深度学习(四)————机器翻译及相关技术、注意力机制与Seq2seq模型、Transformer
目录
机器翻译及相关技术
注意力机制与seq2seq模型
Transformer
机器翻译及相关技术机器翻译(MT):将一段文本从一种语言自动翻译为另一种语言,用神经网络解决这个问题通常称为神经机器翻译(NMT)。 主要特征:输出是单词序列而不是单个单词。 输出序列的长度可能与源序列的长度不同。
机器翻译流程:数据预处理,主要模型:encode-decode,seq2seq
注意力机制与seq2seq模型注意力机制:https://blog.csdn.net/mpk_no1/article/details/72862348?utm_source=distribute.pc_relevant.none-task
seq2seq https://www.jianshu.com/p/b2b95f945a98
Transformer在之前的章节中,我们已经介绍了主流的神经网络架构如卷积神经网络(CNNs)和循环神经网络(RNNs)。让我们进行一些回顾:
CNNs 易于并行化,却不适合捕捉变长序列内的依赖关系。 RNNs 适合捕捉长距离变长序列的依赖,但是却难以实现并行化处理序列。为了整合CNN和RNN的优势,[Vaswani et al., 2017] 创新性地使用注意力机制设计了Transformer模型。该模型利用attention机制实现了并行化捕捉序列依赖,并且同时处理序列的每个位置的tokens,上述优势使得Transformer模型在性能优异的同时大大减少了训练时间。
Transformer模型的架构与seq2seq模型相似,Transformer同样基于编码器-解码器架构,其区别主要在于以下三点:
Transformer blocks:将seq2seq模型重的循环网络替换为了Transformer Blocks,该模块包含一个多头注意力层(Multi-head Attention Layers)以及两个position-wise feed-forward networks(FFN)。对于解码器来说,另一个多头注意力层被用于接受编码器的隐藏状态。 Add and norm:多头注意力层和前馈网络的输出被送到两个“add and norm”层进行处理,该层包含残差结构以及层归一化。 Position encoding:由于自注意力层并没有区分元素的顺序,所以一个位置编码层被用于向序列元素里添加位置信息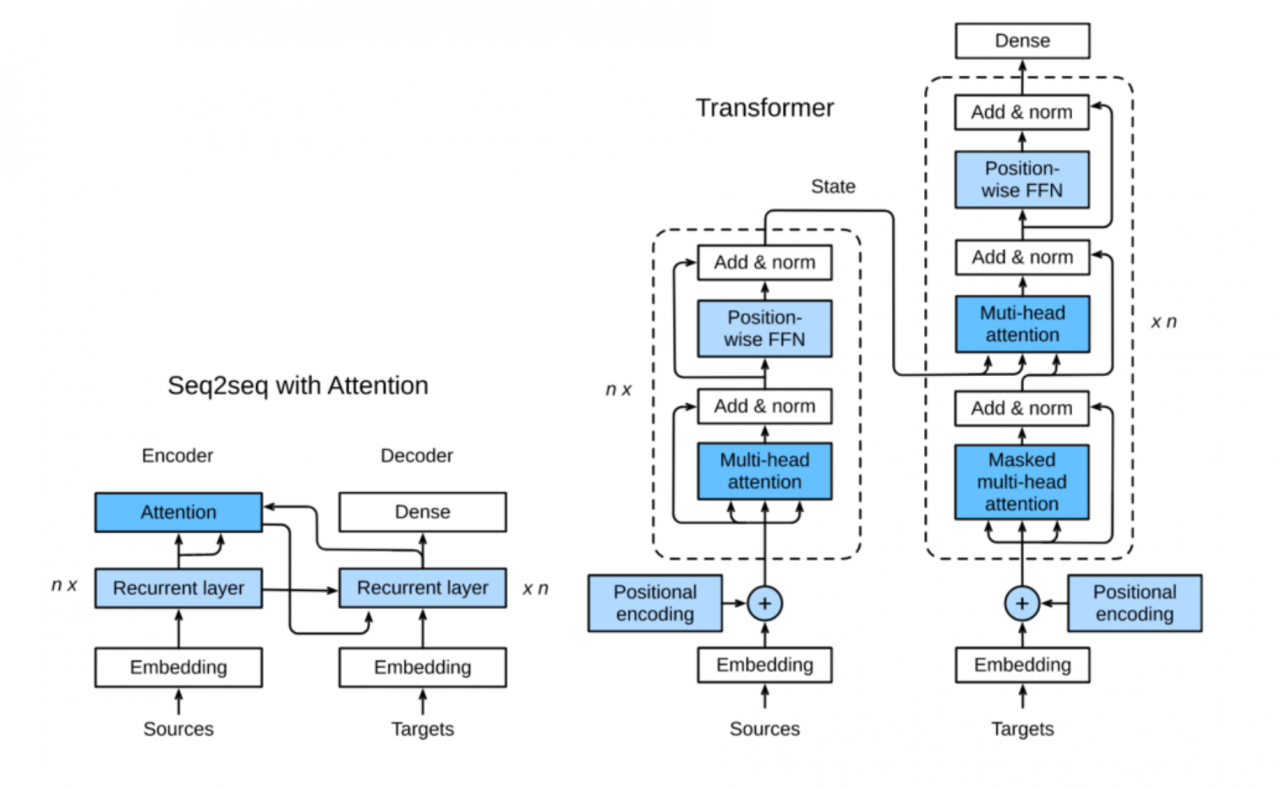
作者:渣渣菜
相关文章
Iris
2021-08-03
Coral
2021-01-26
Belle
2020-06-06
Ula
2023-05-13
Jacinda
2023-05-13
Winona
2023-05-13
Fawn
2023-05-13
Echo
2023-05-13
Maha
2023-05-13
Kande
2023-05-15
Viridis
2023-05-17
Pandora
2023-07-07
Tallulah
2023-07-17
Janna
2023-07-20
Ophelia
2023-07-20
Natalia
2023-07-20
Irma
2023-07-20