Qumulo体系结构白皮书

Qumulo在2017年入围Gartner魔力象限,仅两年就成为了该领域的领导者。
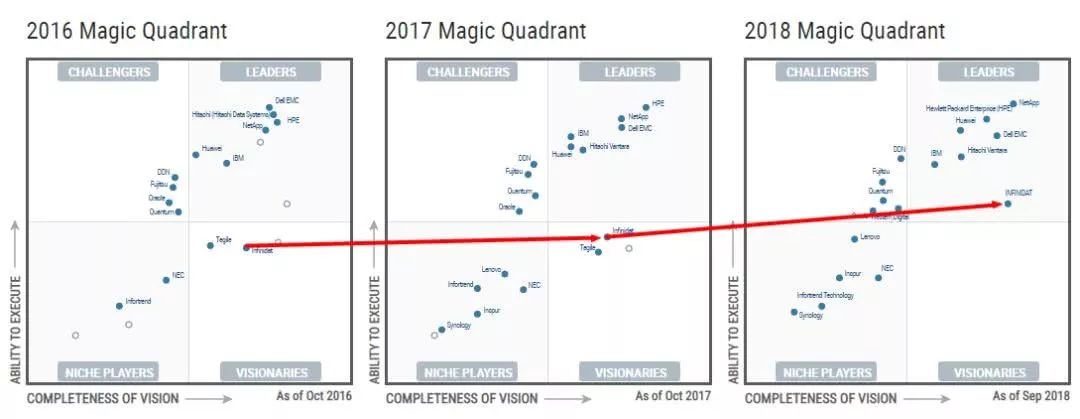
Qumulo的创始人一共3人,他们都是Isilon的大牛。Isilon一共有62项专利,他们三人就拥有55项。
张克诚,本篇文章的译者,原Panasas Technical and Business Development Manager。在HPC存储领域里,Panasas不可小觑。
经过译者授权,微信公众号“乐生活爱IT”首次转发这篇满是干货的译文。另外前面有些信息和图片,来自西瓜哥 高端存储知识的《2年就成为Gartner魔力象限领导者的Qumulo有啥特别?》
---译文开始---
Qumulo FileFabric (QF2) 支持本地部署和跨云部署,百亿级文件支持,极高扩充能力的文件存储。

QF2由软件和服务两部分组成,可根据预算灵活取舍。

核心是运行在QF2集群中的节点上的软件,包括强大的实时分析、容量限额、连续复制和快照。而其他的存储系统仅仅包含集成的实时文件元数据聚合。
QF2文件系统构建在Qumulo Scalable Block Store (SBS)之上,SBS采用海量扩充分布式数据库原理并且面向文件数据优化。SBS是QF2的数据块层,提供简单部署和极度可靠的底部支撑。因此SBS也给了文件系统海量扩充能力、优化的性能及数据保护。
另外,QF2还提供基于云的监控、趋势分析作为可选模块,与之伴随的还有综合用户支撑模块。云监控包括类似磁盘故障这样事故的前瞻探测以便事件真正发生前解决故障。对过去使用过程趋势分析的访问可以帮助用户节省成本优化存储使用流程。
核心软件可以运行在公有云上,也可以运行在数据中心中工业标准硬件平台上,Qumulo当前运行在自己的QC系列白牌机服务器上,也运行在HPE阿波罗服务器上。
事实上,QF2与硬件无关,可以期待更多的OEM支撑。
QF2纯软件方式意味着对昂贵、私有硬件如NVRAM、InfiniBand交换机、私有闪存等没有依赖,取而代之的是QF2依靠HDD和SSD的标准firmware,QF2中的SSD和HDD的组合使用实现了冷热数据自动分层,因此,QF2实现了在二级存储的价格上提供闪存的性能。
QF2也可以在公有云上创建(当前是AWS),基于云的QF2集群中的节点运行本地部署相同的软件,不同于其他面向云的文件存储系统,QF2运行在公有云上也没有性能和容量的硬限制。两者都可以借助增加节点(计算实例和块存储)来实现增加。
在公有云上运 行时,QF2使用云的块存储的方式与SSD/HDD相结合的本地部署方式类似,QF2用低延迟块存储做高延迟块存储的Cache。
在每一个QF2集群的节点上,核心软件在Linux的用户态运行,内核模式是仅仅用于与特定硬件相关的设备驱动程序。
用户态运行也意味着可以部署自己的重要协议,如:SMB、NFS、LDAP和AD。所以NFS是以系统服务的方式运行并且有自己的用户、组的概念,分离于借以运行的底部的操作系统。
用户态运行也改善了可靠性。作为独立的用户态进程,QF2与其他系统部件隔离,避免了其他部件引起的内存故障带来的影响,并且QF2开发的过程采用了高级内存校验工具,实现了内存相关的代码故障在软件正式发放前的前期探测。借助于软件升级双分割策略,Qumulo可以自动的升级操作系统和核心软件以保证快速和安全可靠。你可以简单的重新启动QF2而不必重启OS、节点或集群。
海量可扩充的文件和目录
当有海量文件时,目录结构和文件属性本身变成了大数据,直接结果是像treewalks这样的顺序处理(传统存储的基础)变得计算上不在可行。相反,查询一个大的文件系统并且管理它就需要并行和分布式算法的新的方法。
QF2具备这个独特的能力。设计部署的原理类似于现代、大规模、分布式数据库。带来的直接效果是文件系统具有无可匹敌的扩充特性。相比照的是传统存储没有具备这个扩充能力。

文件系统位于虚拟化的块层SBS之上。在QF2中,耗时的保护、重构、以及判定SBS层中哪个数据在哪个磁盘上的工作位于文件系统之下。
SBS中虚拟化的被保护的块的功能是本文件系统的一个重大优势。传统存储系统没有SBS,保护实现在文件层面上,或者混合的RAID组上,那样会带来严重的问题,比如,很长的重构时间、小文件的低效存储、以及较大的磁盘布局管理开销。没有虚拟化的块层,传统存储系统也必须在元数据层实施数据保护,这个附加的复杂度限制了这些系统优化分布式处理这些目录数据结构和元数据的能力。
对于文件和目录的扩充能力,QF2文件系统强化使用了被称为B-trees的索引数据架构。B-trees特别适用于读写海量数据块的系统,因为他们属于“浅”数据结构,在数据量增加时最小化了每个操作的IO请求的数量。以B-trees为基础,当数据量增加时读或者插入数据块的运算开销增长非常缓慢。所以,B-trees对文件系统和大型数据库索引来说非常完美。
在QF2中,B-trees是基于块的,每个块4096字节。以下是B-tree的结构。

每个4K块可能含有指针指向其他的4K块。该例的分叉因子为3,分叉因子指的是树中每个节点孩子的数量(子节点)。
即使有百万级别的数据块,SBS中的B-tree的高度,从根到数据实际的位置,也就两到三层。比如,上图中查找带有索引值1的q标签,仅需穿过树的两层。
本文件系统把B-tree用于多个目的。
有一个inode B-tree,扮演所有文件索引的角色。Inode列表是一个标准文件系统部署技术用于目录层级无关的文件系统一致性检查。Inode也用于目录高效移动操作的更新等。
文件和目录在B-tree中表现为各自的键/值对,比如文件名、文件尺寸、访问列表(ACL)或者POSIX许可等。
配置数据也是一个B-tree,包含类似IP地址和集群等信息。
事实上,QF2文件系统可以理解为是一个树的树。如:

最顶层的树叫超级B-tree。系统启动时,处理从这里开始。根总是存储在虚拟保护的块的阵列的首个地址(paddr 1.1)。根树指向其他的B-trees。例如,如果QF2文件系统需要访问配置数据,就会走到配置B-trees。查找一个特定的文件,系统询问inode B-tree使用inode编码作为索引。系统穿越inodetree直到发现指向文件B-tree的指针。从那里文件系统就能够找到包含文件本身的所有内容。目录的处理过程和文件一样。
依靠B-tree,指向SBS中虚拟化的、受保护的块存储是文件系统处理万亿级文件的核心。
QumuloDB实现实时可视及控制
QF2设计理念不仅仅是存储文件数据,也帮助你实时管理你的数据和用户。传统存储管理人员受限于看不见数据,所以不知道文件系统中真实发生了什么。QF2的设计是真正可视的,这不管你存储了多少文件和目录。例如,你能立即看到吞吐量变化趋势以及热点。你也可以设置实时容量限额,避免了在传统存储中限额实现的时间开销。信息通过图形用户接口得以访问,当然REST API也可以实现信息编程访问。
QF2文件系统的集成分析特性被称为QumuloDB的组件支撑实现。

当系统扩充时观察实时分析特性,人们通常会问它怎么会这么快?这里有三个原因。
1、在QF2文件系统中,QumuloDB分析是内置的并完全与文件系统本身集成,传统存储,元数据查询的回馈来自于核心文件系统以外的非相关的软件组件。
2、QF2文件系统依托B-trees,QumuloDB分析能够使用一个实时聚合的创新系统,下面的章节会介绍。
3、最后,QumuloDB分析是因为QF2文件系统是一个流线型设计,因为它采用了B-tree索引和虚拟化的受保护的块以及SBS交互处理。
元数据的实时聚合
QF2文件系统中,像所用字节和文件计数的元数据是在文件和目录在创建时或修改时聚合的,这就意味着处理时信息可以即时访问而没有昂贵的文件系统treewalks.
QumuloDB维持一个即时更新的元数据概览,使用文件系统的B-trees收集文件系统的更新信息。不同的元数据域在文件系统中创建一个虚拟索引来概述。你在GUI中见到的性能分析基于采样机制被REST API抽出,采样机制是嵌入到QF2文件系统的。统计有效的采样技术源自于即时更新的元数据概览,它允许采样算法对大目录和文件施加较大的权重。
在QF2中聚合元数据采用了自下而上和自上而下的方法。
当每一个文件或目录新的聚合元数据更新时,它的父目录被标注为dirty,其他的更新事件为这个父目录进行排队。用这样的方法,文件系统信息在穿越树时被收集和聚合。元数据繁殖于单个的inode,在最低的层级上,在数据实时访问时到达文件系统的根。每个文件和目录的操作都不会漏掉,这些信息最终繁殖到非常核心的文件系统中。这里是个举例。

左边的树聚集了文件和� �录的信息并合并他们到元数据。然后为了父目录将该更新排入队列。信息上移,从该级(叶)到根。
并行的从下至上繁衍更新元数据,定期的从文件系统顶部开始扫描读取元数据中呈现的信息。当扫描发现更新的聚合信息时,修整这个扫描转到下一个分叉。一个假定是在文件系统树中从当前位置往下到叶(层)(包括了所有文件和目录的层或叶)的聚合信息是实时更新的,不需要扫描更低层做更多的分析。大部分的元数据概览已经被计算过,理想情况下,扫描仅仅需要重新描述整个文件系统中的一小部分。效果是聚合的两个进程会在中间某个点相遇,无需从上至下检索整个文件系统树。
采样和元数据查询
QF2实时分析的一个明显例子是性能热点报表。这是一个图形界面截屏。
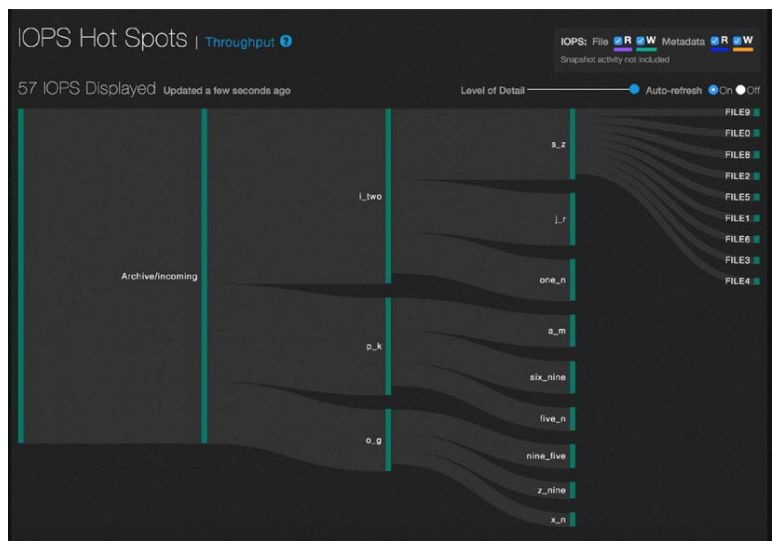
在大的文件系统中用GUI描述每个吞吐量操作和IOPS是不可能的。取而代之,QumuloDB查询采用概率论采样从而提供接近有效的信息。IOPS的读写操作数、总体的IO吞吐量是从缓存中抽样提取的,这个缓存含有4096个条目,其内容数秒更新一次。
这个报表显示的操作是对集群产生最大影响的操作。这些操作在GUI中被表述成热点(hotspots)。
QF2使用概率论采样的有效统计能力仅仅因为QumuloDB中连续实时记录了描述每个目录的元数据(使用的字节数,文件计数)。这是QF2高级软件技术独一无二的优势,其他的文件存储系统不具备。
实时限额
正像实时元数据聚合实现了QF2的实时分析,它也实现了实时的容量限额。限额使得管理人员可以定义一个给定的目录可以占用的空间容量。例如,如果管理员发现某个无赖用户的子目录占用空间过快,管理员则可以即时限制那个用户所用目录的空间容量。
在QF中,限额是即时部署的,不必事前定义供给。可以实时实施和变化。一个额外的好处是限额设定到目录搬移,目录本身可以搬移进或者搬移出限额域。
不像其他的文件系统,Qumulo限额不需要嵌入到文件系统卷中。另外,QF2移动限额或在限额域中移动目录,不会引入过长的treewalks、作业调度、繁琐处理以及多步进程。QF2中的限额可以实施到任意目录,甚至是套叠的目录。如果因为套叠的目录原因发生空间分配与多个限额相关,所有的限额必须被满足以便分配请求的存储空间。
因为QF2中限额限制是在目录级别以元数据方式记录保存,限额就可以在目录树中任意层级设置。当写操作发生时,所有相关限额必须被满足。这是硬限额限制。QF2实时限额的精确性和敏捷性是由内置聚合器连续不断的对每个目录所占空间描述的即时更新保证的。
快照
快照使得系统管理员对文件系统或者目录在任意给定时间点的状态进行保护。如果一个文件或者目录被无意修改或者删除,用户或系统管理员可以恢复其到保存的状态。
QF2中的快照,是极端有效和高度可扩充的部署。一个QF2集群可以有几乎无数量限制的并发快照,同时快照不带来性能和容量的下降。
快照的部署原理是out-of-placeblock writes。快照发生同时有块被修改时,他们被写到一个新的B-treeblocks的骨干上。没有发生变化的现有数据块被链接到这个新的骨干上并且共享。该新被修改的骨干写的方式是“out ofplace”,但依然链接到现有数据,共享没有发生变化的数据块。直到数据被修改或被删除快照都不占用额外空间。
比如,把一个4MB 的文件写到QF2的文件系统中,做一个快照。快照完成后,所占空间容量仍然是4MB。然后该文件中1MB的区域发生了变化。新数据(1MB)被写到了别的位置(out of place),但与该文件的活跃(live)版本相关联。4MB数据中原始的3MB数据在活跃版本和快照版本之间共享。该文件现在总共占用5MB空间。

快照是一个安全特性,保证文件系统快速恢复,避免用户误删除和误修改带来数据损失。比如,如果一些数据意外被删除,用户就可以从从前的快照中恢复数据。单个文件或整个目录借助于把他们拷贝回活跃文件系统得以恢复。
当存储可用空间变得很少时,管理员通常决定删除快照释放存储空间。因为快照共享数据,删除快照通常不会回收到与整个文件所占全部空间相当的容量。在传统存储系统中,事实上很难知道回收了多少存储空间。
QF2中的快照,利用内置于文件系统的智能优势,管理员能够计算出删除快照后能回收的实际空间容量。
连续复制
QF2提供了横跨不同存储集群之间的连续复制能力,无论这些集群是本地部署还是公有云部署。一旦在源集群和目标集群之间建立了复制关系并同步,QF2将自动的保持数据连贯和一致。
QF2中的连续复制,是借助QF2的高级快照能力确保数据副本的一致性。有了QF2的快照,目标集群上的一个副本复制某个精确瞬间源目录的状态。QF2的复制关系为了最大的灵活性可以建立在每个目录的基础上。
Qumulo利用智能算法管理复制,所以没有必要管理员介入。QF2的复制频率取决于对整个集群性能没有负面影响的实际情况。QF2中的连续复制现在是单向异步的;就是说有一个源和一个只读的目标。源目录的变化被异步的复制到目标上。
Qumulo ScalableBlock Store (SBS)
现在我们看一下QF2文件系统的内部,QF2在SBS中的分布式块管理的的高级策略。下面是一个概览。

SBS提供一个受保护的存储块的传输虚拟层。取代了系统中文件必须配置自己的保护模式,数据保护设置在文件系统下面,也就是说块层。
QF2基于块的保护机制,由SBS实现,为PB数据环境和混合文件尺寸负载提供出众的性能。
SBS的优势有很多,其中包括:
磁盘失效情况下的快速重构时间
重构操作时持续的正常文件操作能力
常规文件写操作和重构时发生的写操作有竞争时无性能衰减
大文件小文件有相同的存储效率
可用空间的精确报表
高效传输(交易)允许QF2集群扩展至数百节点
内置的冷热数据分层技术实现了归档存储价格闪存性能。
受保护的虚拟块
QF2集群的整体存储容量概念上以单一、受保护的虚拟地址空间来组织,如图。

空间中每个受保护的地址存储一个4K字节的数据块。受保护的意思是即使多个磁盘发生故障,所有的数据块都是可恢复的。
整个文件系统驻留在SBS提供的受保护的虚拟地址空间中,包括用户数据,文件元数据,目录结构,分析信息,配置信息等。换句话说,受保护的存储空间扮演了文件系统和记录在块设备上的基于块的数据� ��间的接口角色。这些设备可能是由SSD和HDD相结合或者公有云中的块存储资源形成的虚拟磁盘。
必须记住,受保护地址空间中的块是分布于所有集群节点中或者QF2集群实例中的。然而,QF2文件系统看见的仅仅是全保护块的线性阵列。
基于纠删码的数据保护
对于磁盘故障引起的数据丢失保护,总是包括某种形式的横跨存储设备的信息冗余或者信息复制。数据保护的最简单形式是镜像。镜像意味着有两个或多个完整数据副本处于保护状态。每个副本驻留在不同的磁盘上,所以一个磁盘故障后他是可以恢复的。
镜像容易部署,但与更现代的保护技术相比有明显的劣势。镜像保护数据非常浪费存储空间,并且仅能应对单一磁盘故障,在节点密度和集群规模增加时这种保护级别是明显不够的。
数据保护的其他策略包括RAIDStriping。RAID与之伴随的是极度复杂的管理负担,缓慢的重构时间,迫使管理员在不可接受的漫长重构和不可接受的存储利用率之间作出选择。
SBS采用高效的纠删码部署基于块的数据保护。SBS用的是Reed Solomon码。EC是比较快的,与镜像或者RAID Striping比较起来更可配置更节省空间。
纠删码采用存储于分布于不同的物理介质的冗余数据切片编码块存储。EC的高利用率带来了低的每可用TB的成本。
纠删码的配置可以在性能、故障发生后的恢复时间、允许并发故障数量等情形下作出妥协。本文使用标记(m,n)标识纠删码配置,m代表物理介质能安全存储n个用户数据块总的数据块数量。这个编码代表最多m-n个数据块损坏的情况下不会发生用户数据丢失。换句话说,n个磁盘的组合可以恢复所有的用户数据,哪怕一些磁盘含有用户数据。这种编码的有效率可以用n/m来计算,或者用户数据块数除以全部数据块数。
EC用举例的方式及其容易理解,这是一个(3,2)编码。

一个A(3,2)编码需要三个块(m=3),驻留在三个有区别的物理设备上,以保证安全的存放两个块(n=2)。其中的两个数据块存放用户数据并被保护,第三个块叫奇偶校验块。奇偶校验块的内容用纠删码算法计算得出。尽管这是一个极其简单的方案,也比镜像有效 – 每两个数据块仅仅写一个奇偶校验块。在一个(3,2)编码中,含有三个块中任意一个的磁盘出现故障,在1和2两个块中的用户数据是安全的。
他的工作原理是,如果数据块1是可用的,那么就简单的读取它。对于数据块2同样适用。然而,如果数据块1故障,EC系统读取数据块2和奇偶校验块并使用Reed-Solomon码方程式重构出数据块1的值(这个特定的例子就是简单异或运算)。相同的,如果数据块2驻留的磁盘故障,系统读取数据块1和奇偶校验块。SBS将确保数据块驻留在不同的物理磁盘上所以系统能同时读取这些块。
一个(3,2)编码的容量效率是2/3(n/m),或者是67%。从数据存储角度说比50%效率的镜像要好,(3,2)编码仅仅能防范单盘故障。
在QF2中最小的编码设置是(6,4),比镜像模式多存储1/3的用户数据,但可以允许两块磁盘同时故障。哪怕包含用户数据的两个数据块失效,系统仍然能够读取两个数据块和两个奇偶校验块来恢复丢失的数据。
横跨节点的受保护的虚拟块的分布
在EC系统中对海量可扩充的能力有很多实际的考虑。为了写需要的奇偶较快的过程更容易(以及磁盘故障恢复数据),SBS把4K块的� �拟地址空间分割到叫做受保护的存储体或pstores的逻辑切片中。

SBS独立管理每一个pstores,这样使得受保护的地址空间与磁盘的关联机制更灵活。所有的pstores大小相同。数据保护完全部署在系统的pstores这个级别。
Pstores可以理解为是一个映射受保护虚拟地址空间范围到QF2集群节点虚拟磁盘上的存储连续区域的表格。这个连续区域称作bstores。
Pstores到bstores的映射存储在集群中的每个节点上。为了可靠性集群节点采用Paxos的分布式算法来保持像pstores到bstores映射等的全局共享共识的一致性。集群设置了节点的仲裁以保证集群关键数据结构的安全。
每个bstore使用一个特定虚拟磁盘的切片(也就是说,bstore是与特定的SSD和HDD对相关联的)。当bstore与SSD相关的空间动态分配时每个bstore分配到相关HDD的连续空间上。Bstore的元数据也共存在相关的SSD上。Bstore元数据包括应用中的地址信息,标识每个指向SSD存储的bstore中的块地址与哪个HDD映射的信息。
读或写时,pstore决定哪个bstore 需要被访问。
当文件系统的一个客户端触发了写操作,它像一个原始数据流进入SBS。系统识别出哪个bstore来写入这个数据,计算出校验数据,把原始数据和校验数据同时写入SSDs,即便SSDs驻留在不同的节点上也是如此。一旦数据写完,客户端将得到反馈,写操作已经发生。
含有用户数据块和校验信息数据块的数据块同时被写入bstores,一个特定的bstore,在它的存活周期内,要么包含用户数据块,要么包含奇偶校验数据块,但不能两者同时包含。因为EC实施部署在SBS的pstore层,含有校验信息数据块的bstore和含有用户数据块的bstore运作形式完全一样。
分配给bstore的存储容量大小取决于EC的定义。Pstore的尺寸大小前后一致,系统bstore的尺寸大小依编码机制而变化。例如,如果pstore是70GB,在(6,4)的编码机制情况下,每个bstore大约是17.5GB,也就是说pstore被分成了4个bstores。对于(10,8)的编码机制来说bstore的大小将是前例的一半。
在云情况下,QF2采用和本地部署相同的数据保护机制,但有一个例外。本地部署,数据保护机制需要集群至少包含4个节点,在云环境下,单节点集群也是可能的,因为QF2可以使用内置的镜像,它存在于每一个弹性存储块中。云环境下的单节点集群采用(5,4)的纠删码机制。
快速重构时间
QF2的重构时间以小时计,与之对应传统的存储系统,即便面向非常小的数据负载设计,重构时间也以天计。大量的文件,混合负载,不断增加的磁盘密度都对传统存储的重构时间带来了危机。QF2在重构时间方面的戏剧性优势是SBS高级的基于块的保护的直接结果。
基于块的保护机制在今天的现代负载情况下是非常理想的,现代负载通常是PB数据,百万文件,同时有很多小文件。SBS保护系统不需要做耗时的treewalks或者一个文件又一个文件的重构操作,取而代之的是,重构操作发生在pstores层面。带来的结果是重构时间不受文件尺寸大小的影响。小文件的处理与大文件一样高效,保护百万文件完全高效可靠。
另外,QF2的设计,集群的规模大小不会对重构时间带来负面影响。事实上,其他系统的负面影响肯定存在。在QF2中,大规模集群的重构时间还要快于小规模集群。原因就是SBS在整个集群中的节点上分散了重构的计算负载。节点越多,重构时每个节点要做的工作就越少。
传统存� ��系统较长时间的重构会带来重构时其他磁盘故障带来的巨大风险。换句话说,较长时间的重构对于可靠性来说有巨大的负面影响。典型的情况是,管理人员用过分配的方法来补偿(增加数据冗余度降低存储效率)。QF2快速的重构时间,管理员能够保证他们的数据丢失时间窗口(MTTDL:Mean Time To Data Loss)目标而不必做出很大的冗余代价,即节省时间也节省钱。
Pstores的重构
磁盘故障时,pstore依然存在。它仍然可以读出与写入。然而,一些pstores会有丢失或损毁的bstores。这些pstores被称为降级(degraded)pstores。正是因为EC,你能够连续的读取这些降级的pstores,但是这些数据不再是全方位受保护的,换句话说,在第一次故障时,你仍然拥有数据的完整性但是是一个磁盘接近了数据丢失。
重新保护数据,系统在一个接一个的pstore层面上重构驻留在失效磁盘上的bstores(不是传统RAID组中一个接一个的文件层面)。SBS预留了一个小的额外磁盘空间实现该操作。这个叫做备用品(sparing)。
既然全局pstore到bstore的映射涵盖了与bstore相关联的虚拟磁盘的ID,这个信息就能简单知道当一个特定磁盘故障时哪个pstore需要处理。既然这个映射把pstore与bstore相关联且数据量足够小并驻留在每个节点的内存中,集群节点就能快速翻译从pstore到bstore的虚拟数据块的地址。
在重构的过程中,SBS顺序读写bstores。既然bstores在磁盘上是连续分布的,降级pstores就能够快速重构。顺序操作比很多小IO的操作要快很多,小IO操作很慢也能造成磁盘竞争。SBS的重构过程非常高效 – 重构过程中关联到的磁盘一次只有一个读或者写的数据流。不需要随机IO。另外,bstores也足够小所以重新保护操作是高效的分发到整个集群的。
常规文件操作不受重构影响
在传统文件系统中,锁机制的竞争影响重构时间并造成重构时文件系统性能下降。这是因为这些文件操作与重构/重保护的线程存在竞争。QF2采用了带有独立锁机制的写操作分层技术所以重构操作与常规文件系统的操作没有竞争和冲突。
运行这些写操作,系统对降级pstore增加了一层虚拟bstore。这被称之为“pushing a layer”。写操作进入这一新的bstores层而读操作则结合了每一层的信息。这里是一个示例。

新的写操作进入到上层的bstores。一个读操作则借助EC算法结合了来自上层和下层的信息。一旦bstore的重构完成这个push层就会消失。这些层是由SBS处理系统的多个组件以一种无阻塞的方式构建成的。
小文件与大文件一样高效
因为QF2文件系统采用了基于数据块的保护,小文件的处理与大文件的处理有相同的效率。他们能与其他文件一起共享条带(strips),并同时共享保护。每个文件都包含数据块,至少一个inode块,以及必须的其他的块。非常小的文件是inlined到inode块中的。本系统是采用了4K大小的数据块,所有的块都以系统的保护比率得到保护。
带有小文件的QF2文件系统的效率是相较于传统存储系统的一个巨大优势,他们对小文件和系统元数据采取的是无效的镜像技术。
所呈现的全部存储容量对用户文件来说都是可用的
QF2用户文件能百分之百的占用呈现空间(provisioned),而传统scale-out存储系统建议仅仅使用80%到85%。基于块保护的QF2不需要预留空间(user-provisioned)实现重保护,而是用一个小量 空间来sparing,这个空间不属于用户呈现存储空间。与之对照的是常规存储系统部署保护机制不是用固定的RAID组技术就是用基于文件的纠删码技术,这就意味着重保护也发生在文件级别并且需要用户呈现存储空间来实现数据恢复。
另外,QF2文件系统能精确显示用于用户文件的可用存储空间。这种可预测性来源于基于块的保护技术。传统存储系统存储的使用依赖文件的大小,所以这些系统仅仅能显示裸空间(raw space) - 管理员需 估算多少空间实际可用。
当比较QF2和传统系统时,需要考虑每个类型的系统用户呈现容量实际上有多少空间可用。
数据处理
在SBS中,对受保护的虚拟地址空间的读写操作是可交易的。这就意味着,例如,当一个QF2文件系统操作需要一个写操作涉及到多于一个数据块时,该操作将不是写所有相关数据块就是一个数据块都不写。原子读写操作本质上用于数据的一致性以及像文件协议SMB和NFS的正确部署和实现。
为了优化性能,SBS在保证可交易的一致性的IO操作时最大化的实现并行和分布式计算的技术。例如,SBS的设计在需要顺序而非并行的操作时避免了串型瓶颈。
SBS处理系统原理来源于ARIES算法来实现无阻塞处理,包括了超前写日志、回滚操作时的记录重复。然而,SBS处理系统的部署与ARIES有几个重要的不同。
SBS充分利用触发交易的QF2文件系统是可以预判的事实 – 出色的存活短,与之对照的通用数据库处理时的相对存活较长。一个存活短交易的应用模版允许SBS为了效率能频繁裁剪处理的日志。存活期短的处理实现了快速的指令执行。
另外,SBS处理系统是高度分布执行的而不需要全局定义的,每一个处理日志入口ARIES风格的顺序编号的全部指令的执行。取而代之的是,每一个bstore中本地化的日志顺序处理以及全局层面上使用部分指令机制实现顺序约束执行的联合协调。
Qumulo DB采用两阶段锁(2PL)协议部署用于一致性的串型指令运行。串型操作分布到全部bstores中执行,并且执行操作顺序可以重新构造这是由私有的技术来保证的。SBS方法的优越性是处理IO操作会用到绝对最少数量的锁操作,同时这就使得QF2集群可以扩充到数百个节点。
冷/热分层实现读/写优化
SBS内置了冷热数据分层技术以优化读写性能。
本地部署时,QF2充分利用了SSD的速度优势和传统机械盘的廉价优势。SSD配合HDD在每个节点上存在。这个配合方法被称为虚拟磁盘。系统中每个HDD都有一个虚拟磁盘。
数据总是被首先被写到SSD上。因为读操作典型的是访问最近写入的数据,SSD总是扮演缓存的角色。当SSD的空间占用接近80%的时候,非频繁访问的数据被推送到HDD上。HDD为大尺寸的数据提供存储空间顺序读写操作。
云部署时,QF2借助匹配高性能块存储和廉价低性能块存储优化块存储资源的使用。
看一下下列SBS热冷分层的因素:
如何写和往哪里写数据
元数据往哪里写
数据何时失效
数据如何缓存和读取
初始写
对一个集群的写操作,一个客户端发送数据到一个节点。该节点选取一个或多个pstores存放数据,对于硬件来说,总是写到SSD或者云环境下的低延迟的块存储资源上。(回想一下,本地部署的SSD和云部署的低延迟块存储,我们的使用方法是类似的)。这些SSD分布于多个节点上。
所有的写操作都是面向SSDs;SBS从来不直接写入HDD。即便是一个SSD已被写满,系统也会清除前面缓存的数据� �这些新数据腾出空间。

元数据处理
通常来说,元数据居于SSD上。数据典型的被写入到bstore的低可用地址上所以bstore数据的增长是从开始直到存满。元数据的存放是相反的,从bstore的结尾往它的开始方向增长。这就是说元数据在用户数据的右边。下图显示了bstore中元数据的存放位置。

QF2在SSD上的bstore中为元数据分配了最多不到1%的空间并且永久有效。这1%空间中的数据永远不会推送到HDD上,如果元数据的大小超过1%就会失效,但是典型工作负载仅有接近1%的元数据量。如果没有足够的元数据量空间也不会浪费,其他数据也可以占用这个空间。
数据失效
在一些关键点上,系统需要更多的SSD上的空间所以一些数据会失效,或者从SSD移到HDD。把数据从SSD拷贝到HDD,而后一旦数据存到了HDD,就被从SSD上删除。
失效操作始于一个SSD的所用空间已达80%,停止于空间占用返回到小于80%。这个80%的门槛是一个摸索出来的目的在于优化性能 – SSD空间占用在0%到80%之间时写操作非常快同时失效也不会出现。
在数据从SSD被移动到HDD时,SBS会优化顺序写到HDD,这也是为了优化磁盘性能。填满大的、连续的字节对写HDD来说可能是最高效的方法。
缓存数据
下面的说明显示了所有QF2的缓存。所有的绿色部分都是能存储数据的地方,它既可能在SSD上,也可能在HDD上。

QF2的IO操作使用了三种不同类型的缓存。客户端总是会有一些缓存,存储节点上有两类缓存。一种是交易缓存,可以被认为是客户端直接请求的文件系统数据。另一种类型是磁盘缓存,用于来自磁盘的数据块保存在内存中。
作为一个举例,假定一个客户端连接到节点1上启动了一个文件X的读操作。节点1发现这些数据块驻留在节点2上所以知会节点2想要这些数据,本例中数据存储在节点2 的SSD上。节点2读取该数据并将其置于与这个SSD关联的磁盘缓存中。节点2回复节点1并且发送这个数据。此时这个数据进入节点1的交易缓存,而后知会客户端它有了文件X的数据。
连接这个磁盘的节点是磁盘缓存所在的节点。而连接客户端的节点是交易缓存所在的节点。磁盘缓存存有数据块数据而交易缓存存有实际文件数据。交易缓存和磁盘缓存共享内存,但是并没有一个特定的数量分配给他们中的任何一个。
工业标准协议
QF2采用了标准的NFSv3和SMBv2.1协议。
REST API
QF2囊括了丰富的REST API。事实上QF2 GUI所呈现的全部信息都是生成于QF2 RESTAPI调用。GUI中的每个键都提供一个可用REST API调用的自描述资源。可以在运行的集群上执行这些调用验证这些API,实时检测请求和结果。这是一个举例的截屏。
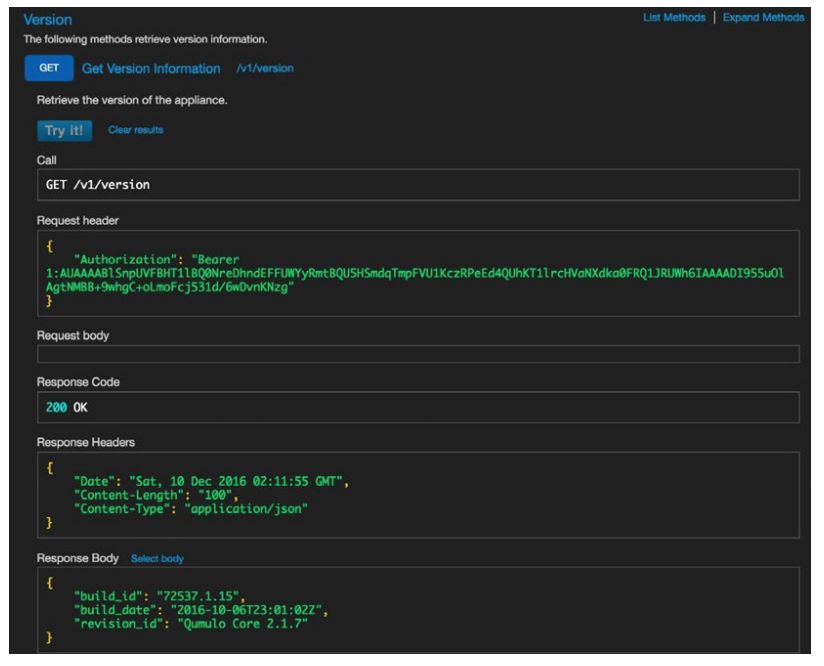
所有呈现的GUI分析信息都可以用REST调用API编程取回,存储在外部数据库中,或传递给像Splunk和Tableau这样的其他应用系统。大部分的文件� �统操作也可以由REST API请求执行。
结论
期待本文揭示了QF2的内在秘密并且能被理解,让读者明白为什么QF2性能出色、扩张能力超强的原理。如有更多的兴趣,请联系我们。
关键内容
* 数据爆炸式增长,现代工作负荷是PB规模,数十亿文件数量,文件大小不一。
* 很多存储系统还基于数十年前的技术,无法应对当今的工作负载。
* QF2是一个现代技术存储系统,特别针对当今工作负载。
* QF2基于标准商用硬件,可本地部署,可云中部署。
* QF2使用了SSD和HDD的混合体系架构。
* QF2采用实际文件系统下面的块保护机制。
* QF2具备快速重构能力,以小时计,是业界最快的。
* 用户文件可以占用100%的呈现容量。
* 小文件和大文件一样高效。
* 整个文件系统像一个单一卷一样存在。
* QF2的文件系统采用了与大型分布式数据库一样的技术。
* 实时分析给出文件系统当前发生事件的洞察力。
* 使用空间的精确报表。
* 管理员可实施实时限额。
* 管理员明晰删除快照的精确回收空间。
* QF2具备异步数据复制功能。
* QF2支持NFS和SMB标准协议,丰富的REST API。
---译文结束---
作者:乐生活与爱IT