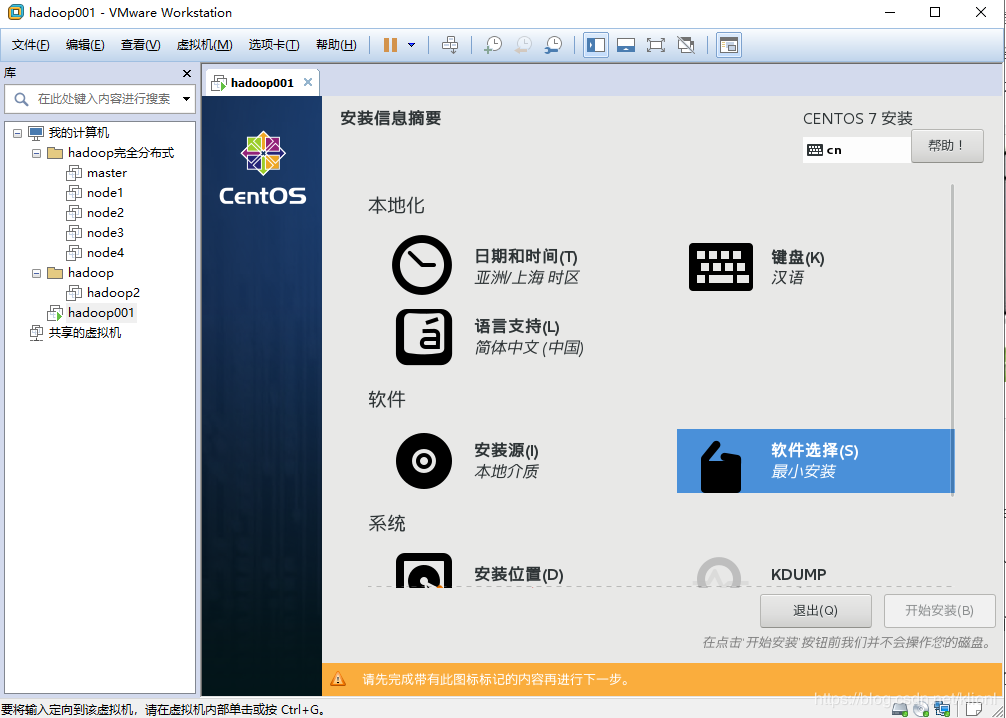
11 选择最小安装,勾选兼容性程序库和开发工具,这里是不带GUI界面的,进去就是终端模式的,如果想要GUI界面可以选择下面带GUI的服务器,也一样勾选兼容性程序库和开发工具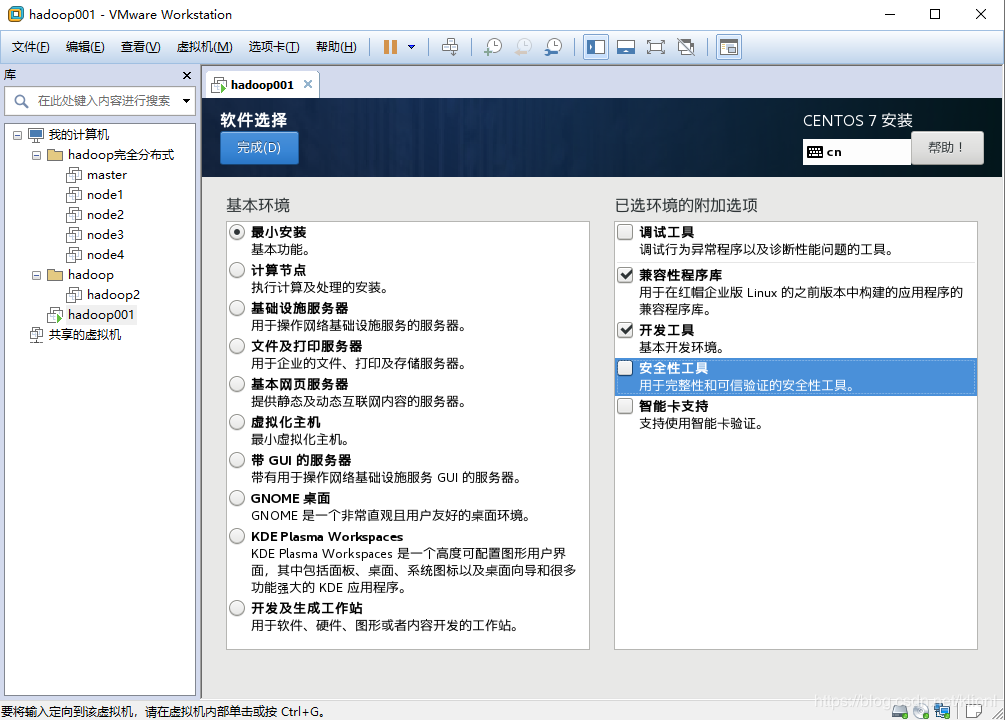
12 设置安装位置,点击我要配置分区,然后点击完成,来到手工配置分区界面
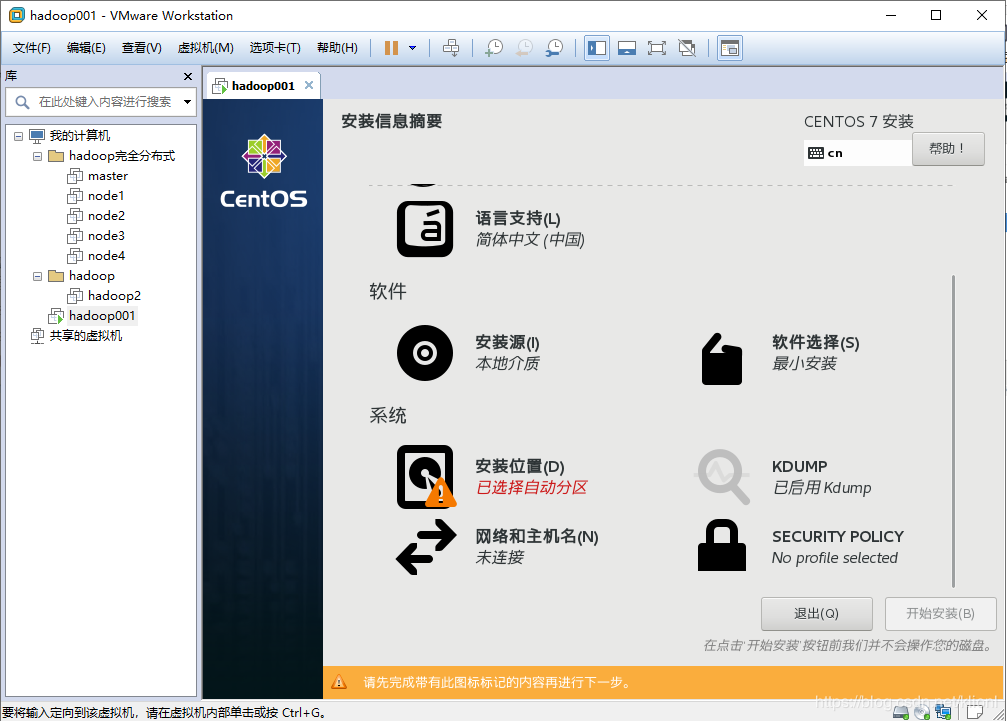
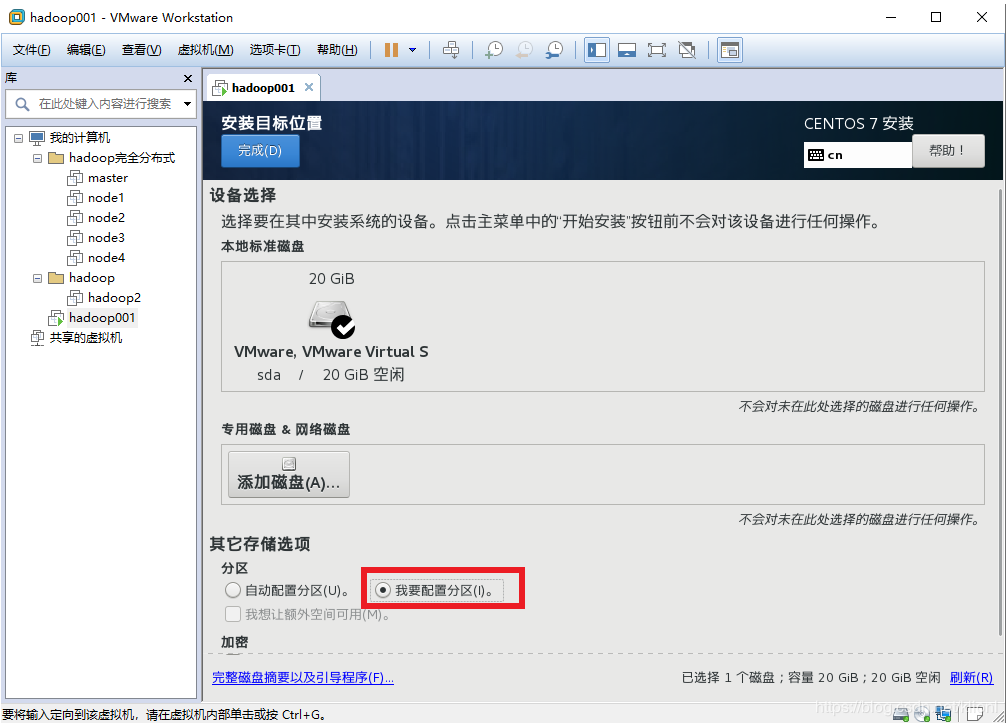
13 选择标准分区之后,点击下方的+
①添加 /boot分区,大小300MB
②添加 swap分区,一般情况是物理内存的2倍大小,用于物理内存不足时使用,但可能造成系统不稳定,所以看情况,可以设置小一点,甚至设置为0MB,这里我设置为512MB
③增加根分区,不填写大小,即默认剩余的空间都给根分区
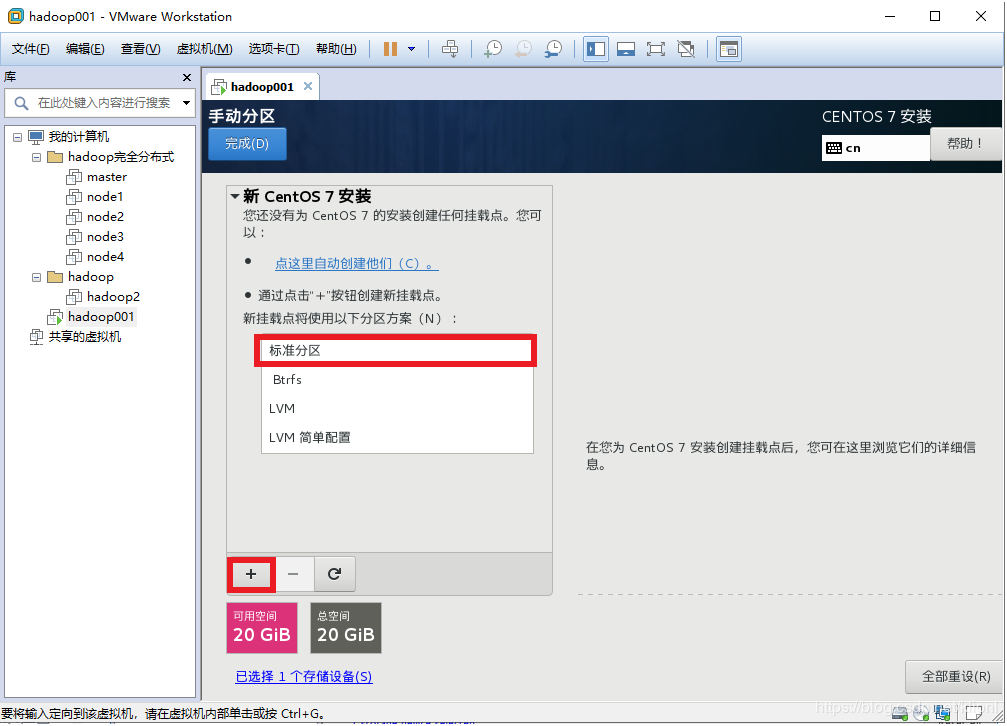
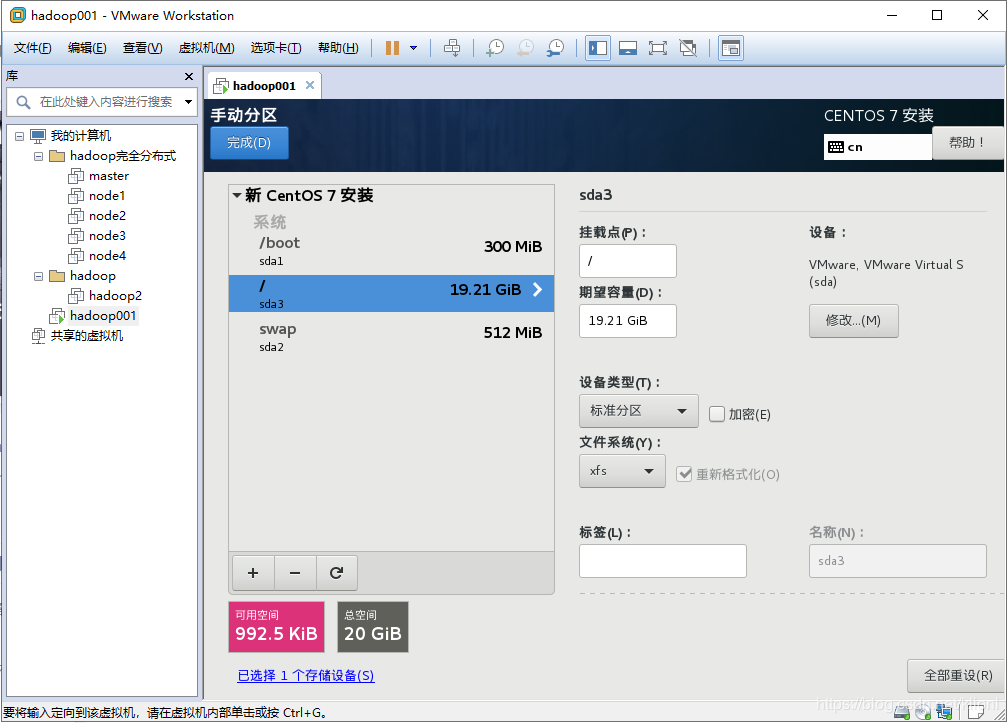
14 点击完成,接受更改
15 开始安装
16 等待安装过程中,给root账户设置密码,然后等待安装完成,点击完成配置之后出现重启按钮,点击即可
1 先打开cmd,输入ipconfig,查看以太网适配器 VMWare Network Adapter VMnet 8下的IPv4地址的前三位,当我们设置Linux的IP地址时,需要保证Linux的IP地址 与 VMnet8下的IPv4地址 的前面三位数必须相同,即 192.168.xxx必须相同,这样Linux就能跟我们本地电脑互相通信,最后一位数不相同即可,这里记录下你自己的Linux的IP地址
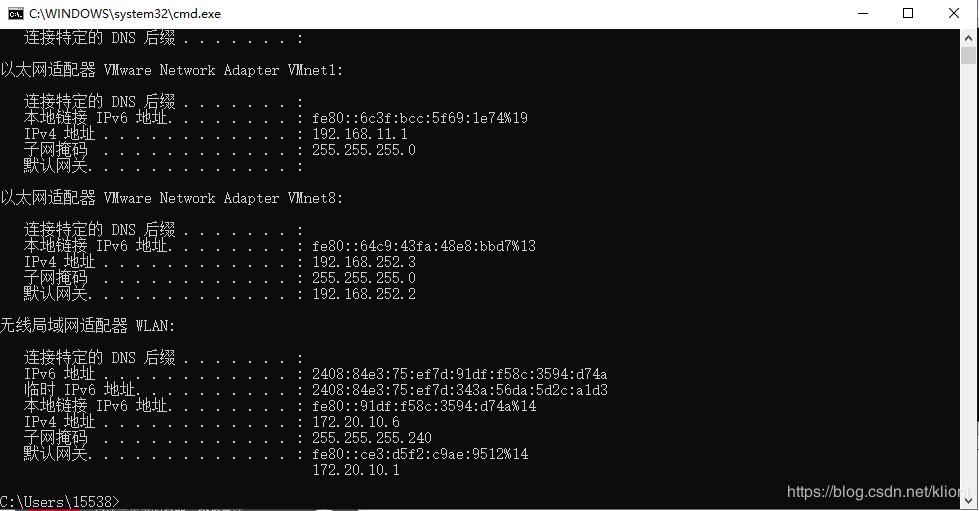
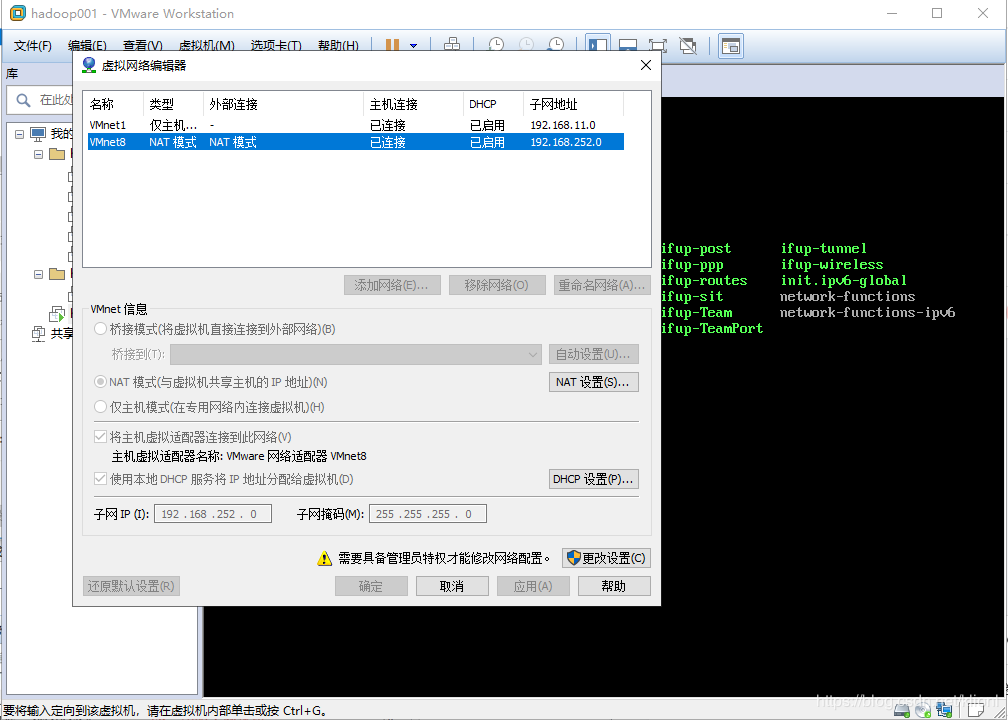
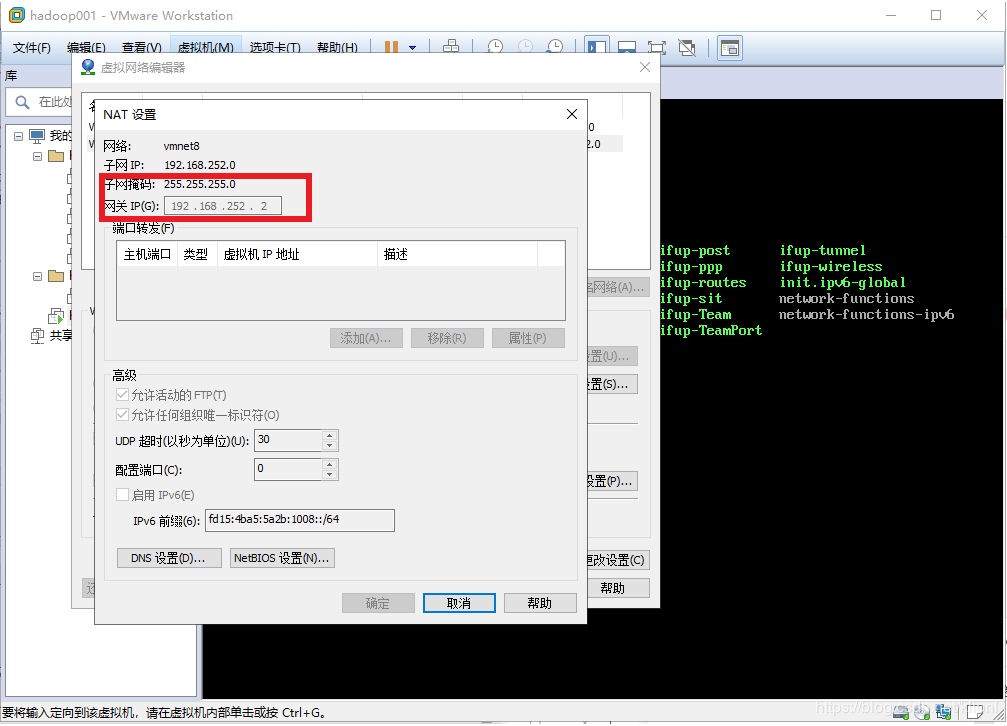
2 点击编辑→虚拟网络适配器,选择VMnet8,再点击net设置,记录下子网掩码和网关IP
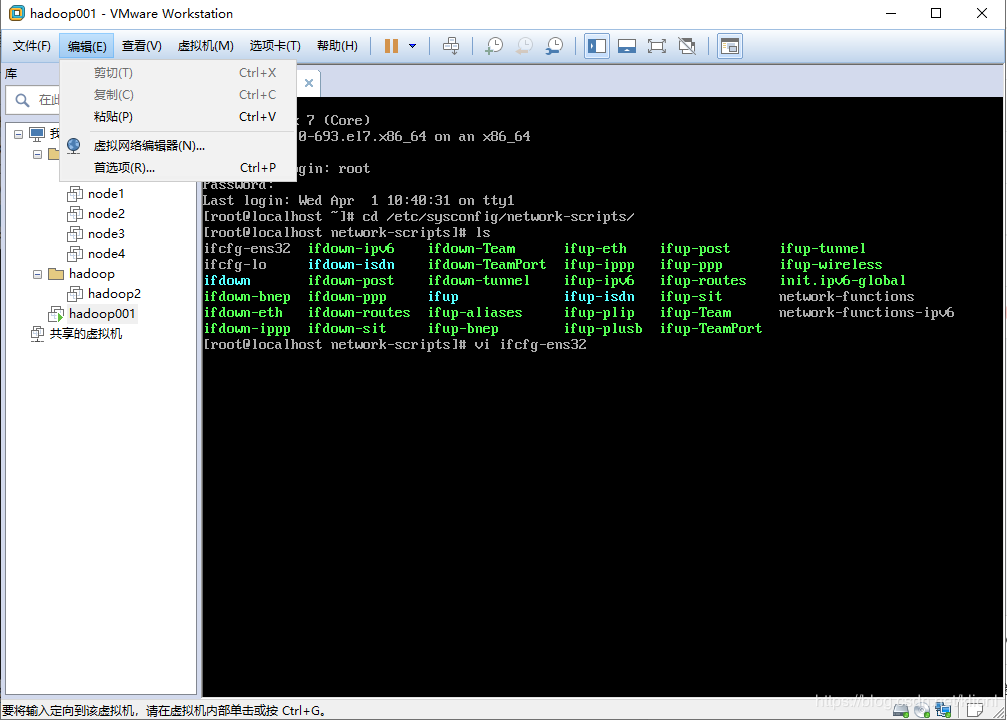
3 登录root账户,进入到/etc/sysconfig/network-scripts文件夹,编辑ifcfg-ens32
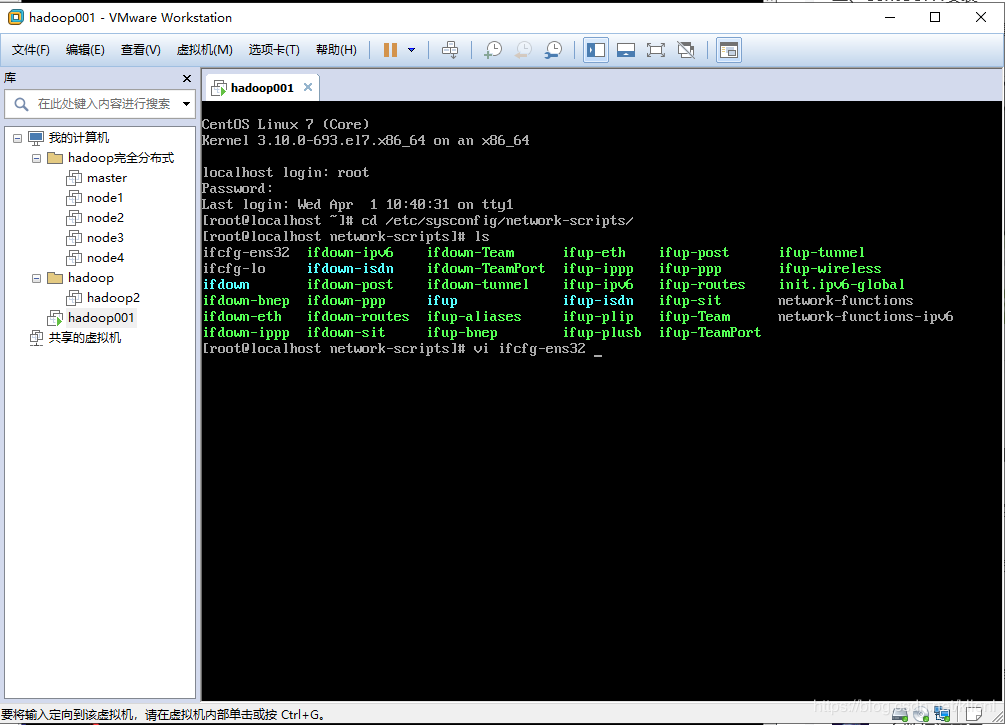
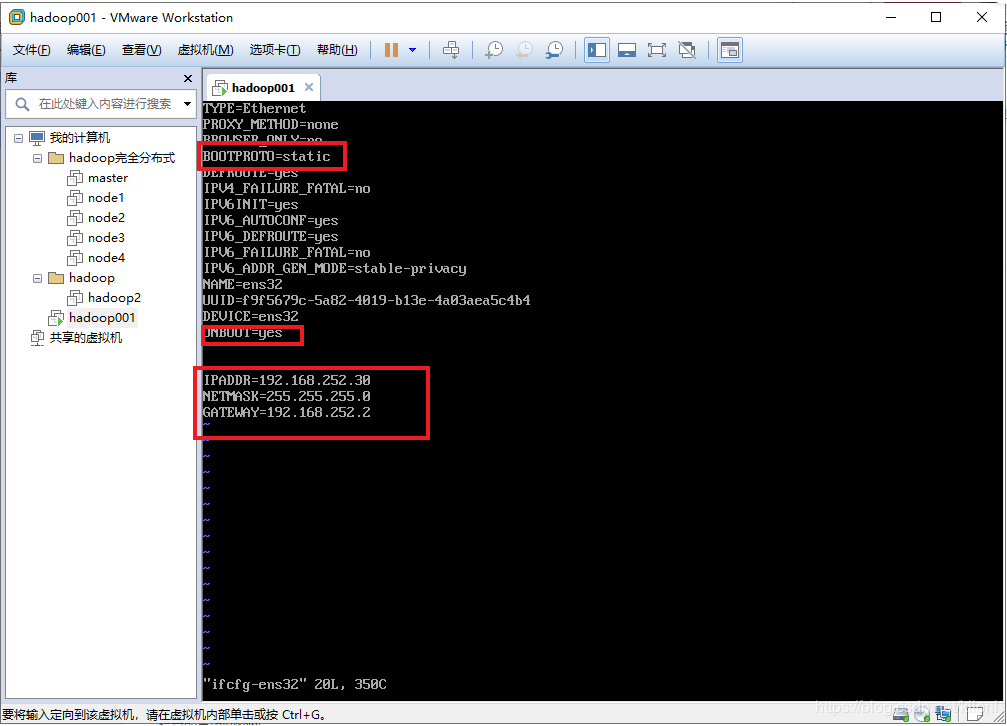
4 更改这两处地方:
BOOTPROTO=static //启用静态IP地址
ONBOOT=yes//开启自动启用网络连接
添加:
IPADDR对应你的Linux的IP地址
NETMASK对应子网掩码
GATEWAY对应网关IP
5 重启网络服务

6 设置DNS地址,编辑 resolv.conf文件,添加DNS地址
nameserver 114.114.114.114(国内移动、电信和联通通用的DNS)

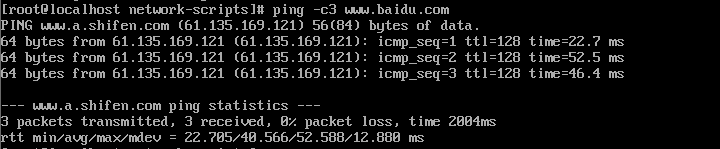
7 检查能否访问外网
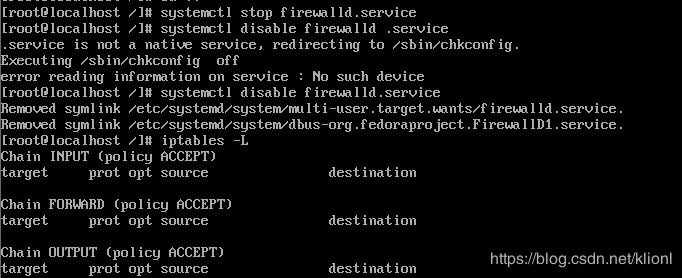
8 永久关闭 firewalld防火墙(centos7默认的防火墙是firewalld防火墙,不是使用iptables,因此需要关闭firewalld服务)
systemctl stop firewalld.service // 停止firewalld服务
systemctl disable firewalld.service // 开机禁用firewalld服务
iptables -L //列出所有iptables规则
9 永久关闭SELinux防火墙
vi /etc/sysconfig/selinux //编辑selinux文件
SELINUX=disabled //把文件中的SELINUX=enforcing 改成 SELINUX=disabled 即可
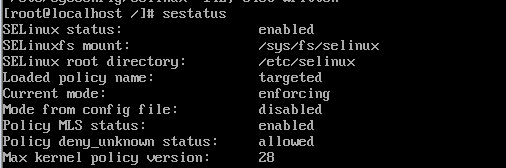
sestatus //查看SELinux状态
可以看到当前selinux防火墙的安全策略仍为enforcing,配置文件并未生效,这时我们重启虚拟机再查看SELinux的状态,可以看到已经关闭了
![]()
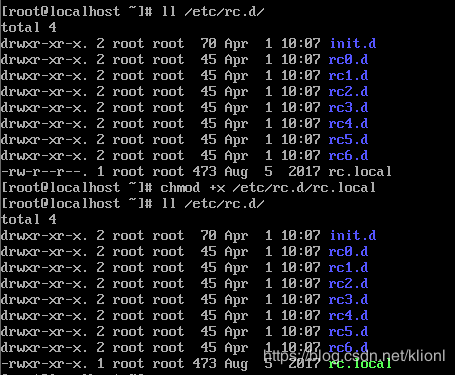
10 给/etc/rc.d/rc.local 文件设置 “x”可执行权限,最初设置默认是没有可执行权限的
chmod +x /etc/rc.d/rc.local //设置可执行权限
11 关闭虚拟机,拍摄快照
作者:klionl