(ICASSP 18)Temporal Modeling Using Dilated Convolution and Gating for Voice-Activity-Detection
会议:ICASSP 2018
论文:Temporal Modeling Using Dilated Convolution and Gating for Voice-Activity-Detection
作者:Shuo-Yiin Chang, Bo Li, Gabor Simko, Tara N Sainath, Anshuman Tripathi, Aäron van den Oord, Oriol Vinyals
语音活动检测(VAD)是预测话语的哪些部分包含语音与背景噪声的任务。确定要发送到解码器的样本以及何时关闭麦克风是重要的第一步。长短期记忆神经网络(LSTM)是用于声音信号顺序建模的一种流行架构,并且已成功用于多种VAD应用程序中。然而,已经观察到,当发声时间长时(即,对于语音命令任务),LSTM遭受状态饱和问题,因此需要周期性地重置LSTM状态。在本文中,我们通过通过无状态扩张卷积神经网络(CNN)对时间变化进行建模,提出了一种不会遭受饱和问题的替代架构。所提出的体系结构在三个方面与传统的CNN不同:它使用了因果卷积,门控激活和残余连接。Google语音键入任务的结果表明,与VAD任务的最新LSTM相比,所提出的体系结构在FR为1%时实现了14%的相对FA改进。我们还包括详细的实验,以研究将建议的体系结构与常规卷积区分开的因素。
Introduction在许多自动语音识别(ASR)应用中,VAD是识别语音并滤除背景噪音的重要组件。此类任务通常是ASR系统确定何时关闭麦克风的重要预处理阶段。简而言之,VAD减少了计算和等待时间,还指导了用户界面。
典型的VAD系统使用具有声学特征的帧级分类器为每个音频帧(每10ms)做出语音/非语音决策[1]。在典型的ASR系统中,VAD需要在具有挑战性的环境中准确工作,包括嘈杂的环境,混响的环境以及带有背景语音的环境。较差的VAD可能接受背景噪声(这会导致识别速度慢且昂贵),或者拒绝语音(增加删除错误)(几毫秒的音频丢失会删除整个单词)。
大量研究致力于找到最佳VAD模型[2] – [3] [4] [5] [6]。在文献中,LSTM是一种流行的体系结构,用于VAD任务的顺序建模,显示了最新的性能[2],[7]。从理论上讲,LSTM可以模拟任何历史的长度,因为它可以学会忘记过去。但是,在实践中,从数据中学到的门可能无法始终按预期运行。在Vad Tasks中,观察到Lstms在很长的话语中遭受状态饱和问题的困扰。解决此问题的一种方法是定期重置Lstm状态。但是,此方法有点特别,因为凭经验选择了重置状态的时间。
在本文中,我们提出了LSTM的建模替代方案,以解决饱和问题。已经探索了在时间上进行卷积的架构[8] – [9] [10] [11],作为一般声学建模任务的LSTM的替代方案。在本文中,我们采用WaveNet架构[9],该模型建模具有扩展卷积和门控激活的时间模式,如图1所示。
与传统的时间卷积相比,扩张型卷积通过跳过一些输入可以以更少的层数实现更宽的接收场。在提出的体系结构中,门控卷积激活用于精确控制信息流。同样,添加了剩余连接以简化非常深的神经网络的训练。
我们针对Google语音输入[12]上的VAD任务,将拟议的体系结构与LSTM进行了比较(使用您的声音来指示电话中的消息)。结果表明,在将误剔除率(FR)固定为1%时,所提出的体系结构在误报(FA)方面实现了14%的相对改进。
本文的其余部分如下。在第2节中,我们描述了所提出的神经网络架构。实验设置在第3节中介绍,结果和分析在第4节中介绍。最后,第5节总结了论文。
Neural Network Architecture以前在文献[8],[10],[13],[14]中已经探索了使用CNN的时间建模。在这项工作中,我们探索使用WaveNet样式架构进行时间建模。以前已经针对文本语音转换(TTS)应用程序[9]探索了这种体系结构,但尚未针对ASR或VAD上的声学建模探索这种体系结构。拟议的体系结构在三个方面与常规CNN不同:它使用(1)扩展因果卷积,(2)门控激活和(3)残留连接,所有这些都将在后续部分中进行描述。
2.1. Dilated Convolution
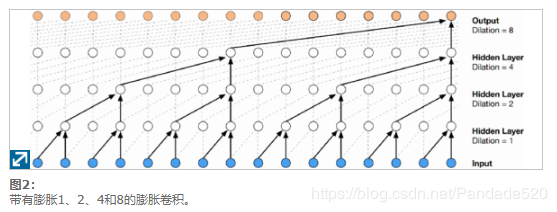
使用非经常性网络的时间建模通常依赖于输入上下文窗口。例如,在CNN中,卷积滤波器将相邻帧的窗口作为输入来捕获声学环境。使用密集的输入上下文窗口会增加模型参数的数量,在使用大型上下文窗口进行长时间建模时,这尤其是一个问题。为了解决这个问题,可以使用膨胀卷积(也称为圆环或带孔的卷积)[9],[15] – [16] [17] [18]采用卷积滤波器时,通过跳过某些输入值,将卷积滤波器应用于大于其长度的区域。它等效于通过从零开始对原始滤镜进行零扩散而得到的较大滤镜的卷积,但是效率明显更高。与普通卷积相比,散布的卷积有效地允许网络在更大的规模上运行。这类似于池化或跨步卷积,但此处的输出与输入的大小相同。作为一种特殊情况,带有卷积的散积卷积等效于标准卷积。堆叠的卷积堆栈使网络具有仅几层的非常大的接收场,同时保留了整个网络的输入分辨率和计算效率。
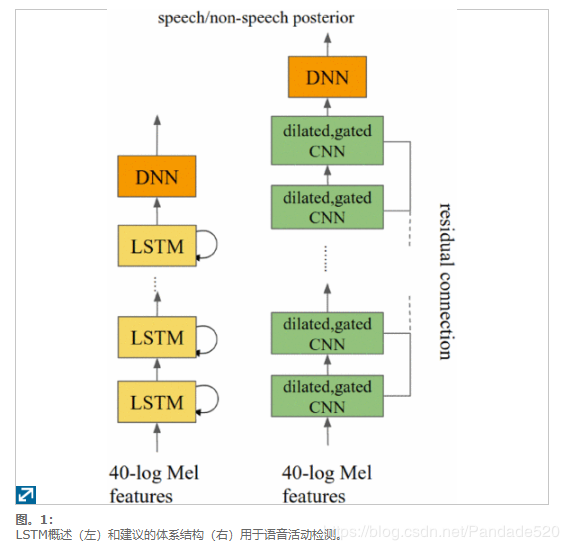
对于语音任务,尤其是终结任务,潜伏期除了准确性外,也是一个关键标准。通常,CNN过滤器会在左右两个上下文中使用历史记录和将来的信息来进行准确的预测。由于延迟是一个问题,因此我们需要限制使用正确的上下文。在[9]中,仅使用左上下文,即因果卷积就足以为TTS任务提供良好的预测性能。在这项工作中,我们对VAD 采用相同的扩张因果卷积(如图2所示)。
2.2. Gated Activation
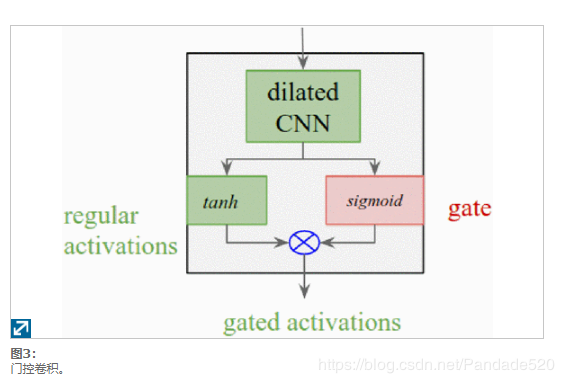
盖茨在LSTM建模中发挥重要作用[19] ,[20] ,因为它们的控制信息的时间的步骤和层之间的流动。在WaveNet中,采用了一种简单的选通机制来控制通过每一层的信息流。类似地,在这项工作中,我们通过首先将双曲正切非线性应用于膨胀卷积的输出,然后使用S型门对其进行衰减来使用门控(如图3所示)。细节略~
2.3. Residual Connection
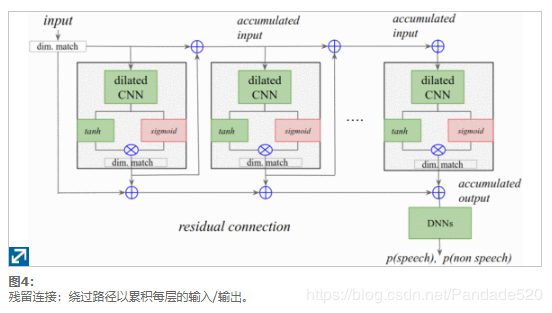
模型的深度对于学习鲁棒表示很重要,但同时也面临梯度消失的挑战。残差培训[21]被发现是解决此问题并建立非常深入的网络的有效方法。对于语音任务,LSTM并没有显示超过十层的改进[22],但是具有剩余连接的CNN却显示出了更多层的改进[21]。按照与WaveNet [9]相似的配置,我们还使用了每层之间的剩余连接,从而使我们可以训练一个36层的网络。通过累加各层的输出来创建旁路路径,如图4所示。。注意,小尺寸匹配层用于累加相同大小的输出。这些旁路路径被认为是简化非常深层网络训练的关键因素。
3.1. Data
我们对大约18,000小时的嘈杂训练数据进行了实验,这些数据包含大约650万种英语发音。该数据集是通过使用模拟器人为破坏干净的语音以添加不同程度的噪声和混响而创建的[23]。干净的语音是匿名的和手动转录的语音键入录音,代表了Android上的Google语音键入流量。噪声信号(包括从YouTube采样的音乐和环境噪声以及日常生活环境的录音)以0至30 dB的SNR添加到纯净说话中,平均SNR为11 dB。我们使用模拟的噪声数据评估模型。大约15个小时(使用了13K匿名Android语音键入语音)。使用模拟器添加的噪声具有与训练配置大致匹配的配置分布。噪声摘要不会与训练重叠。
3.2. Model Configuration
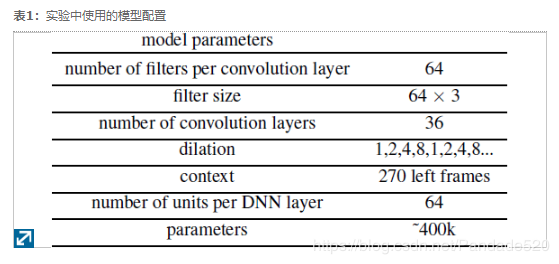
用于所有实验的声学特征是40维对数梅尔滤波器组能量,它是使用每10ms计算出的25ms长滑动窗口产生的。表1显示了我们的实验中使用的配置。具体来说,我们为每个卷积层使用了64个滤镜。过滤器大小为3帧64天输入激活。我们使用了36个卷积层,其扩散速率重复了1、2、4和8。给定上述设计参数,总共使用了270帧的左上下文。在我们的实验中,添加超过36个额外的隐藏层并不能提高性能。
对于基线LSTM配置,我们使用了10层LSTM。每层由64个存储单元组成。我们还将残余连接应用于LSTM,以简化对更深层模型的训练。同样,添加额外的LSTM层并不能提高性能。对于LSTM和卷积模型,参数总数约为40万。卷积层或LSTM的输出被馈送到具有64个隐藏单元的DNN层,最后是具有2个输出目标(语音和非语音)的softmax层。
所有网络都使用异步随机梯度下降(ASGD)进行交叉熵准则训练[24]。使用[25]中所述的Glorot-Bengio策略初始化DNN层的权重,同时将所有LSTM参数统一初始化为-0.02至0.02。我们使用2e-5的恒定学习率。
在本节中,我们介绍使用膨胀卷积和门控构建VAD的实验结果。
4.1. Results Using Proposed Architecture Vs LSTM
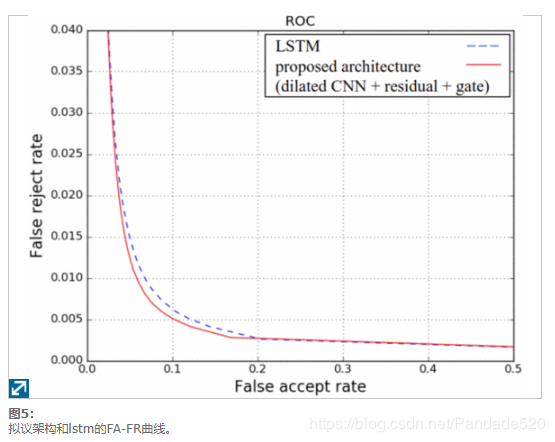
FA-FR(错误接受与错误拒绝)曲线通常用于描述二进制分类任务。在这里,我们报告用于语音分类的FA-FR曲线,其中语音后验被阈值化以获得VAD决策。在这种情况下,错误接受(FA)是错误的预测,当音频帧实际上是非语音时,会将音频帧分类为语音。同样,错误拒绝(FR)是被误分类为非语音的语音帧。两项指标越低越好。如图5所示,提出的体系结构提供了比LSTM更好的FA / FR。具体而言,如表2所示,在1%FR的工作点上,FA相对提高了14%。

4.2. Results Using Proposed Architecture Vs Conventional CNN
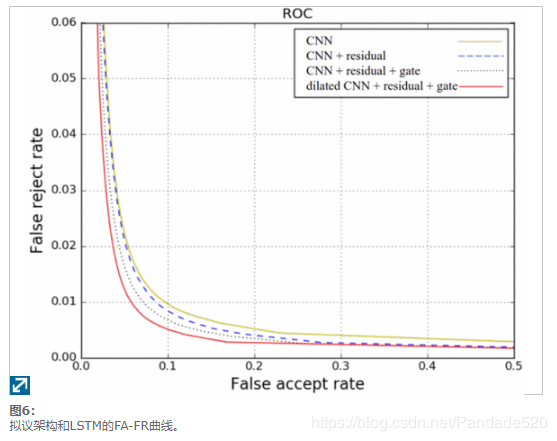
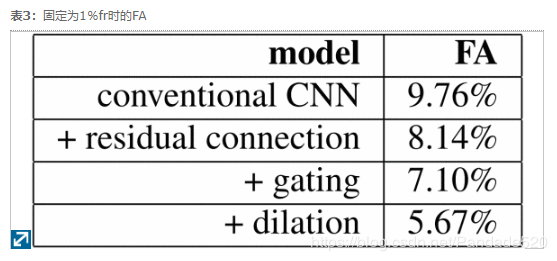
接下来,我们进一步分析了提出的体系结构中与传统CNN区别的关键因素的重要性,这些因素不包括扩张,门控激活和残余连接。图6显示了常规CNN,具有残余连接的CNN,具有门控和残余连接的CNN和具有门控和残余连接的膨胀CNN的FA-FR曲线。如果没有剩余连接,则添加20个以上的卷积层时性能会迅速下降。因此,这项工作中报道的传统CNN仅使用20个卷积层,而其他的则具有36个卷积层。如表3所示通过残余连接实现了16.6%的改进,而门控制则使FA相对降低了14%,而卷积膨胀又相对降低了19%。
4.3. Robustness to Long Audio Signals
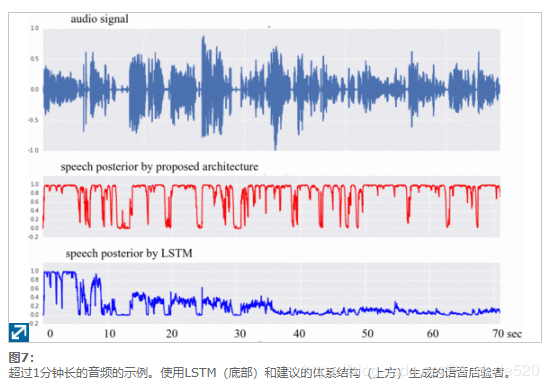
为了进一步了解通过扩展卷积获得的增益,图7显示了LSTM网络和所提议的扩展卷积网络对1分钟以上长的音频信号的每个帧产生的语音后验的比较。在患者的同意下,从医生与患者之间的医疗对话中收集音频[26]。如图7所示,在处理40秒钟的音频后,LSTM陷入死音状态并开始拒绝音频(语音后验接近于零)。另一方面,由于其无状态设计,所提出的体系结构对于处理更长的音频具有鲁棒性。
在这项研究中,我们探索了一种神经网络体系结构,该结构结合了扩张卷积,门控和残余连接等关键部分,用于语音活动检测。在Google语音输入任务上进行的实验表明,将FR固定为1%时,与LSTM相比,所提出的体系结构FA相对提高了14%。分析表明,对卷积激活的门控制和使用扩展卷积的更宽的接收场均有助于改善。最后,所提出的体系结构对于处理更长的音频更加健壮。
作者:IMU_Pandade