deeplearning_class4:机器翻译、注意力机制与seq2seq模型
1 机器翻译
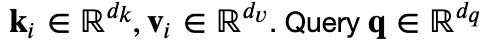
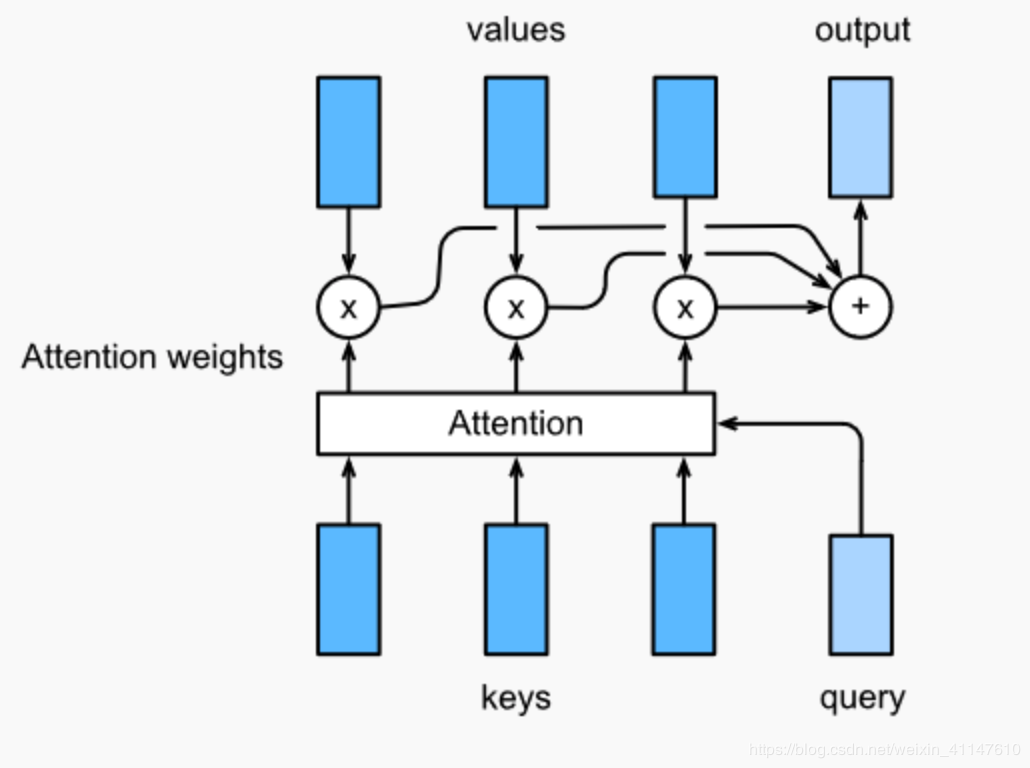
attention layer得到输出与value的维度一致o∈Rdvo\in R^{d_v}o∈Rdv,对一个query来说,attention layer会与每一个key计算注意力分数并进行权重的归一化,输出的向量o则是value的家全球和,而每个key计算的权重与value一一对应。
ai=α(q,ki)a_i=\alpha(q,k_i)ai=α(q,ki)
使用softmax函数,获得注意力权重:
b1,......,bn=softmax(a1,......,an) b_1,......,b_n = softmax(a_1,......,a_n) b1,......,bn=softmax(a1,......,an)
最终的输出就是value的加权求和:
o=∑i=1nbivi o = \sum^{n}_{i = 1}b_iv_i o=i=1∑nbivi
 2.2 softmax屏蔽
2.2 softmax屏蔽
这一部分由于资源包不全,笔者没有进行过多学习,借助腾讯AI平台
2 注意力机制注意力机制模仿了生物观察行为的内部过程,即一种将内部经验和外部感觉对齐从而增加部分区域的观察精细度的机制。注意力机制可以快速提取稀疏数据的重要特征,因而被广泛用于自然语言处理任务,特别是机器翻译。而自注意力机制是注意力机制的改进,其减少了对外部信息的依赖,更擅长捕捉数据或特征的内部相关性。本文通过文本情感分析的案例,解释了自注意力机制如何应用于稀疏文本的单词对表征加权,并有效提高模型效率。
2.1 注意力机制框架Attention是一种通用的带权池化方法,输入有两部分构成:
询问(query) 键值对(key-value)attention layer得到输出与value的维度一致o∈Rdvo\in R^{d_v}o∈Rdv,对一个query来说,attention layer会与每一个key计算注意力分数并进行权重的归一化,输出的向量o则是value的家全球和,而每个key计算的权重与value一一对应。
ai=α(q,ki)a_i=\alpha(q,k_i)ai=α(q,ki)
使用softmax函数,获得注意力权重:
b1,......,bn=softmax(a1,......,an) b_1,......,b_n = softmax(a_1,......,a_n) b1,......,bn=softmax(a1,......,an)
最终的输出就是value的加权求和:
o=∑i=1nbivi o = \sum^{n}_{i = 1}b_iv_i o=i=1∑nbivi
2.2 softmax屏蔽
def SequenceMask(X, X_len,value=-1e6):
maxlen = X.size(1)
#print(X.size(),torch.arange((maxlen),dtype=torch.float)[None, :],'\n',X_len[:, None] )
mask = torch.arange((maxlen),dtype=torch.float)[None, :] >= X_len[:, None]
#print(mask)
X[mask]=value
return X
def masked_softmax(X, valid_length):
# X: 3-D tensor, valid_length: 1-D or 2-D tensor
softmax = nn.Softmax(dim=-1)
if valid_length is None:
return softmax(X)
else:
shape = X.shape
if valid_length.dim() == 1:
try:
valid_length = torch.FloatTensor(valid_length.numpy().repeat(shape[1], axis=0))#[2,2,3,3]
except:
valid_length = torch.FloatTensor(valid_length.cpu().numpy().repeat(shape[1], axis=0))#[2,2,3,3]
else:
valid_length = valid_length.reshape((-1,))
# fill masked elements with a large negative, whose exp is 0
X = SequenceMask(X.reshape((-1, shape[-1])), valid_length)
return softmax(X).reshape(shape)
masked_softmax(torch.rand((2,2,4),dtype=torch.float), torch.FloatTensor([2,3]))
#tensor([[[0.5423, 0.4577, 0.0000, 0.0000],
# [0.5290, 0.4710, 0.0000, 0.0000]],
#
# [[0.2969, 0.2966, 0.4065, 0.0000],
# [0.3607, 0.2203, 0.4190, 0.0000]]])
2.3 点积注意力
The dot product 假设query和keys有相同的维度, 即 ∀