python文件操作(二) 字符编码 函数入门
1.对文件读写操作
保存数据最简单的方式就是将其保存到文件中。通过输出写入文件,即便是关闭包含程序输出的终端窗口,这些输出也依然存在,还可以编写程序来将这些输出读取到内存中并进行处理。
json.dump
先把要写的内容存到内存里面去
在把内存里面的内容拿出来
转到文件里面去
(文件在磁盘上)
要将文本写入文件,你在调运open()时需要提供一个参数,告诉python你要写入打开的文件了。
‘w’ 创建一个新文件,把旧文件覆盖掉
f1 = open('test2','w',)
f1.write('this is a test from old ......')
f1 = open('test2','w',)
f1.write('this is a test from new ......')
#因为用的'w'所以第二次写入的时候发现把第一次写入的内容覆盖了
‘a’ 文件存在时 在文件后追加内容 文件不存在时 创建文件
f1 = open('test2','a',encoding='utf-8')
f1.write('康桥是今晚的沉默')
f1 = open('test2','a',encoding='utf-8')
f1.write('康桥是今晚的沉默')
#'a' 写的时候就是在文件后追加内容 所以之前写的内容也都还在
‘r+’ 对文件以一个读写的方式打开
f1 = open('test2','r+',encoding='utf-8')
print(f1.read()) #只有在先读的时候 写是忘文件里面追加的写
#如何不先读 直接写的话会直接覆盖原文件内容
f1.write('\n沉默是今晚的康桥')
f1.close()
#'r+'对文件可以读写 可以读取文件的内容 也可以写入
‘w+’ 先创建文件 写读
f1 = open('test5','w+',encoding='utf-8')
f1.write('沉默')
f1.seek(0) #调文件指针到开始的位置 因为写了内容之后文件指针在末尾
print(f1.read())
f1.close()
‘a+’ 追加写 读
#这个跟 ‘w+’ 不同的是 写内容是追加的写 不会覆盖以前写的内容
f1 = open('test5','a+',encoding='utf-8')
f1.write('\n沉默')
f1.seek(0)
print(f1.read())
f1.close()
除此以外,还存在追加读写和二进制读写
运用场景 1 网络传输 2 视频文件
二进制写’wb’
f1 = open(‘test4’,‘wb’)
二进制读’rb’
f1 = open(‘test4’,‘rb’)
(外加写进度条的例子)
.flush()强制实时刷新将缓存的内容写入文件
import sys,time
for i in range(50):
sys.stdout.write('#') #执行方法的输入 sys.stdout方法写到标准输出
sys.stdout.flush() #输入一个'#' 刷新打印一个
# time.sleep(0.1) #一次循环玩停上0.秒
这个例子在pycharm看的效果不太好
建议在linux虚拟机的虚拟环境上执行 就可以看出强制刷新缓存的内容写入文件的效果
2.修改文件内容
原理
修改一个文件
1)打开文件—>修改
2)打开文件 —> 修改的是一个生成的一个新文件 —> 用新文件去替换旧文件
先创建要修改的文件named.conf内容为
要求就是 把 listen-on 后面的any 替换为 192.168.42.110
把allow-query 后面的any 替换为 all
options {
listen-on port 53 { any; };
listen-on-v6 port 53 { ::1; };
directory "/var/named";
dump-file "/var/named/data/cache_dump.db";
statistics-file "/var/named/data/named_stats.txt";
memstatistics-file "/var/named/data/named_mem_stats.txt";
allow-query { any; };
代码为
f = open('named.conf',mode='r',encoding='utf-8') #修改一个文件 mode
f_new = open('.name.conf.swp','w',encoding='utf-8') #以写的方式打开一个新文件
for line in f:
if 'listen-on' in line:
#这个方法在字符串操作那里定义了 后面的内容替换掉前面的内容
line = line.replace('any','192.168.42.110') 、
if 'allow-query' in line:
line = line.replace('any','all')
print(line)
f_new.write(line)
f_new.flush()
f_new.close()
f.flush()
f.close()
#上面这些内容就是先以读的方式打开原文件 以写的方式打开一个临时文件
# 然后先修改临时文件的内容
# print(line,type(line))
# print(line)
f = open('named.conf',mode='w',encoding='utf-8') #修改一个文件 mode
f_new = open('.name.conf.swp','r',encoding='utf-8') #以写的方式打开一个新文件
for line_new in f_new:
print(line_new)
f.write(line_new)
f_new.flush()
f_new.close()
f.flush()
f.close()
#这些内容就是以度的方式打开临时文件 以写的方式打开原文件 把内容替换到原文件里面
(外加)传递参数
import sys
a = sys.argv[0] #传递参数 被a接收
b = sys.argv[1]
print(a,b)
这个要点击pycharm的这个
进到文件所在的目录之后
python test5_7.py 0 1 像这样就可以传递参数了
ASCII,美国标准信息交换代码是基于拉丁字母的一套电脑编码系统,主要用于显示现在英语和其他西欧语言,其最多只能用8位来表示(一个字节),即:2**8=256-1,所以呢,ASCII码最多只能表示255个字符。
有128-255个字符的扩展。
为了处理汉字,程序员设计了用于简体中文的GB2312和用于繁体的big5.
7445个汉字扩展存储——JB2312(1980年)
1995年汉字的扩展规模达到21886个符号,分别是汉字区和图形符号区,产生了GBK1.0。
2000年的GB18030取代了GBK1.0的正式国家标准。该标准收录了27484个汉字,同时还收录了藏文,蒙文,维吾尔文等重要的少数民族文字。
从ASCII、GB2312、GBK到GB18030,这些编码是向下兼容的。
显然ASCII码是无法将世界上的各种文字和符号全部表示,所以,就需要新出一种可以代表所有字符和符号的编码,即Unicode。
Unicode(统一码,万国码,单一码)是一种在计算机上使用的字符编码,Unicode是为了解决传统的字符编码方案的局限性而产生的,他为每种语言中的每个字符设定了统一并且唯一的二进制编码,规定所有的字符和符号最少由16位来表示(2个字节)。
UTF-8,是对Unicode编码的压缩和优化,他不在是最少使用2个字节了,而是将所有的字符和符号进行分类:ASCII码中的内容用1个字节保存,欧洲的字符用2个字节保存,东亚的字符用3个字节保存。
对于ASCLL表里面有的字符 仍然按照一个8位的字符存储 "________"
对于欧洲的字符 用的是16位的字符存储 "________________"
对于东南亚的字符 用的是24位的字符存储 "________________________"
2.1字符编码与解码
在Python 3里将文本和二进制数据做了更为清晰的区分。文本总是Unicode,有str类型表示,二进制数据则由byte类型表示。Python 3不会以任意隐式的方式混用str和bytes。我们不同拼接字符串与字节包,也无法在字节包里搜索字符串(反之亦然),也不能将字符串传入参数为字节包的函数(反之亦然)。
这就也要我们了解如何将字节码转换成字符串,如何将字符串转换为字节码。
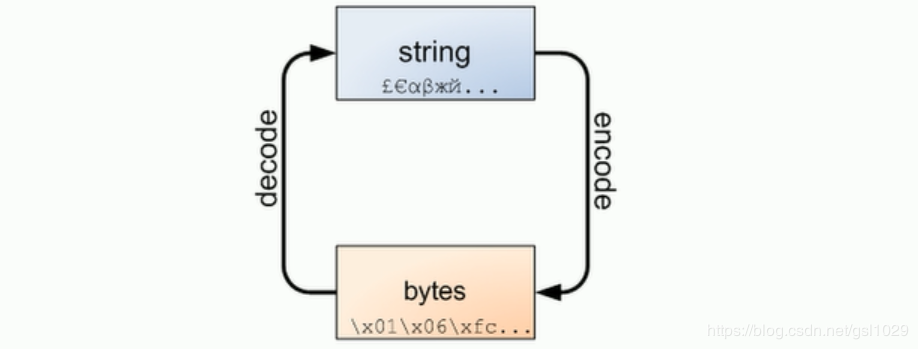
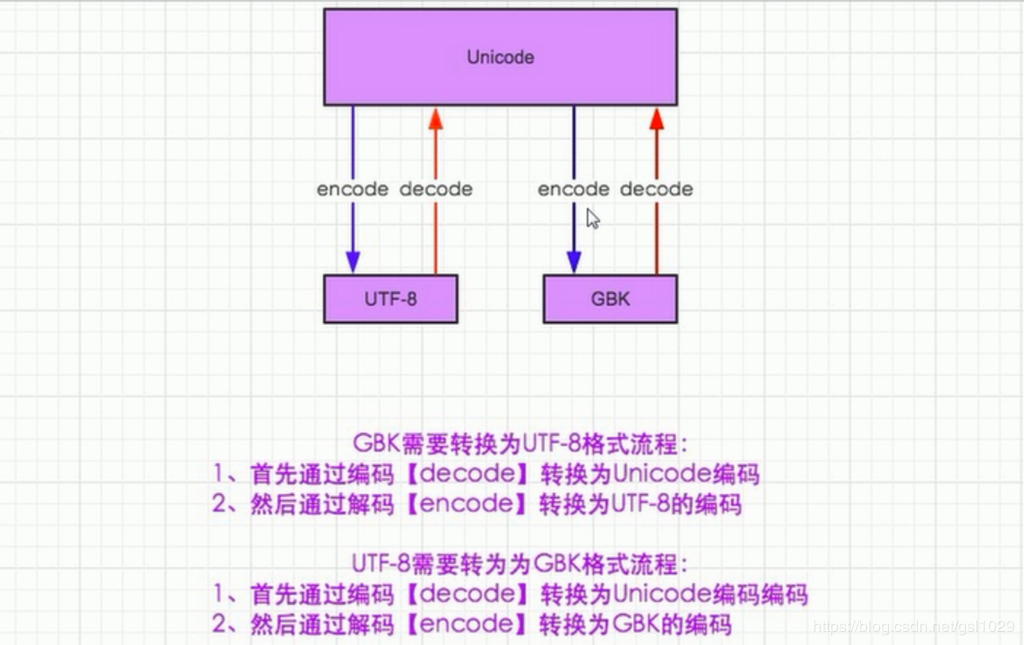
转换编码类型操作
在虚拟机的pyton2的环境运行
在xshell上面运行
#-*- coding:utf-8 -*- #先将编码类型改为utf-8 因为要识别中文
a = '您好'
a_to_unic = a.decode('utf-8') #转换为 unicode
a_to_gbk = a_to_unic.encode('gbk') #转换为 GBK
a_to_utf8 = a_to_gbk.decode('gbk').encode('utf-8') #转换为utf-8
print(a,type(a)) #结果为 您好
print(a_to_unic) #结果为 您好
print(a_to_gbk) #结果为 不认识 (其实也是您好 只不过xshell默认的编码格式为utf-8)
print(a_to_utf8) #结果为 您好
在python3上运行
import sys
print(sys.getdefaultencoding())
msg = "我们都是好孩子"
print(msg)
s_to_gbk = msg.encode('gbk')
print(s_to_gbk) #python3 转换类型之后 一步转换为bytes类型
s_to_utf = msg.encode('utf-8') #转换为 utf-8
print(s_to_utf)
s_to_gb2312 = msg.encode('gb2312') #转换为GB2312
print(s_to_gb2312)
结果为:
utf-8
我们都是好孩子
b'\xce\xd2\xc3\xc7\xb6\xbc\xca\xc7\xba\xc3\xba\xa2\xd7\xd3'
b'\xe6\x88\x91\xe4\xbb\xac\xe9\x83\xbd\xe6\x98\xaf\xe5\xa5\xbd\xe5\xad\xa9\xe5\xad\x90'
b'\xce\xd2\xc3\xc7\xb6\xbc\xca\xc7\xba\xc3\xba\xa2\xd7\xd3'
这个时候就可以看出每个字符编码站的字符存储就不一样了
这个时候在都.decode()到对应的字符就可以打印内容了
# python3底层默认的编码类型为unicode 所以转换为gbk可以直接用encode转换
# python3 encode转换类型之后 一步转换为bytes类型
# python2 了解即可 底层编码是bytes
import sys
print(sys.getdefaultencoding())
msg = "我们都是好孩子"
print(msg)
s_to_gbk = msg.encode('gbk').decode('gbk') #转换为 gdk
print(s_to_gbk)
s_to_utf = msg.encode('utf-8').decode('utf-8') #转换为 utf-8
print(s_to_utf)
s_to_gb2312 = msg.encode('gb2312').decode('gb2312') #转换为 GB2312
print(s_to_gb2312)
结果为:
utf-8
我们都是好孩子
我们都是好孩子
我们都是好孩子
我们都是好孩子
三.函数入门
函数是组织好的,可重复使用的,用来实现单一,或相关联功能的代码段。
函数能提高应用的模块性,和代码的重复利用率。你已经知道Python提供了许多内建函数,比如print()。但你也可以自己创建函数,这被叫做用户自定义函数。
函数:
为什么有函数:可扩展,可重用,保持数据一致
函数和过程:在python3中不严格区分
过程就是没有返回值函数
函数体:def 函数名:
注释
函数体
return
返回值:python3 return返回值
没有定义:系统默认返回None
有定义:单个值(字符串,数字,布尔值,列表,字典,元组…)
定义什么类型 返回对应的字符类型
多个值 有多个返回值 会以元组的方式返回
函数 返回函数的执行结果和返回值
函数名
传参:
实参: 占用内存空间
形参: 不占用内存空间
test3(1,2,3) 位置参数要和形式参数对应_
test3(1,y=2,z=3) 关键字参数不能放在位置参数之前
3.1时间函数例子:
时间函数
import time
def time1():
time_format = '%Y-%m-%d.%X' #定义输出时间格式
time_current = time.strftime(time_format) # 调用系统时间
print(time_current)
time1()
结果就是按照我们定义的格式输出时间
3.2返回值的例子
import time
def time1():
time_format = '%Y-%m-%d.%X' #定义输出时间格式
time_current = time.strftime(time_format) # 调用系统时间
print(time_current,end=' is log ')
def test1():
time1()
print('this is a test1 ',end=' ')
return 0
#test1()
print(test1())
结果为 (打印会把函数输出内容和返回值一起打印)
2020-04-18.21:05:05 is log this is a test1 0
返回值定义值(定义的值为什么类型 就返回的是什么类型)
import time
def time1():
time_format = '%Y-%m-%d.%X' #定义输出时间格式
time_current = time.strftime(time_format) # 调用系统时间
print(time_current,end=' is log ')
def test1():
time1()
print('this is a test1 ',end=' ')
return 0
def test2():
time1()
print('this is a test2',end=' ')
return 'leilei'
# test1()
print(test2())
# time1()
结果为
2020-04-18.21:07:02 is log this is a test2 leilei
返回值定义多个值 (返回的时候会把每个值都当成元组的一个元素)
def test3():
print('this is a test form test3',end=' ')
return 'leilei','shtoou','磊磊'
print(test3())
结果为
this is a test form test3 ('leilei', 'shtoou', '磊磊')
def test3():
print('this is a test form test3',end=' ')
return 'leilei',1,'磊磊',['yunwei','java'],{'linux':'leilei','java':'shitou'}
print(test3())
结果为
this is a test form test3 ('leilei', 1, '磊磊', ['yunwei', 'java'], {'linux': 'leilei', 'java': 'shitou'})
返回值 定义函数 (返回值会返回函数的执行结果和返回值)
def test2():
print('this is a test2',end=' ')
return 'leilei'
# test1()
# print(test2())
# time1()
def test3():
print('this is a test form test3',end=' ')
return test2()
print(test3())
结果为
this is a test form test3 this is a test2 leilei
3.3传参的例子
定义实参 占用内存空间
1)最简单的一个定义位置实参的例子
位置参数要和形式参数对应
def test3(x,y):
print(x+y)
test3(1,2)
结果为 3
定义关键字实参的例子
关键字参数不能放在位置参数之前
也就是test3(1,y=2,3)这样就不行 关键字就在位置参数前面了
def test3(x,y,z):
print(x+y+z)
test3(1,y=2,z=3)
结果为
6
定义形参 不占用内存空间
def test3(x,y,z):
''' #这里可以写函数的注释 这样一个函数就完整了
this is a test
:param x: 1
:param y: 2
:param z: 3
:return: x+y+z
'''
return x+y+z
a = test3(1,2,3)
print(a)
结果为 6
作者:高haha