百度AI-7Days-打卡集训营总结
本次打卡一共有7次授课,5次任务。
Day1:简单的格式化输出和os库的简单应用
Day2:爬取选手信息(自写爬取图片)
Day3:《青春有你2》选手数据分析
Day4:《青春有你2》选手识别
Day5:综合大作业
第一次作业的内容:
1、输出 9*9 乘法口诀表(注意格式)
2、查找特定名称文件
1、输出 9*9 乘法口诀表(注意格式):
这道题属于甜品级别的题目
直接格式化输出即可
def table():
for i in range(1, 10):
for j in range(1, i + 1):
print("{}*{}={}".format(j, i, j*i),"\t", end="")
print("\n")
1*1=1
1*2=2 2*2=4
1*3=3 2*3=6 3*3=9
1*4=4 2*4=8 3*4=12 4*4=16
1*5=5 2*5=10 3*5=15 4*5=20 5*5=25
1*6=6 2*6=12 3*6=18 4*6=24 5*6=30 6*6=36
1*7=7 2*7=14 3*7=21 4*7=28 5*7=35 6*7=42 7*7=49
1*8=8 2*8=16 3*8=24 4*8=32 5*8=40 6*8=48 7*8=56 8*8=64
1*9=9 2*9=18 3*9=27 4*9=36 5*9=45 6*9=54 7*9=63 8*9=72 9*9=81
2、查找特定名称文件:
这道题需要用到os模块中的walk方法
取出os.walk()中的三个值并赋给三个元素
使用for in 语句调用生成器fn
在循环中使用x.find()方法,如果返回>=0则找到目标文件之一
并保存给result列表
def findfiles():
global result, path
for dp, dn, fn in os.walk(path):
for x in fn:
if(x.find(filename) >= 0):
result.append(x)
for i in range(1, len(result) + 1):
print("{} : {}".format(i, result[i-1]))
1 : 04:22:2020.txt
2 : 182020.doc
3 : new2020.txt
但要求格式输出应该是带有根目录的输出
导致分数只有85分
将其修改为:
def findfiles():
global result, path
for dp, dn, fn in os.walk(path):
for x in fn:
if(x.find(filename) >= 0):
result.append(os.path.join(dp, x))
for i in range(1, len(result) + 1):
print("{} : {}".format(i, result[i-1]))
最后输出结果:
1 : Day1-homework/18/182020.doc
2 : Day1-homework/4/22/04:22:2020.txt
3 : Day1-homework/26/26/new2020.txt
Day2
第二次作业的内容:
《青春有你2》选手信息爬取
其中除了爬取选手图片模块,其他代码块训练营已经给出
这一次作业对于我这种爬虫小白来说还是有一定的难度
具体看步骤3
1、爬取百度百科中《青春有你2》中所有参赛选手信息,返回页面数据
直接爬取百度百科静态页面,没什么好说的,直接使用requests和bs4库即可
import json
import re
import requests
import datetime
from bs4 import BeautifulSoup
import os
#获取当天的日期,并进行格式化,用于后面文件命名,格式:20200420
today = datetime.date.today().strftime('%Y%m%d')
def crawl_wiki_data():
"""
爬取百度百科中《青春有你2》中参赛选手信息,返回html
"""
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
url='https://baike.baidu.com/item/青春有你第二季'
try:
response = requests.get(url,headers=headers)
soup = BeautifulSoup(response.text,'lxml')
tables = soup.find_all('table',{'class':'table-view log-set-param'})
crawl_table_title = "参赛学员"
i = 1
for table in tables:
table_titles = table.find_previous('div').find_all('h3')
for title in table_titles:
if(crawl_table_title in title):
return table
except Exception as e:
print(e)
2、对爬取的页面数据进行解析,并保存为JSON文件:
对表格的每一个属性进行爬取,并保存到json文件中
def parse_wiki_data(table_html):
table_html = crawl_wiki_data()
bs = BeautifulSoup(str(table_html),'lxml')
all_trs = bs.find_all('tr')
error_list = ['\'','\"']
stars = []
for tr in all_trs[1:]:
all_tds = tr.find_all('td')
star = {}
#姓名
star["name"]=all_tds[0].text
#个人百度百科链接
star["link"]= 'https://baike.baidu.com' + all_tds[0].find('a').get('href')
#籍贯
star["zone"]=all_tds[1].text
#星座
star["constellation"]=all_tds[2].text
#身高
star["height"]=all_tds[3].text
#体重
star["weight"]= all_tds[4].text
#花语,去除掉花语中的单引号或双引号
flower_word = all_tds[5].text
for c in flower_word:
if c in error_list:
flower_word=flower_word.replace(c,'')
star["flower_word"]=flower_word
#公司
if not all_tds[6].find('a') is None:
star["company"]= all_tds[6].find('a').text
else:
star["company"]= all_tds[6].text
# print(star)
stars.append(star)
json_data = json.loads(str(stars).replace("\'","\"")) # 将单引号转变为双引号
with open('work/' + today + '.json', 'w', encoding='UTF-8') as f:
json.dump(json_data, f, ensure_ascii=False)
# 汉字一定要加ensure_ascii=False
3、爬取每个选手的百度百科图片,并进行保存(自写代码块):
由于刚开始没有分析清楚,直接爬取了img标签的src
导致爬取的图片全部都是缩略图
重新整理思路:
a) 进入选手图集的第一张图片地址
b) 获取图集中其他图片的整个a标签而非img标签
c) 获取每一个a标签的href
此时获取的href才为图集中,每个图片的地址
d) 这个地方还有一个坑:
百度图册每次只能动态加载30张图片
但有一位选手有超过30张图片导致无法全部爬取
所以使用get(“href”)方法时会报错
需要try except捕捉错误并continue
至于如何爬取全部的图片,到现在还没有解决办法
e) 最后使用find(‘img’, {‘id’: ‘imgPicture’}).get(“src”)获取高清图地址并下载保存
def crawl_pic_urls():
with open('work/'+ today + '.json', 'r', encoding='UTF-8') as file:
json_array = json.loads(file.read())
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
for star in json_array:
pic_urls = []
name = star['name']
link = star['link']
try:
response = requests.get(link, headers = headers)
soup = BeautifulSoup(response.text, 'lxml')
tables = soup.find_all('div',{'class':'summary-pic'})
for table in tables:
summary_pic_url = "https://baike.baidu.com" + table.find("a").get("href")
response = requests.get(summary_pic_url, headers = headers)
soup = BeautifulSoup(response.text, 'lxml')
img_div = soup.find('div', {'class':'pic-list'})
# tag
img_page_list = img_div.find_all("a")
for img_page_list_elm in img_page_list:
try:
# 有可能没有href属性 所以要try except
img_page_url = 'https://baike.baidu.com' + img_page_list_elm.get("href")
except:
continue
response = requests.get(img_page_url, headers=headers)
soup = BeautifulSoup(response.text, 'lxml')
img_url = soup.find('img', {'id': 'imgPicture'}).get("src")
pic_urls.append(img_url)
except Exception as e:
print(e)
down_pic(name,pic_urls)
def down_pic(name,pic_urls):
path = 'work/' + 'pics/' + name + '/'
if not os.path.exists(path):
os.makedirs(path)
for i, pic_url in enumerate(pic_urls):
try:
pic = requests.get(pic_url, timeout=15)
string = str(i + 1) + '.jpg'
with open(path+string, 'wb') as f:
f.write(pic.content)
print('成功下载第%s张图片: %s' % (str(i + 1), str(pic_url)))
except Exception as e:
print('下载第%s张图片时失败: %s' % (str(i + 1), str(pic_url)))
print(e)
continue
4、打印输出
def show_pic_path(path):
pic_num = 0
for (dirpath,dirnames,filenames) in os.walk(path):
for filename in filenames:
pic_num += 1
print("第%d张照片:%s" % (pic_num,os.path.join(dirpath,filename)))
print("共爬取《青春有你2》选手的%d照片" % pic_num)
而后运行发现,百度图册更新了一张图片
不再是482 变成483
第479张照片:/home/aistudio/work/pics/戴燕妮/13.jpg
第480张照片:/home/aistudio/work/pics/戴燕妮/14.jpg
第481张照片:/home/aistudio/work/pics/戴燕妮/6.jpg
第482张照片:/home/aistudio/work/pics/戴燕妮/3.jpg
第483张照片:/home/aistudio/work/pics/魏奇奇/1.jpg
共爬取《青春有你2》选手的483照片
Day3
第三次作业内容:
《青春有你2》选手数据分析
分别使用json和pandas处理json数据
使用matplotlib进行可视化数据分析
难度较上次简单
1、本次作业没有提前创建文件夹,需要自己创建
import os
def mkjpg(name):
path = '/home/aistudio/work/result/'
if not os.path.exists(path):
os.mkdir(path)
with open(path + name, 'wb') as f:
f.close()
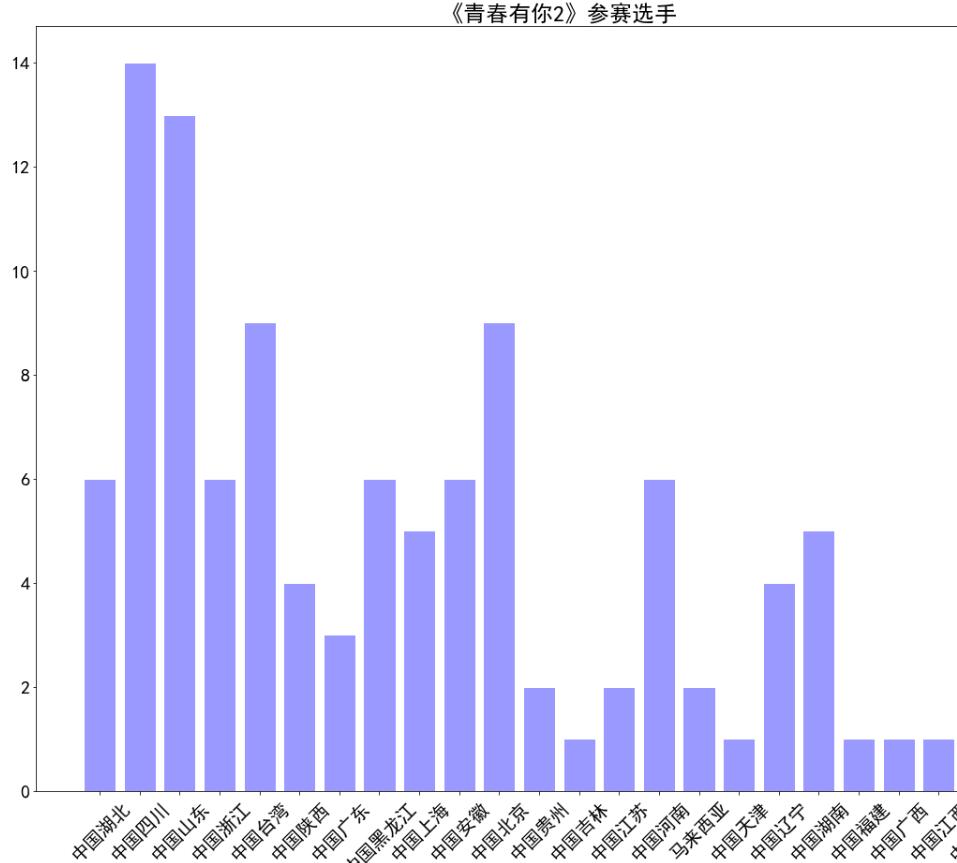
2、绘制选手区域分布柱状图
使用json库处理数据
中文字体问题:
1、plt.rcParams[‘font.sans-serif’] = [‘SimHei’]
2、别忘将字体文件复制到相应的字体库
3、可能notebook未加载字体,需要重启
import matplotlib.pyplot as plt
import numpy as np
import json
import matplotlib.font_manager as font_manager
import os
# 显示matplotlib生成的图形
%matplotlib inline
# 魔法函数(Magic Functions)
# 内嵌绘图
with open('data/data31557/20200422.json', 'r', encoding='UTF-8') as file:
json_array = json.loads(file.read())
with open('data/data31557/20200422.json', 'r', encoding='UTF-8') as file:
json_array = json.loads(file.read())
# 绘制小姐姐区域分布柱状图,x轴为地区,y轴为该区域的小姐姐数量
# print(json_array)
zones = []
for star in json_array:
zone = star['zone']
zones.append(zone)
print(len(zones))
print(zones)
zone_list = []
count_list = []
for zone in zones:
if zone not in zone_list:
count = zones.count(zone) # 记录每个地区的个数
zone_list.append(zone)
count_list.append(count)
print(zone_list)
print(count_list)
# 设置显示中文
plt.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体
plt.figure(figsize=(20,15)) # 设置窗口大小
plt.bar(range(len(count_list)), count_list,color='r',tick_label=zone_list,facecolor='#9999ff',edgecolor='white')
# 这里是调节横坐标的倾斜度,rotation是度数,以及设置刻度字体大小
plt.xticks(rotation=45,fontsize=20)
plt.yticks(fontsize=20)
plt.legend() # 左上角的标识,没有设置
plt.title('''《青春有你2》参赛选手''',fontsize = 24)
plt.savefig('/home/aistudio/work/result/bar_result.jpg')
plt.show()
 原创文章 1获赞 0访问量 12
关注
私信
展开阅读全文
原创文章 1获赞 0访问量 12
关注
私信
展开阅读全文
作者:Xero_Lee