简单的性能自动化测试架构设计和实现(pylot)-python
目的:
和普通性能自动化测试工具相似,创建给定数量的请求代理,对链接列表中的链接不断发送请求,并收集请求时间和其他响应信息,终返回结果数据。
事实上,由于开源测试项目pylot的思路和这个项目有些相似,大部分示例代码使用pylot源码,一些会有稍微改动。
设计思路:
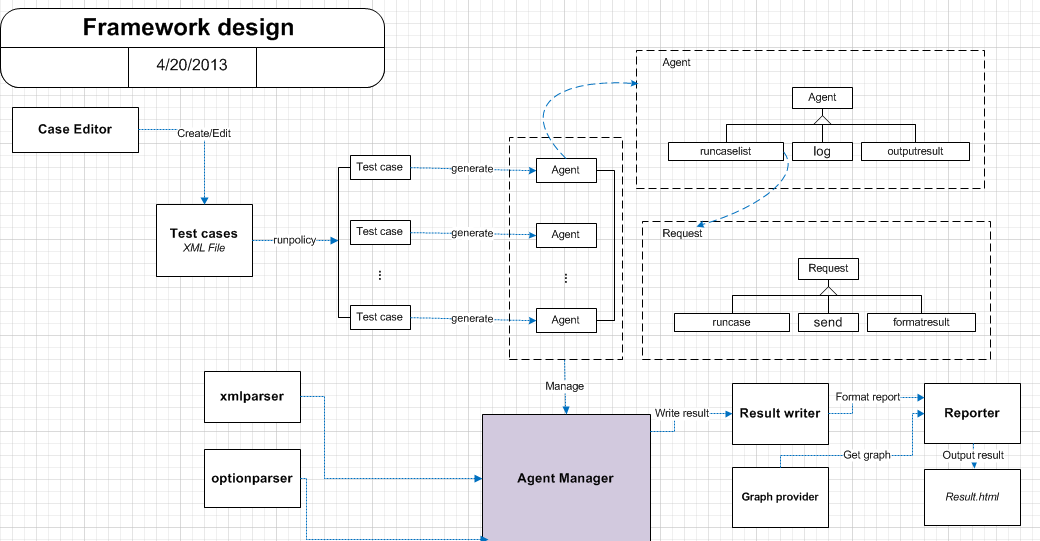
如设计图所示,总体上分为5个主要部分:
1、Test.xml处理部分:
通过用户的制作的testcase.xml文件,获取总体的属性值作为参数,并读取所有test case所包含的信息,获取所有测试连接列表和其他配置数据,testcase.xml的格式如下,这个testcase.xml可以专门写一个xml写作的工具,供QA人员以界面方式进行编写,提高效率并减小错误率:
<testcases> <project> <name>Test</name> <description>Only Test</description> <executor>zhangyi</executor> <!-- 如果需要结果进入数据库,配置下面数据库链接参数 -> <DB <host></host> <port></port> <user></user> <pwd></pwd> <db></db> <debug>true</debug> </DB> <type>Example</type> </project> <property> <old_version></old_verstion> <old_version></old_verstion> <wel_url>r'http://www.baidu.cn/'</wel_url> </property> <!-- run before all testcase --> <beforesetup> </beforesetup> <!-- run after all testcase --> <afterteardown> </afterteardown> <!-- run before each testcase. if fail, not continue run testcase--> <setup> </setup> <!-- run after each testcase. ignore testcase fail. --> <teardown> </teardown> <!-- SAMPLE TEST CASE --> <case repeat=3> <url>http://www.example.com</url> </case> <case repeat=3> <url>http://search.yahooapis.com/WebSearchService/V1/webSearch</url> <method>POST</method> <body><![CDATA[appid=YahooDemo&query=pylot]]></body> <add_header>Content-type: application/x-www-form-urlencoded</add_header> </case> <case repeat=2> <url>http://search.yahooapis.com/WebSearchService/V1/webSearch</url> <method>POST</method> <body><![CDATA[appid=YahooDemo&query=pylot]]></body> <add_header>Content-type: application/x-www-form-urlencoded</add_header> </case repeat=3> <case> <url>http://search.yahooapis.com/WebSearchService/V1/webSearch</url> <method>POST</method> <body><![CDATA[appid=YahooDemo&query=pylot]]></body> <add_header>Content-type: application/x-www-form-urlencoded</add_header> </case> <case> <url>http://www.example.com</url> </case> <case repeat=10> <url>http://www.example.com</url> </case> <!-- SAMPLE TEST CASE --> <!-- <case> <url>http://search.yahooapis.com/WebSearchService/V1/webSearch</url> <method>POST</method> <body><![CDATA[appid=YahooDemo&query=pylot]]></body> <add_header>Content-type: application/x-www-form-urlencoded</add_header> </case> --> </testcases>
根据用户的策略,会对testcase.xml中的case项进行分割和组合,终得到每个agent对应的testcase.xml,agent会按照这个testcase.xml进行测试,通常来说,策略包含以下两种:a. 每个agent执行所有case;b. 将所有case平均分给agent执行。
重要代码:
def load_xml_cases_dom(dom): cases = [] param_map = {} for child in dom.getiterator(): if child.tag != dom.getroot().tag and child.tag == 'param': name = child.attrib.get('name') value = child.attrib.get('value') param_map[name] = value if child.tag != dom.getroot().tag and child.tag == 'case': req = Request() repeat = child.attrib.get('repeat') if repeat: req.repeat = int(repeat) else: req.repeat = 1 for element in child: if element.tag.lower() == 'url': req.url = element.text if element.tag.lower() == 'method': req.method = element.text if element.tag.lower() == 'body': file_payload = element.attrib.get('file') if file_payload: req.body = open(file_payload, 'rb').read() else: req.body = element.text if element.tag.lower() == 'verify': req.verify = element.text if element.tag.lower() == 'verify_negative': req.verify_negative = element.text if element.tag.lower() == 'timer_group': req.timer_group = element.text if element.tag.lower() == 'add_header': splat = element.text.split(':') x = splat[0].strip() del splat[0] req.add_header(x, ''.join(splat).strip()) req = resolve_parameters(req, param_map) # substitute vars cases.append(req) return case
2、Request请求代理部分:
请求代理会根据分配给自己的testcase.xml进行初始化,获取所有配置参数和case列表,当接收到agent manager发给的执行消息后,会开启一个线程对case列表中的每一个case进行处理;初始化agent时,agent manager会传进来全局的几个队列,包括result queue,msg queue,error queue;这些queue中的信息终会由agent manager统一处理;
重要代码:
def run(self): agent_start_time = time.strftime('%H:%M:%S', time.localtime()) total_latency = 0 total_connect_latency = 0 total_bytes = 0 while self.running: self.cookie_jar = cookielib.CookieJar() for req in self.msg_queue: for repeat in range(req.repeat): if self.running: request=Request(req) # send the request message resp, content, req_start_time, req_end_time, connect_end_time = request.send(req)
# get times for logging and error display tmp_time = time.localtime() cur_date = time.strftime('%d %b %Y', tmp_time) cur_time = time.strftime('%H:%M:%S', tmp_time)
# check verifications and status code for errors is_error = False if resp.code >= 400 or resp.code == 0: is_error = True if not req.verify == '': if not re.search(req.verify, content, re.DOTALL): is_error = True if not req.verify_negative == '': if re.search(req.verify_negative, content, re.DOTALL): is_error = True if is_error: self.error_count += 1 error_string = 'Agent %s: %s - %d %s, url: %s' % (self.id + 1, cur_time, resp.code, resp.msg, req.url) self.error_queue.append(error_string) log_tuple = (self.id + 1, cur_date, cur_time, req_end_time, req.url.replace(',', ''), resp.code, resp.msg.replace(',', '')) self.log_error('%s,%s,%s,%s,%s,%s,%s' % log_tuple) # write as csv resp_bytes = len(content) latency = (req_end_time - req_start_time) connect_latency = (connect_end_time - req_start_time) self.count += 1 total_bytes += resp_bytes total_latency += latency total_connect_latency += connect_latency # update shared stats dictionary self.runtime_stats[self.id] = StatCollection(resp.code, resp.msg, latency, self.count, self.error_count, total_latency, total_connect_latency, total_bytes) self.runtime_stats[self.id].agent_start_time = agent_start_time # put response stats/info on queue for reading by the consumer (ResultWriter) thread q_tuple = (self.id + 1, cur_date, cur_time, req_end_time, req.url.replace(',', ''), resp.code, resp.msg.replace(',', ''), resp_bytes, latency, connect_latency, req.timer_group) self.results_queue.put(q_tuple) expire_time = (self.interval - latency) if expire_time > 0: time.sleep(expire_time) # sleep remainder of interval so we keep even pacing else: # don't go through entire range if stop has been called break
3、Request请求部分:
对每一个case初始化为一个request类实例,包含这case的测试数据,测试方法和测试结果,agent会实例化对立中的每个case,并在主线程中执行测试方法,获取相应的测试数据;
重要代码,这部分代码本来是pylot中的源码,个人更倾向于将它放在request中,需要少许更改:
def send(self, req): # req is our own Request object if HTTP_DEBUG: opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(self.cookie_jar), urllib2.HTTPHandler(debuglevel=1)) elif COOKIES_ENABLED: opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(self.cookie_jar)) else: opener = urllib2.build_opener() if req.method.upper() == 'POST': request = urllib2.Request(req.url, req.body, req.headers) else: request = urllib2.Request(req.url, None, req.headers) # urllib2 assumes a GET if no data is supplied. PUT and DELETE are not supported # timed message send+receive (TTLB) req_start_time = self.default_timer() try: resp = opener.open(request) # this sends the HTTP request and returns as soon as it is done connecting and sending connect_end_time = self.default_timer() content = resp.read() req_end_time = self.default_timer() except httplib.HTTPException, e: # this can happen on an incomplete read, just catch all HTTPException connect_end_time = self.default_timer() resp = ErrorResponse() resp.code = 0 resp.msg = str(e) resp.headers = {} content = '' except urllib2.HTTPError, e: # http responses with status >= 400 connect_end_time = self.default_timer() resp = ErrorResponse() resp.code = e.code resp.msg = httplib.responses[e.code] # constant dict of http error codes/reasons resp.headers = dict(e.info()) content = '' except urllib2.URLError, e: # this also catches socket errors connect_end_time = self.default_timer() resp = ErrorResponse() resp.code = 0 resp.msg = str(e.reason) resp.headers = {} # headers are not available in the exception content = '' req_end_time = self.default_timer() if self.trace_logging: # log request/response messages self.log_http_msgs(req, request, resp, content)
return (resp, content, req_start_time, req_end_time, connect_end_time)
4、代理管理部分:
代理管理的主要任务是创建几个重要数据的队列,实例化每个agent并为其创建新的线程。代理管理会管理这个线程池,并在这些中重要的队列中获取到测试的结果;
重要代码:
def run(self): self.running = True self.agents_started = False try: os.makedirs(self.output_dir, 0755) except OSError: self.output_dir = self.output_dir + time.strftime('/results_%Y.%m.%d_%H.%M.%S', time.localtime()) try: os.makedirs(self.output_dir, 0755) except OSError: sys.stderr.write('ERROR: Can not create output directory ') sys.exit(1) # start thread for reading and writing queued results self.results_writer = ResultWriter(self.results_queue, self.output_dir) self.results_writer.setDaemon(True) self.results_writer.start() for i in range(self.num_agents): spacing = float(self.rampup) / float(self.num_agents) if i > 0: # first agent starts right away time.sleep(spacing) if self.running: # in case stop() was called before all agents are started agent = LoadAgent(i, self.interval, self.log_msgs, self.output_dir, self.runtime_stats, self.error_queue, self.msg_queue, self.results_queue) agent.start() self.agent_refs.append(agent) agent_started_line = 'Started agent ' + str(i + 1) if sys.platform.startswith('win'): sys.stdout.write(chr(0x08) * len(agent_started_line)) # move cursor back so we update the same line again sys.stdout.write(agent_started_line) else: esc = chr(27) # escape key sys.stdout.write(esc + '[G' ) sys.stdout.write(esc + '[A' ) sys.stdout.write(agent_started_line + ' ') if sys.platform.startswith('win'): sys.stdout.write(' ') print ' All agents running... ' self.agents_started = True
def stop(self): self.running = False for agent in self.agent_refs: agent.stop() if WAITFOR_AGENT_FINISH: keep_running = True while keep_running: keep_running = False for agent in self.agent_refs: if agent.isAlive(): keep_running = True time.sleep(0.1) self.results_writer.stop()
5、结果生成部分:
代理中获取的数据终写到一个csv文件中,在代理部分的执行函数完成后,读取这个文件的内容,生成相关的结果数据和图片(图片在python中倾向于使用matlibplot包)。终将其写成html的结果报告形式:
重要代码:
def generate_results(dir, test_name): print ' Generating Results...' try: merged_log = open(dir + '/agent_stats.csv', 'rb').readlines() # this log contains commingled results from all agents except IOError: sys.stderr.write('ERROR: Can not find your results log file ') merged_error_log = merge_error_files(dir) if len(merged_log) == 0: fh = open(dir + '/results.html', 'w') fh.write(r'<html><body><p>None of the agents finished successfully. There is no data to report.</p></body></html> ') fh.close() sys.stdout.write('ERROR: None of the agents finished successfully. There is no data to report. ') return timings = list_timings(merged_log) best_times, worst_times = best_and_worst_requests(merged_log) timer_group_stats = get_timer_groups(merged_log) timing_secs = [int(x[0]) for x in timings] # grab just the secs (rounded-down) throughputs = calc_throughputs(timing_secs) # dict of secs and throughputs throughput_stats = corestats.Stats(throughputs.values()) resp_data_set = [x[1] for x in timings] # grab just the timings response_stats = corestats.Stats(resp_data_set) # calc the stats and load up a dictionary with the results stats_dict = get_stats(response_stats, throughput_stats) # get the pickled stats dictionaries we saved runtime_stats_dict, workload_dict = load_dat_detail(dir) # get the summary stats and load up a dictionary with the results summary_dict = {} summary_dict['cur_time'] = time.strftime('%m/%d/%Y %H:%M:%S', time.localtime()) summary_dict['duration'] = int(timings[-1][0] - timings[0][0]) + 1 # add 1 to round up summary_dict['num_agents'] = workload_dict['num_agents'] summary_dict['req_count'] = len(timing_secs) summary_dict['err_count'] = len(merged_error_log) summary_dict['bytes_received'] = calc_bytes(merged_log) # write html report fh = open(dir + '/results.html', 'w') reportwriter.write_head_html(fh) reportwriter.write_starting_content(fh, test_name) reportwriter.write_summary_results(fh, summary_dict, workload_dict) reportwriter.write_stats_tables(fh, stats_dict) reportwriter.write_images(fh) reportwriter.write_timer_group_stats(fh, timer_group_stats) reportwriter.write_agent_detail_table(fh, runtime_stats_dict) reportwriter.write_best_worst_requests(fh, best_times, worst_times) reportwriter.write_closing_html(fh) fh.close() # response time graph def resp_graph(nested_resp_list, dir='./'): fig = figure(figsize=(8, 3)) # image dimensions ax = fig.add_subplot(111) ax.set_xlabel('Elapsed Time In Test (secs)', size='x-small') ax.set_ylabel('Response Time (secs)' , size='x-small') ax.grid(True, color='#666666') xticks(size='x-small') yticks(size='x-small') axis(xmin=0) x_seq = [item[0] for item in nested_resp_list] y_seq = [item[1] for item in nested_resp_list] ax.plot(x_seq, y_seq, color='blue', linestyle='-', linewidth=1.0, marker='o', markeredgecolor='blue', markerfacecolor='yellow', markersize=2.0) savefig(dir + 'response_time_graph.png') # throughput graph def tp_graph(throughputs_dict, dir='./'): fig = figure(figsize=(8, 3)) # image dimensions ax = fig.add_subplot(111) ax.set_xlabel('Elapsed Time In Test (secs)', size='x-small') ax.set_ylabel('Requests Per Second (count)' , size='x-small') ax.grid(True, color='#666666') xticks(size='x-small') yticks(size='x-small') axis(xmin=0) keys = throughputs_dict.keys() keys.sort() values = [] for key in keys: values.append(throughputs_dict[key]) x_seq = keys y_seq = values ax.plot(x_seq, y_seq, color='red', linestyle='-', linewidth=1.0, marker='o', markeredgecolor='red', markerfacecolor='yellow', markersize=2.0) savefig(dir + 'throughput_graph.png') try: # graphing only works on systems with Matplotlib installed print 'Generating Graphs...' import graph graph.resp_graph(timings, dir=dir+'/') graph.tp_graph(throughputs, dir=dir+'/') except: sys.stderr.write('ERROR: Unable to generate graphs with Matplotlib ') print ' Done generating results. You can view your test at:' print '%s/results.html ' % dir
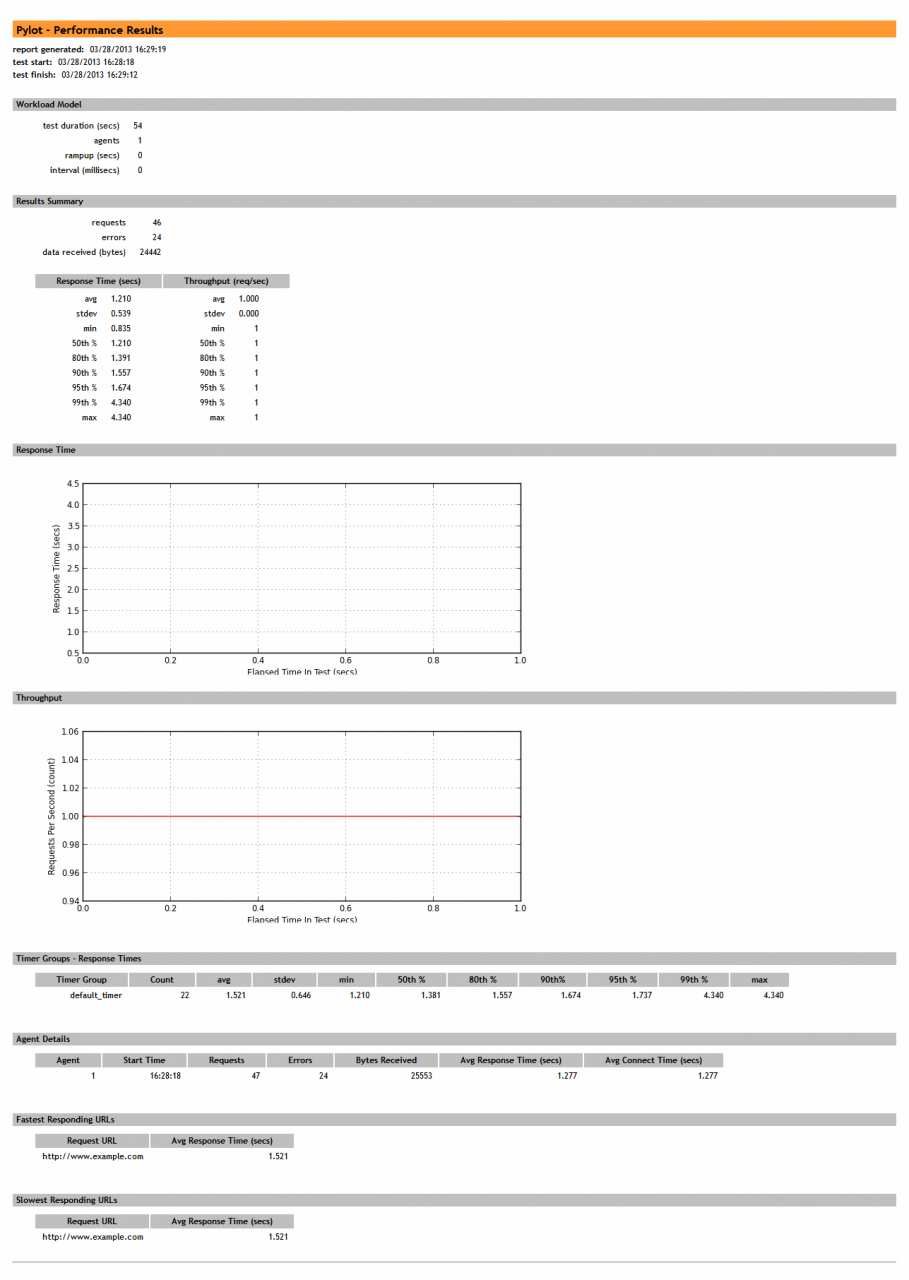
对于项目的运行,既可以采取控制台方式,也可以提供给QA人员GUI的方式。Pylot中提供了很好的GUI支持,可以作为示例使用。实际上不建议使用GUI的方式,另外pylot中没有用户指定策略的支持,这个需要自己专门进行开发;另外是pylot中的类封装结构还不是很好,对以后的扩展来说还需要一定的更改。但是作为一般使用已经足够了,下面是pylot的终报告结果(只做实例使用)。