Python实现自动化域名批量解析分享
脚本架构:
domain_test.py:批量解析运行主程序
DomainResult.txt:域名解析结果文件
domains.txt:解析的域名文件
实现代码如下:
# coding:utf-8
import socket
import subprocess
import re
def get_host_from_file(file_path):
with open(file_path, 'r') as fr:
domains = fr.readlines()
result = []
for url in domains:
url = url.strip()
try:
ips = socket.gethostbyname_ex(url)[-1]
result.append(url + '\t' + ';'.join(ips) + '\t' + 'ping' + '\n')
except Exception as e:
print(url, e)
with open('./domain2ip.txt', 'w') as fw:
fw.writelines(result)
def get_host_from_url(url):
try:
ips = socket.gethostbyname_ex(url)[-1]
return url + '\t' + ';'.join(ips) + '\t' + 'ping' + '\n' except Exception as e:
print(url, e)
return url + '\t' + 'none' + '\n'
def dig_test(file_name, dns_name):
dig_command = 'dig ' ip_result = []
if dns_name:
dig_command += dns_name + ' ' with open(file_name) as fr:
domains = fr.readlines()
for ui, full_url in enumerate(domains):
ips = []
full_url = full_url.strip()
try:
result = subprocess.Popen(dig_command + full_url, shell=True, stdout=subprocess.PIPE, stderr=subprocess.STDOUT)
except Exception as e:
print(full_url, e)
else:
results = str(result.stdout.read()).split('\\n')
for temp in results:
if full_url in temp and 'IN' in temp:
ip = re.match(r'.*\\t([0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}).*', temp)
if ip and ip.group(1) not in ips:
ips.append(ip.group(1))
if 'AUTHORITY SECTION' in temp:
break if ips:
temp = full_url + '\t' + ';'.join(ips) + '\t' + 'dig' + '\n' else:
temp = get_host_from_url(full_url)
print(ui, temp)
ip_result.append(temp)
#解析完成后,生成结果文件
with open('domains.txt', 'w') as fw:
fw.writelines(ip_result)
if __name__ == '__main__':
# 先使用dig,失败时使用ping获取域名ip,可指定dns,如@114.114.114.114
dig_test(file_name='DomainResults.txt', dns_name='')
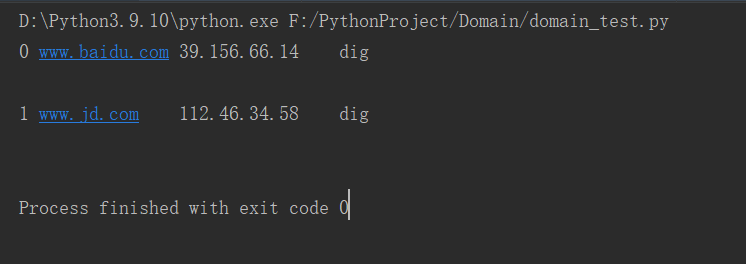
演示结果:
到此这篇关于Python实现自动化域名批量解析的文章就介绍到这了,更多相关Python自动化域名解析内容请搜索软件开发网以前的文章或继续浏览下面的相关文章希望大家以后多多支持软件开发网!