CS224n 斯坦福深度自然语言处理课笔记 Lecture03—高级词向量表示
word2vec的主要步骤是遍历整个语料库,利用每个窗口的中心词来预测上下文的单词,然后对每个这样的窗口利用SGD来进行参数的更新。
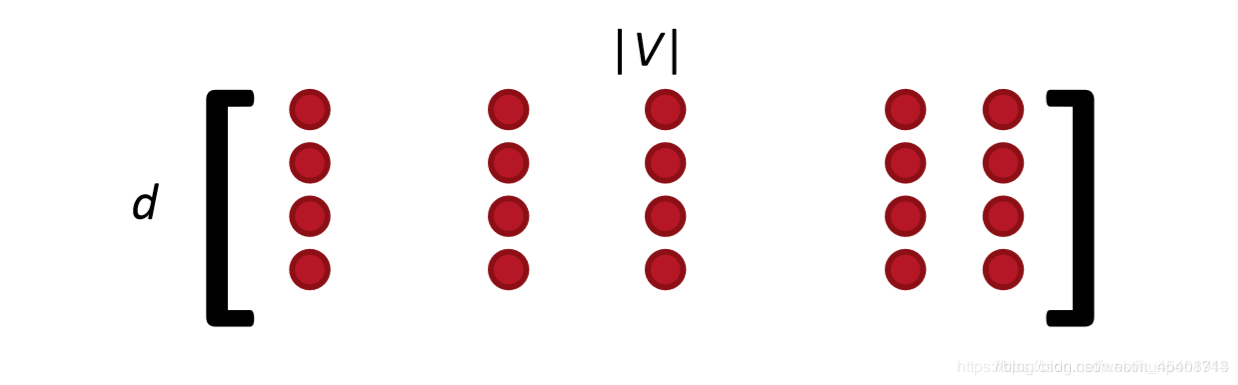
对于每一个窗口而言,我们只有2m+1个单词(其中m表示窗口的半径),因此我们计算出来的梯度向量是十分稀疏的。我们会在每个窗口更新损失函数。对于2dv的参数而言,我们只能更新一小部分。因此一个解决方法是提供一个单词到词向量的哈希映射。
在word2vec的计算中有一个问题是条件概率的分母计算很复杂。
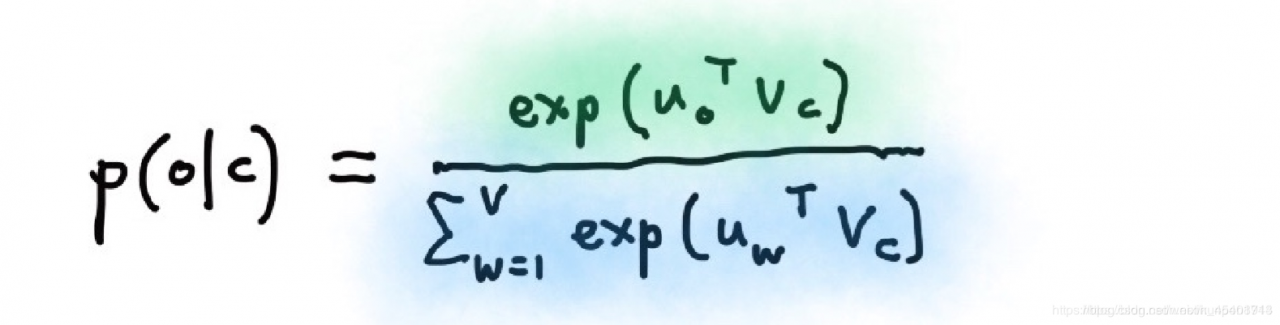
我们可以使用负采样来解决这个问题。负采样的中心思想是:只对可以配对的训练一些二元逻辑回归,因此我们保留了想要优化和最大化中心词和外围词内积的想法(分子),相对于遍所有单词,实际上只取一些随机单词并指明这些从语料库其余部分取出的随机词是不同时出现的。[ 训练一个二元逻辑回归,其中包含一对真正的中心词和上下文词,以及一些噪音对(包含中心词和一个随机的单词)。]
这种方法来源于这篇文献:“Distributed Representations of Words and Phrases and their Compositionality” (Mikolov et al. 2013)。
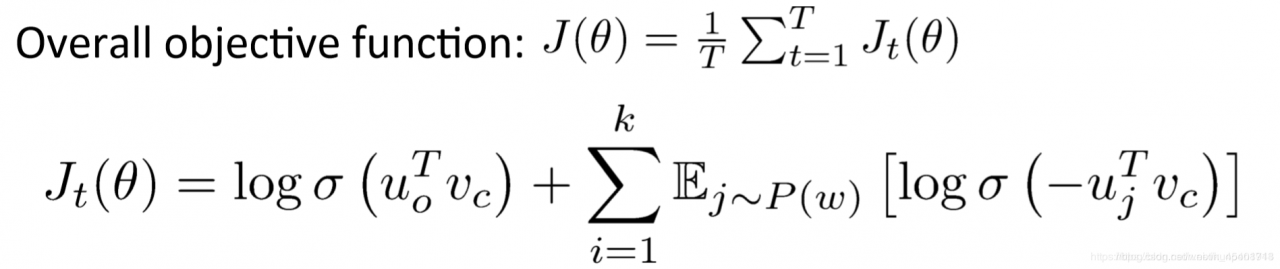
具体的目标函数如下,第一行:T对应需要遍历语料库的每个窗口;第二行:其中k表示的是负样本的个数,σ表示sigmoid函数(实际上sigmoid函数是把任意实数值压缩至0到1之间,方便学习时称它为概率),σ(-x)=1-σ(x),第一项是正样本,第二项是负样本。换而言之,目标函数表示我们希望真正的上下文单词出现的概率尽量大,而在中心词周围的随机单词出现的概率尽量小。
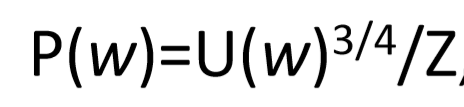
我们假设随机选取的噪音单词是遵循下面的公式,其中U(W)表示一元模型的分布,之所以加上一个3/4的幂是因为,希望减少那些常用的单词被选中的概率。

word2vec的另外一种算法是CBOW,主要的观点是:从上下文向量的和来预测中心词,正好与skip-grams相反。
word2vec通过对目标函数的优化,把相似的单词在空间中投射到邻近的位置。
二、直接计数方法&混合方法通过word2vec的原理的观察,我们可以发现实际上word2vec抓住的是两个单词同时出现(cooccurrence)的情况进行的建模。
方法是利用同时出现(co - occurrence)矩阵,我们可以统计整篇文章的同时出现(cooccurrence)情况,也可以像word2vec一样利用一个窗口来进行同时出现(cooccurrence)情况的统计,来抓住语义和句法上面的信息。
一个例子:窗口长度是1,一般窗口长度是5-10;左右两边的窗口长度是对称的,语料库示例:
I like deep learning.
I like NLP.
I enjoy flying.基于共现矩阵的窗口:
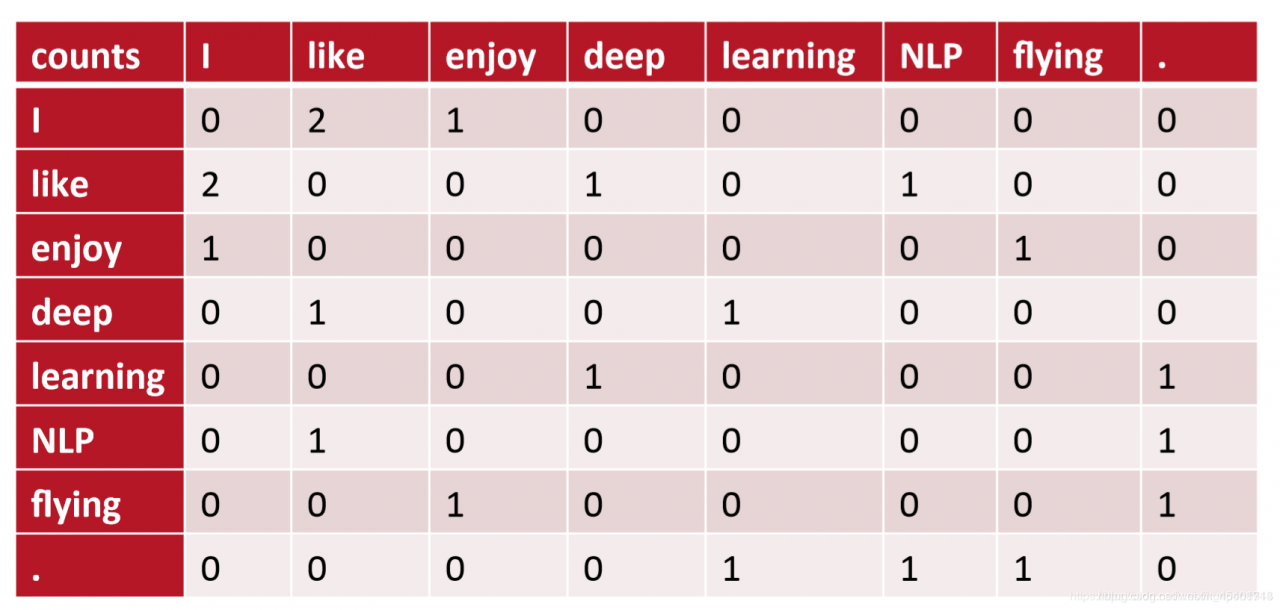
这个矩阵存在的问题是:词典有一个新单词,词向量就会改变。随着词汇的增长,存储矩阵需要的空间将会变得很大;这个矩阵十分稀疏,不利于模型的稳健构建。所以,我们需要寻找一个方法把这个矩阵降低维度。 方法一:对矩阵X进行降维
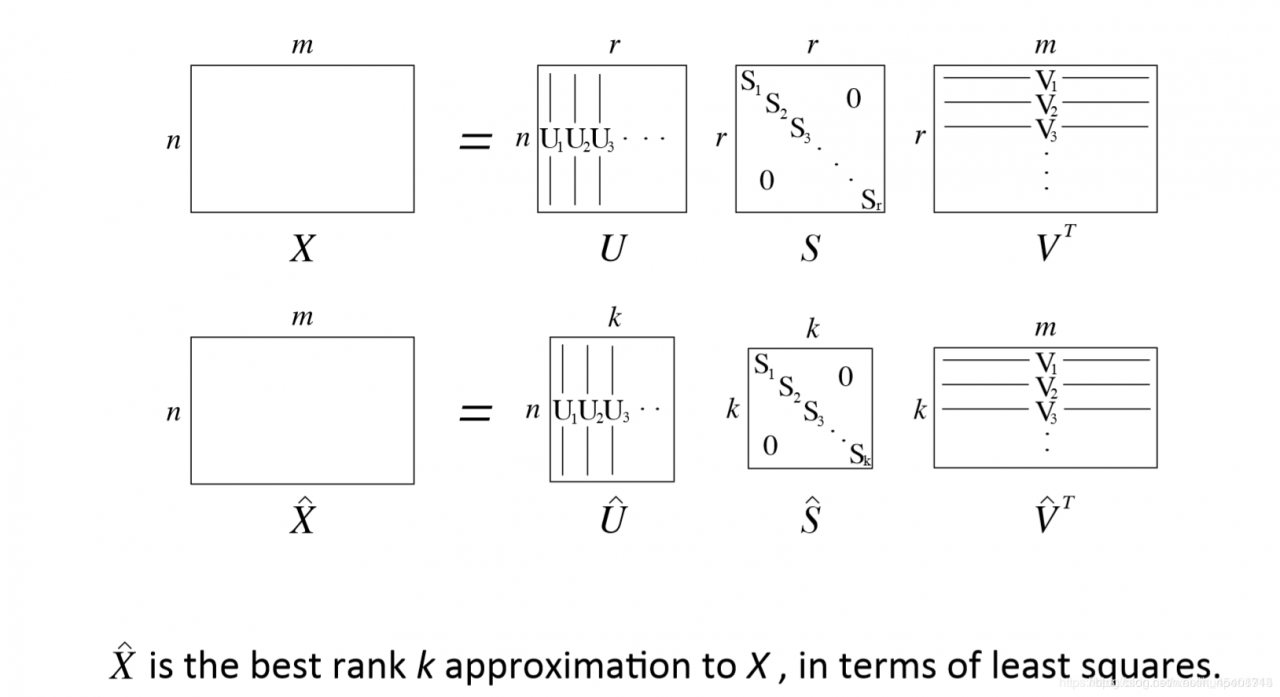
对矩阵进行奇异值分解(SVD)
import numpy as np
import matplotlib.pyplot as plt
la = np.linalg
words = ["I","like","enjoy","deep","learning","NLP","flying","."]
X = np.array([[0,2,1,0,0,0,0,0],
[2,0,0,1,0,1,0,0],
[1,0,0,0,0,0,1,0],
[0,1,0,0,1,0,0,0],
[0,0,0,1,0,0,0,1],
[0,1,0,0,0,0,0,1],
[0,0,1,0,0,0,0,1],
[0,0,0,0,1,1,1,0]])
U,S,V = la.svd(X, full_matrices=False)
#svd奇异值分解
print('U:', U)
print('S:', S )
print('V:', V )
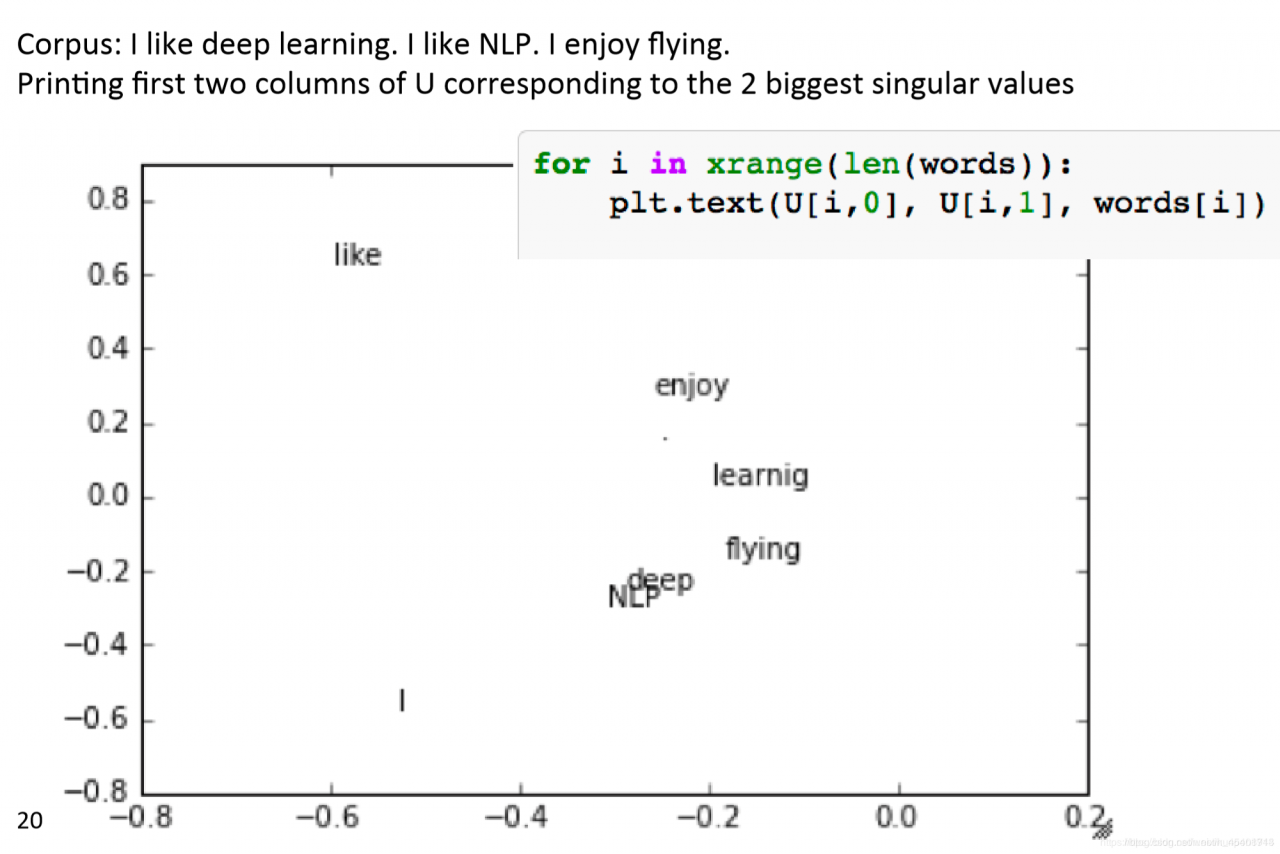
# 单词绘图
for i in range(len(words)):
plt.text(U[i, 0], U[i, 1], words[i])
plt.axis([-1, 1, -1, 1])
plt.show()
2005年,人们使用奇异值分解(SVD)方法,一个与其他方法如此不同的技巧来处理共现矩阵,对它进行了改善:

这是一种可视化高维空间的一个方法,通常向量在100维左右,很难去可视化它,相当于简单地映射到2维,这里仅选择几个词并且观察近邻词,即哪个词离其他词更近,比如WRIST与ANKLE 接近。
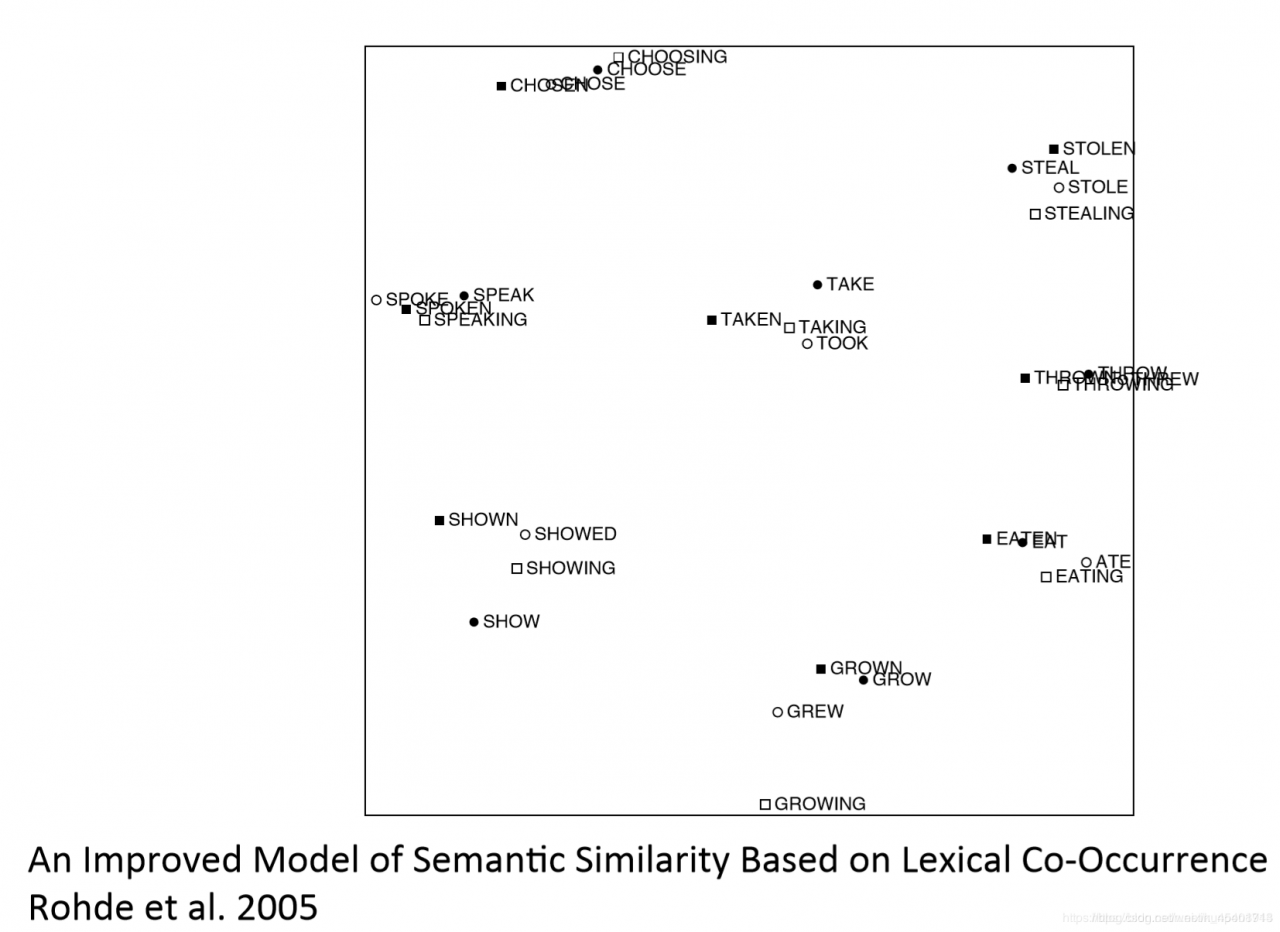

进一步,甚至动词的更多词义和这些类型的名词是非常相似并且相关的,经常出现在大致相似的欧氏距离中(例如:SWIM 与 SWIMMER),基本上有类似的向量差,一起出现的频率相当高,并且经常出现在相似的上下文中。
SVD存在的问题:
计算代价是O(mn²),对于大量的文本和单词而言,计算代价就会变得很大 很难把新的单词和矩阵整合进矩阵中往往会需要重新计算基于计数统计的共现矩阵方法VS基于窗口的预测方法
计数方法:训练起来更快;可以充分利用统计信息;主要用来计算单词的相似度;对那些出现频率很高的单词而言,给出的重要性是不成正比的 预测方法:随着语料库的大小而规模大小变换;不能有效运用统计信息;在其他的任务上有很好的表现;除了单词相似性以外还可以获得更复杂的模式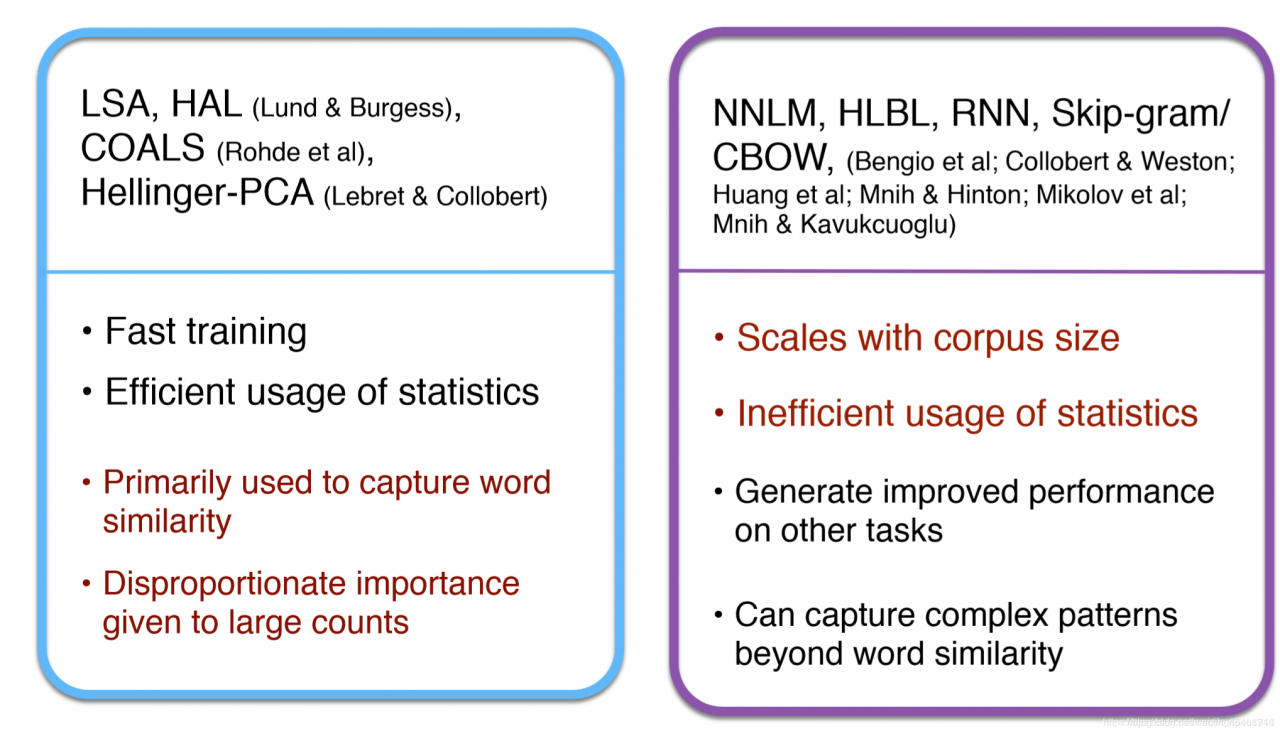
基于两者都各有优缺点,最终结果是GloVe模型,即全局向量(Global Vectors)模型。
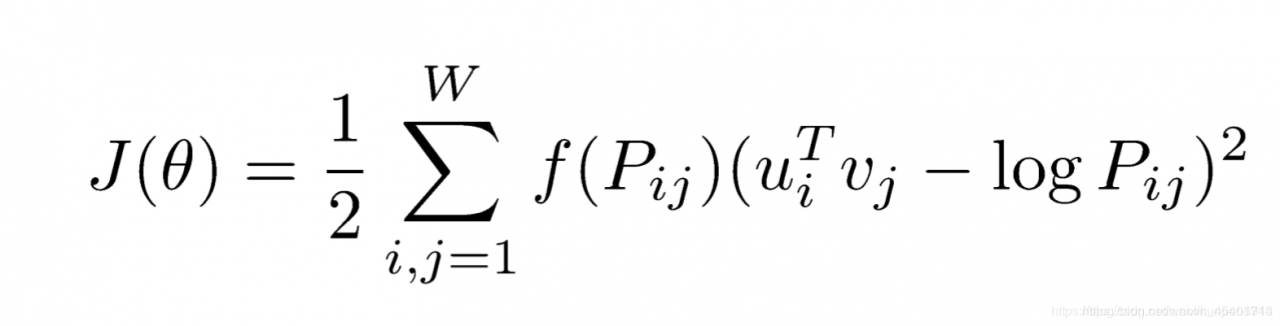
U、V更加对称,我们基本上会遍历所有可能贡献出现的词对。对语料库中的每一对词,我们希望最小化内积和计数对数之间的距离,一次仅优化一个计数,因此使用平方,然后 f 使得我们可以衡量甚至减少这些频繁共现的事件(共现矩阵P负责抑制相邻词之间的含义过分接近)。
其中f如下图,目的是控制出现次数比较多的单词对的权重。
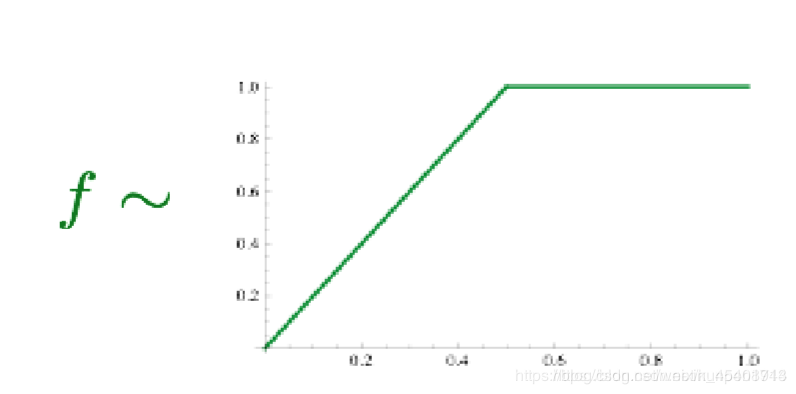 方法的特点:
方法的特点:训练起来很快;可以扩展成更大的语料库;在小的语料库和小的向量的情况下,表现也很好。
Skip-gram模型试图一次捕获同时出现的一个窗口,GloVe模型试图捕获这些单词词频的总体统计数据。
这个方法的训练结果是u和v两个矩阵,都代表了相似的同时出现(cooccurrence)的信息。最终,最好的X是U+V。
从Glove的训练结果来看,这个模型对比较稀有的单词也有比较好的效果。

NLP的评估分为两种,Intrinsic 和extrinsic
内部的(Intrinsic):
基于一个特定的中间的子任务;
计算起来很快;
帮助我们理解系统;
但是我们无法确定评估出来比较好的词向量是否真的可以在实际任务中发挥作用。
外部的(extrinsic):
基于一个实际任务进行评估;
可能需要花费很长的时间来计算正确率;
无法判断是这个子系统的作用,还是交互作用,还是其他子系统的作用;
如果只是替换了一个子系统,而正确率提升了的话,就说明这个子系统是有效的。
利用词向量类比词类进行评估,如下图,比如b代表woman,a代表man,c表示king,那么在剩下的单词中,正确的类比单词应该是cosine相似度最高的。在实际中应该是queen,通过判断d是不是queen可以用来评估这个词向量的构造情况。
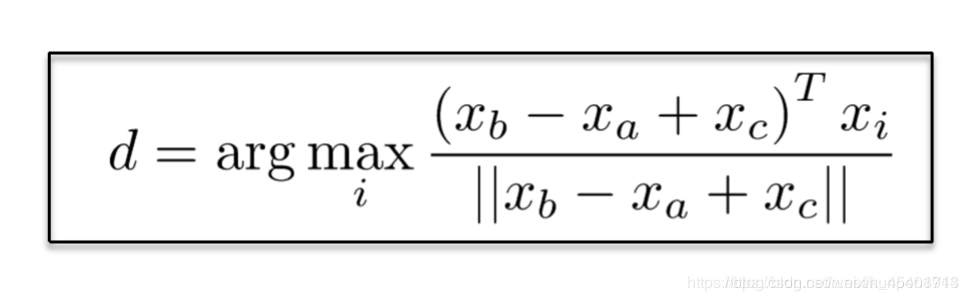
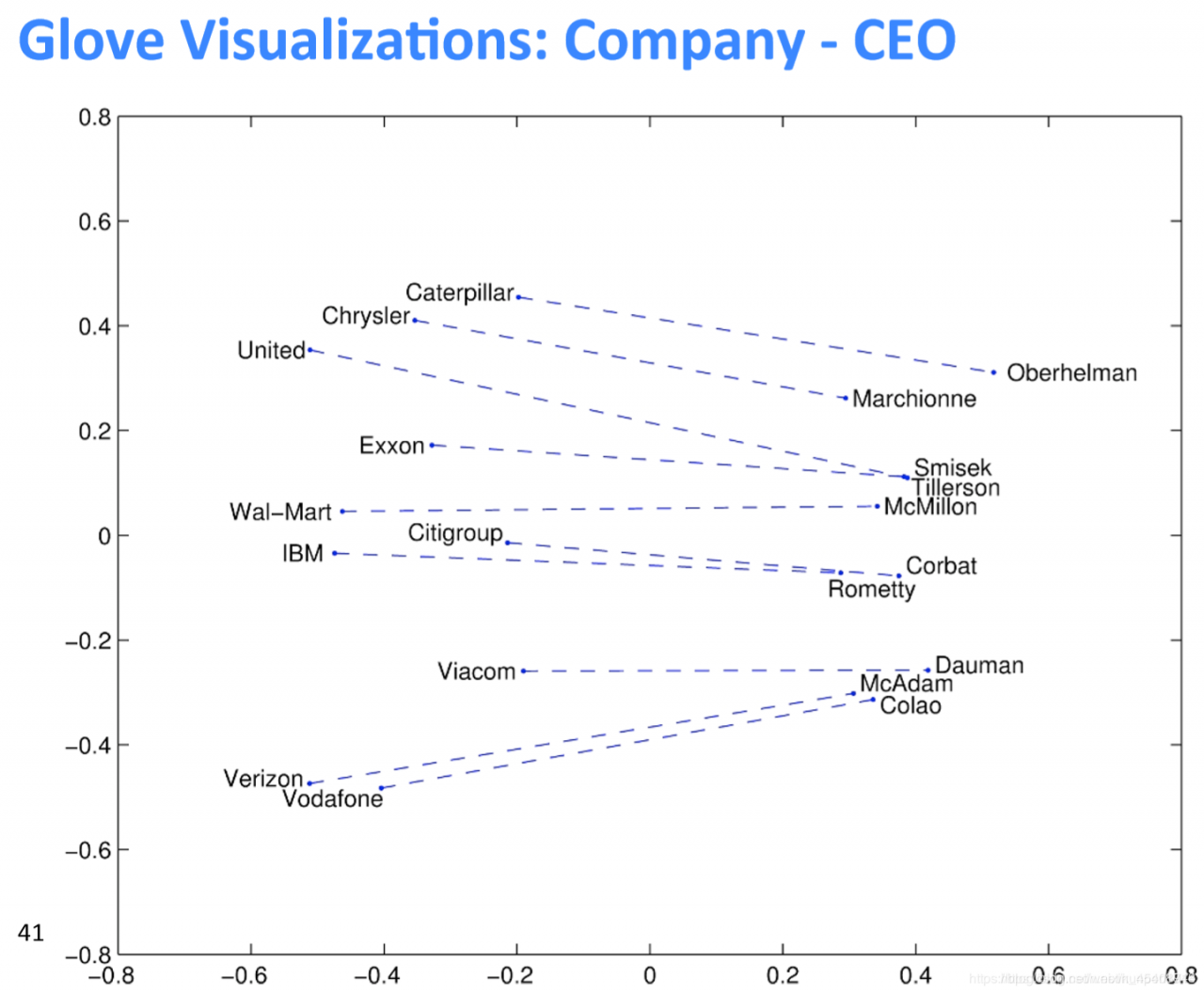

词向量类比词的一些例子:Word Vector Analogies: Syntactic and Semantic examples from http://code.google.com/p/word2vec/source/browse/trunk/quesRonswords.txt
利用词向量类比词进行评估和超参的选择
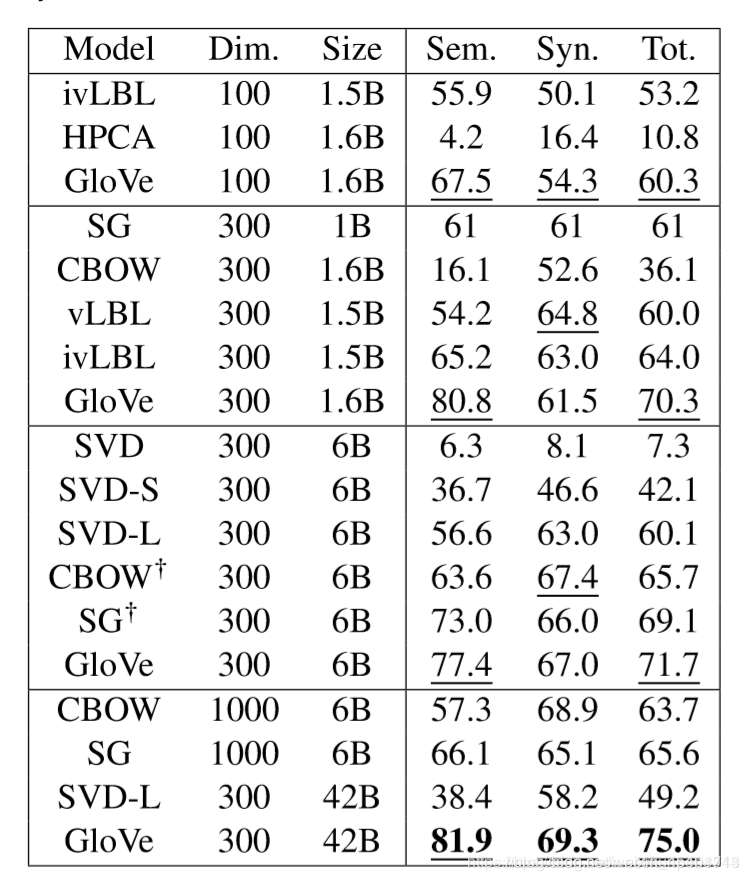
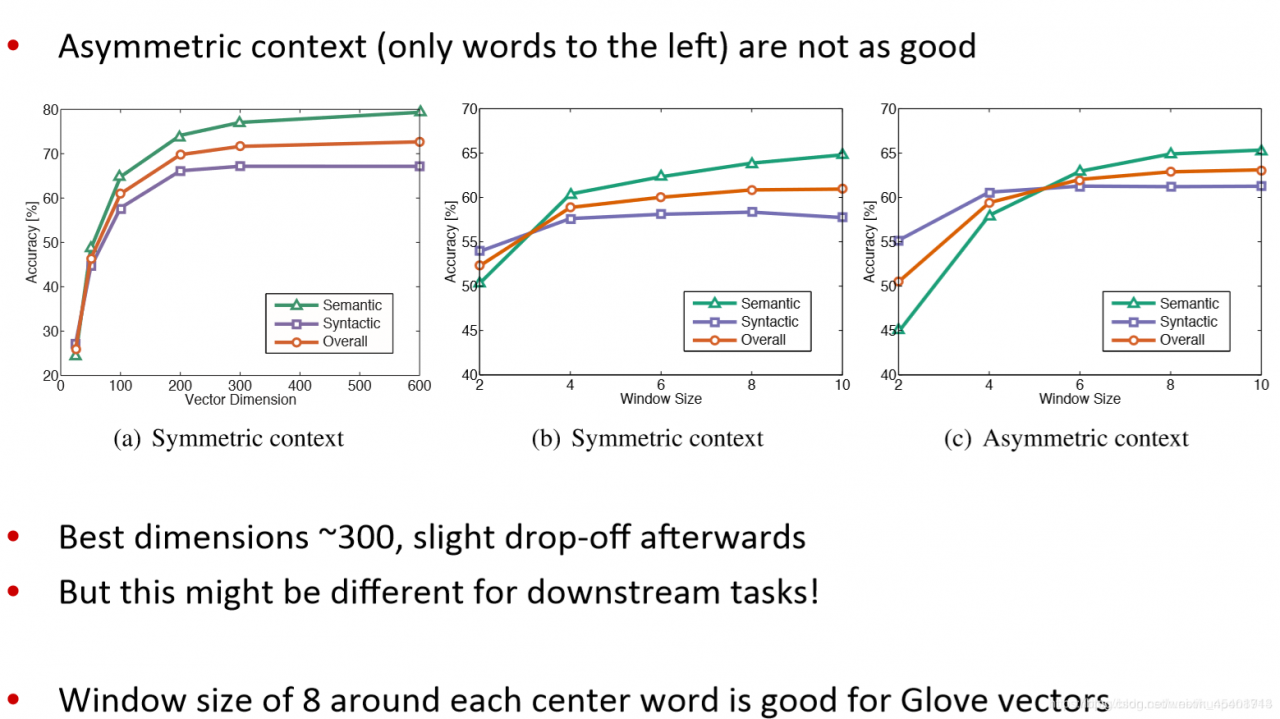
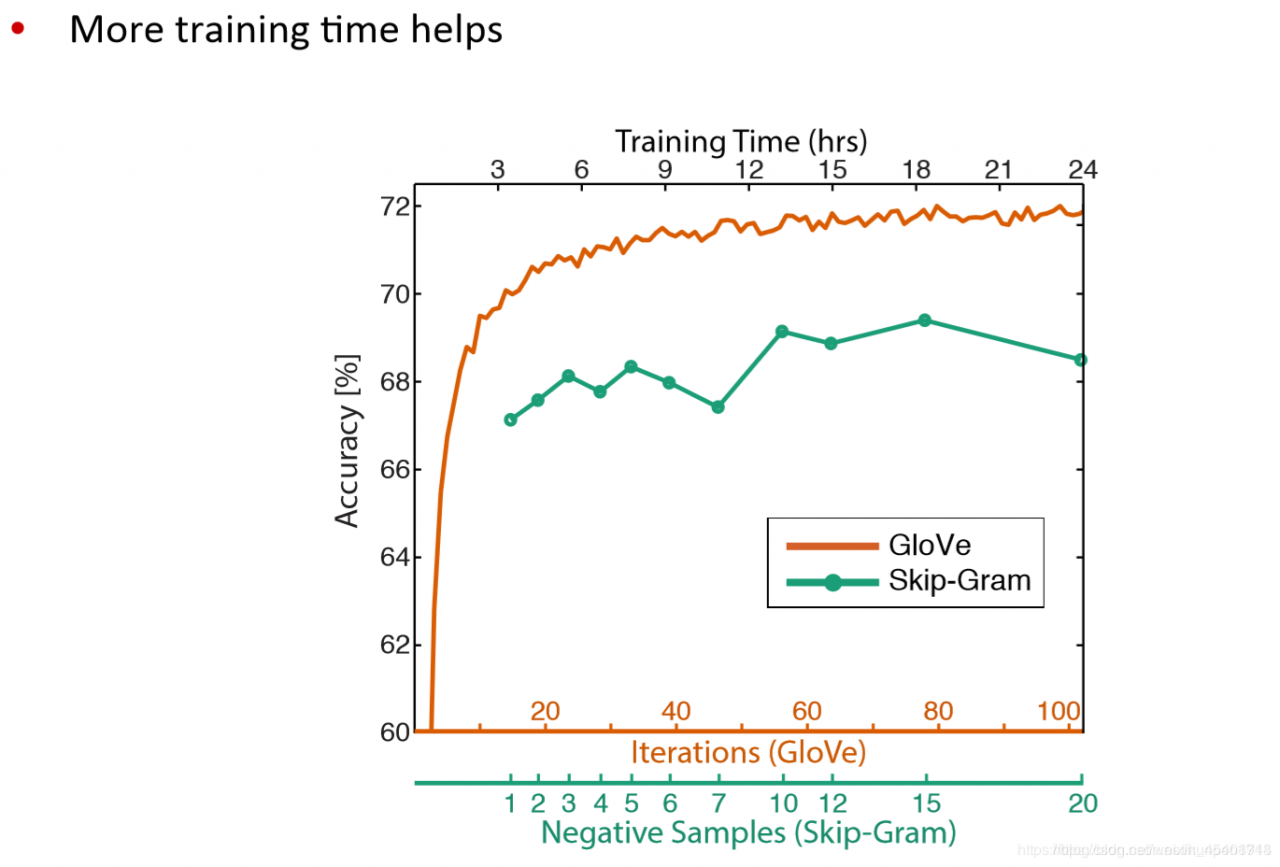
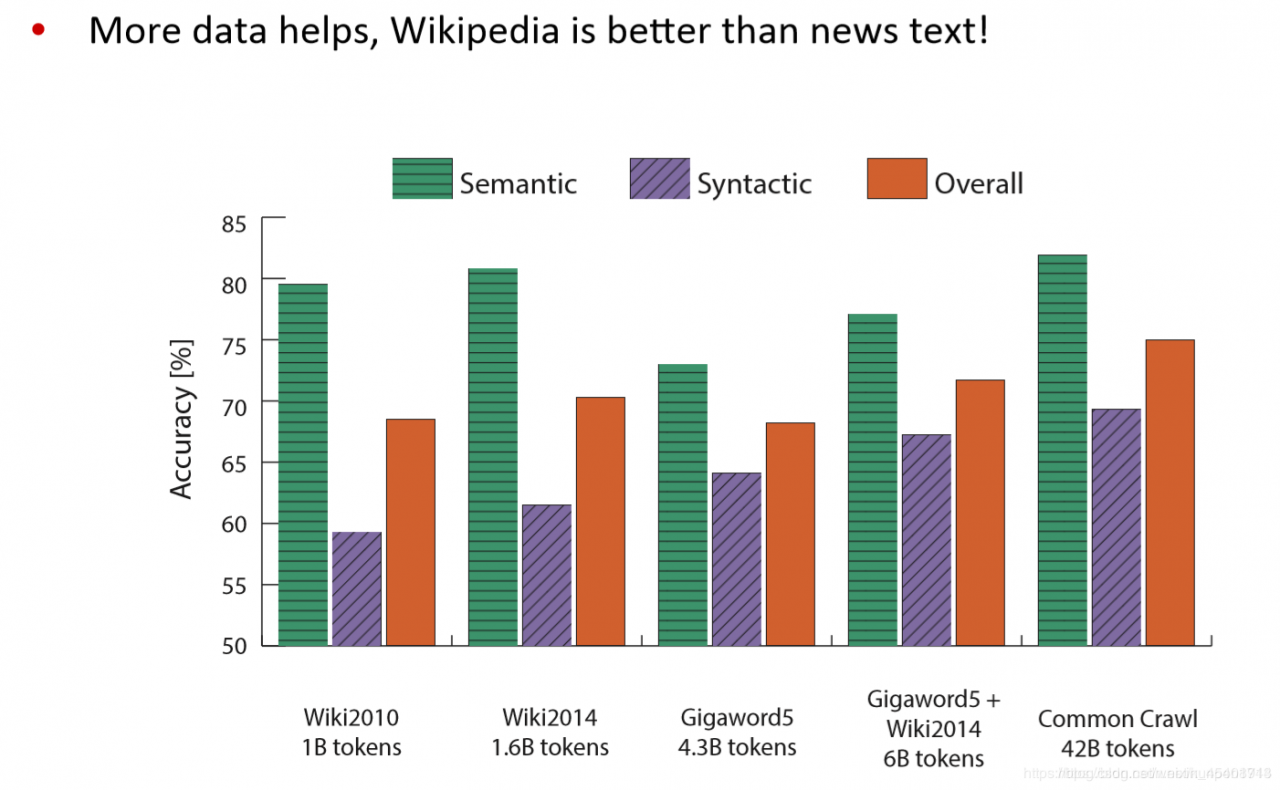
其他内部的词向量评估方法:计算词向量的距离以及人工判断之间的相关性(correlation)
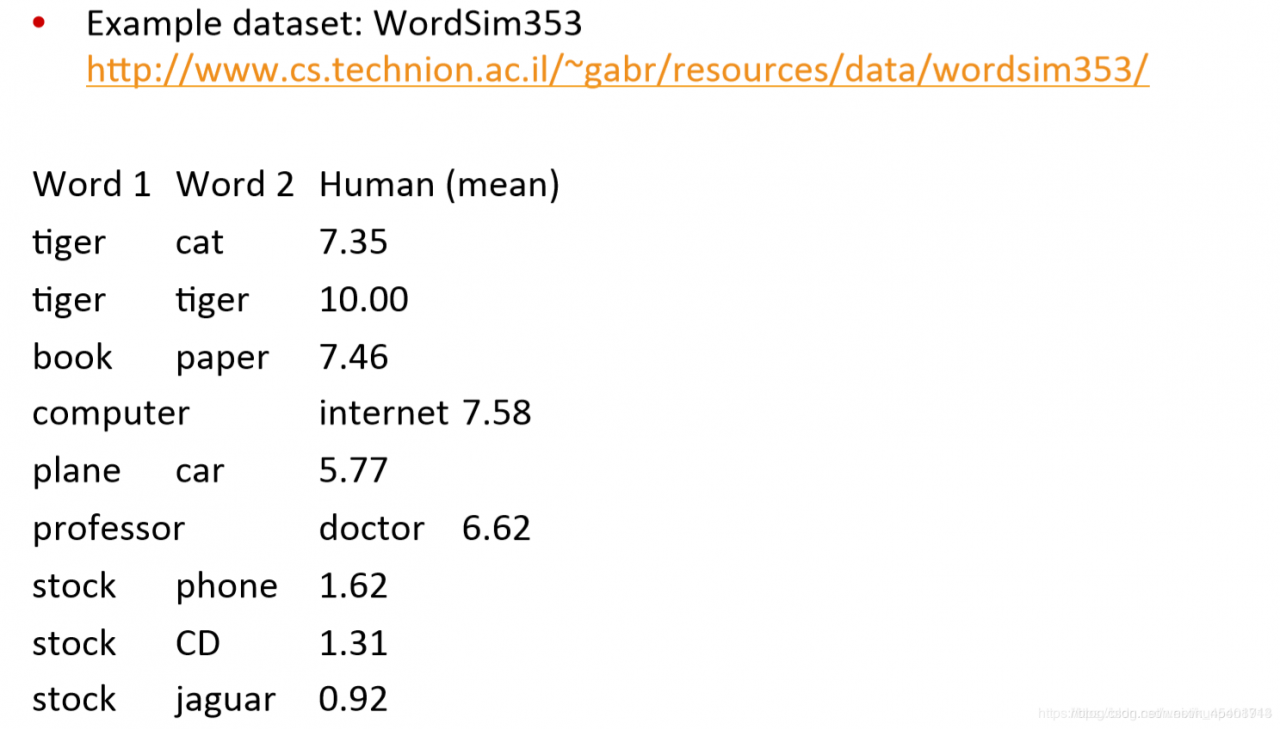
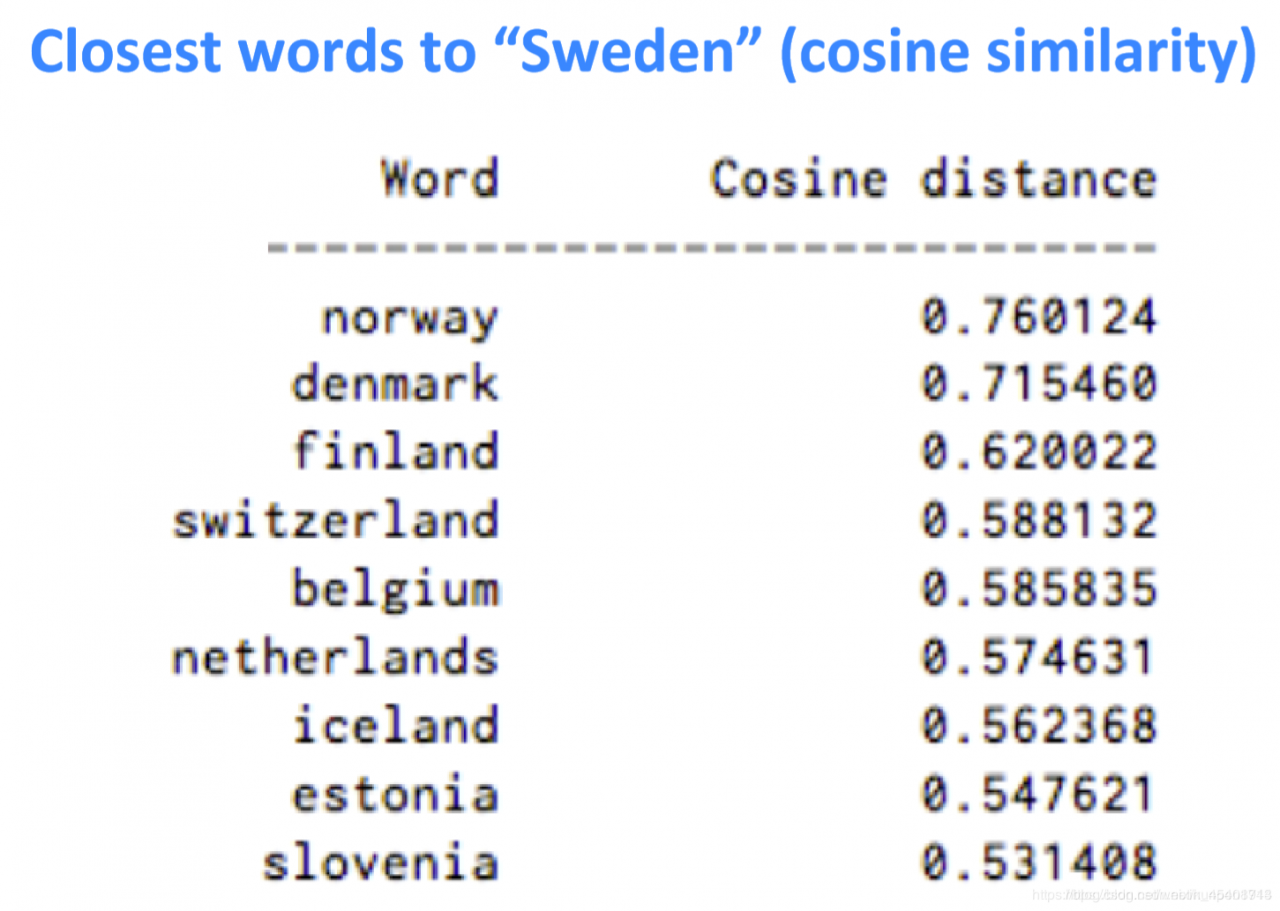
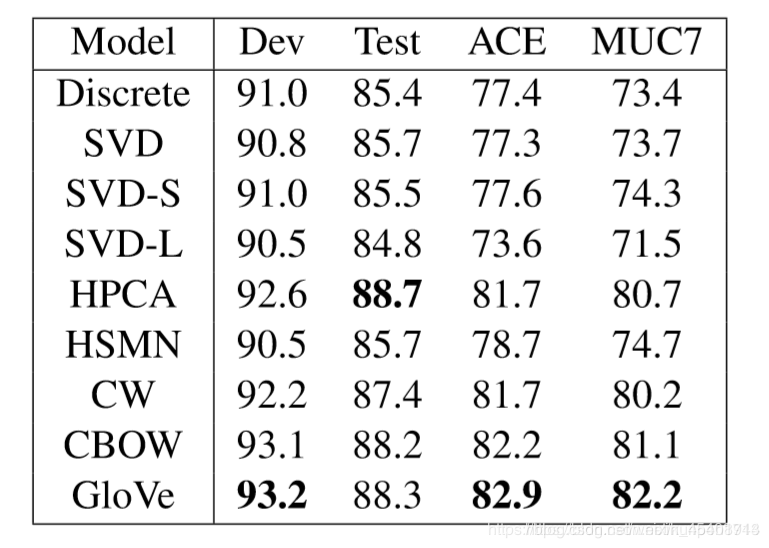
一个比较直接的例子是使用词向量进行命名实体识别(named entity recognition)(相关定义和方法可以参考斯坦福大学-自然语言处理入门 笔记 第九课 信息抽取)
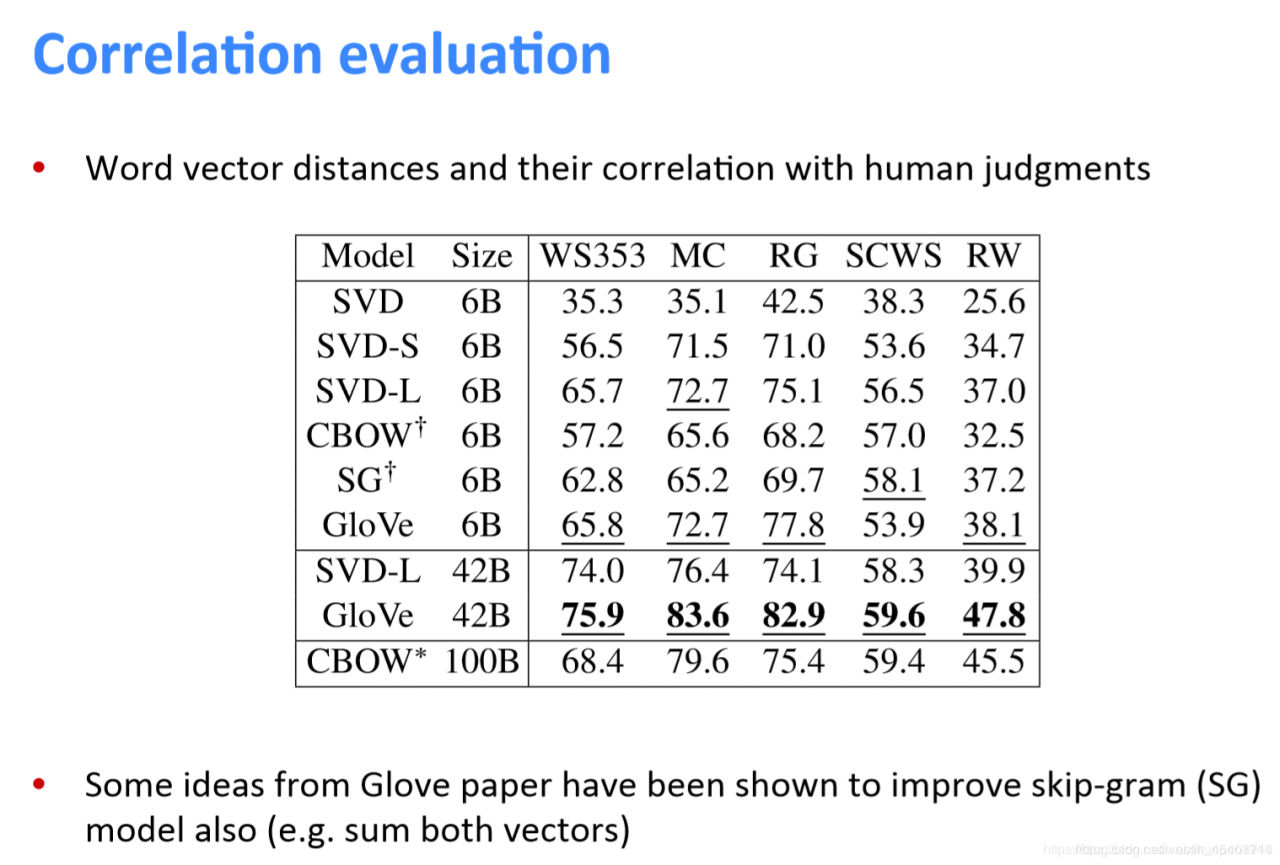
从下面的比较中可以看到,即使是在外部评估方法下,GloVe的表现也是很好的。
作者:白白白安安