深度学习——机器翻译、注意力机制、transformer
深度学习
文章目录深度学习一、机器翻译(MT)二、注意力机制1.基本概念2.常见的注意力层(1)点积注意力(dot product/multiplicative attention)(2)多层感知机注意力(3)引入注意力机制的Seq2seq模型三、transformer多头注意层
一、机器翻译(MT) 用神经网络进行机器翻译-----神经机器翻译(NMT)。困难点在于输入和输出的序列长度不一样。 有一种结构可以解决这个困难,如下图。在Encoder结构中将原语言转换为语义编码c(隐藏状态),再通过Decoder过程转换为目标语言。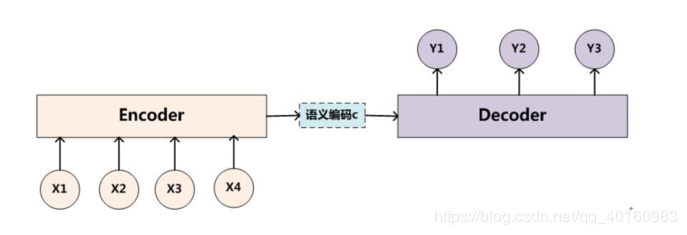 Encoder到Decoder有一种Sequence to Sequence模型,如下图所示。将源语言和目标语言的单词都形成词向量输入到隐藏层中,再根据对应的编码实现从输入到输出。
Encoder到Decoder有一种Sequence to Sequence模型,如下图所示。将源语言和目标语言的单词都形成词向量输入到隐藏层中,再根据对应的编码实现从输入到输出。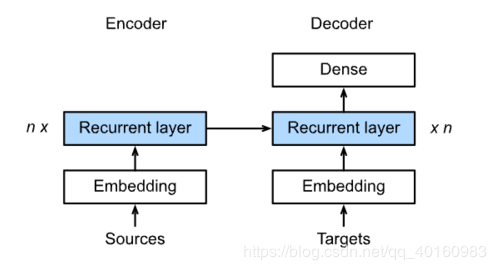
二、注意力机制 1.基本概念 上面的Sequence to Sequence模型在各个时间步数上依赖相同的背景变量(循环神经网络的背景变量是最终时间步的隐藏状态)。由于RNN机制存在长程梯度消失的问题,随着句子长度增加,seq2seq模型的结构效果不佳。 另一个问题是Decoder的目标词语可能只与输入的部分词语有关而不是与所有的输入有关,在Encoder-Decoder模型中,所有输出的单词使用的语义编码C是相同的,而语义编码C是根据输入句子X的单词经过Encoder编码产生的,所以句子X的任意单词对生成最后的目标单词的影响力是相同的。而在seq2seq模型中由于RNN的结构原因,后输入的单词影响较前输入的单词的影响力大,非等权影响。 注意力机制(Attention)可以部分解决以上问题。注意力机制可以分配给不同单词不同的注意力大小,这意味着在生成输出单词yiy_iyi时,Encoder-Decoder模型中固定的语义编码C会换成加入根据输出单词进行调整的注意力模型变化的CiC_iCi。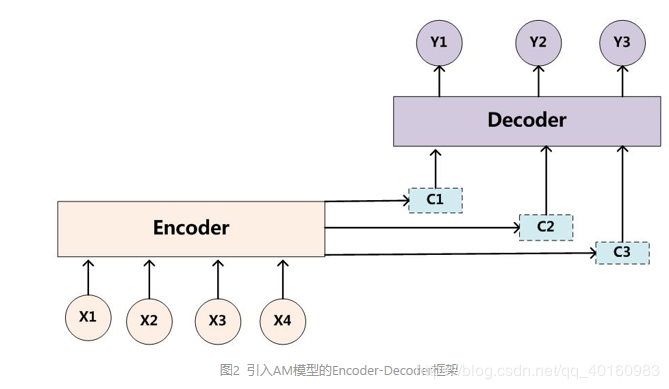 注意力机制具体过程:
第一步计算attention scores:将当前隐藏状态HiH_iHi与输入句子的每个单词对应的隐藏单元节点状态hjh_jhj对比,即通过函数F(hj,Hi)F(h_j,H_i)F(hj,Hi)获得目标单词和每个输入单词对应的可能性。(不同attention layer 的区别在于该函数的选择)
第二步将函数经过softmaxsoftmaxsoftmax归一化,取得注意力权重。
最后输入值与权重相乘加权求和输出。
表达式:ai=Fatt(hj,Hi)bi=softmax(ai)ci=∑i=1nbihi\begin{aligned}a_i &=F_{att}(h_j,H_i)\\b_i&=softmax(a_i)\\c_i&=\sum^n_{i=1}b_ih_i\end{aligned}aibici=Fatt(hj,Hi)=softmax(ai)=i=1∑nbihi
参考blog:https://www.jianshu.com/p/e14c6a722381
注意力机制具体过程:
第一步计算attention scores:将当前隐藏状态HiH_iHi与输入句子的每个单词对应的隐藏单元节点状态hjh_jhj对比,即通过函数F(hj,Hi)F(h_j,H_i)F(hj,Hi)获得目标单词和每个输入单词对应的可能性。(不同attention layer 的区别在于该函数的选择)
第二步将函数经过softmaxsoftmaxsoftmax归一化,取得注意力权重。
最后输入值与权重相乘加权求和输出。
表达式:ai=Fatt(hj,Hi)bi=softmax(ai)ci=∑i=1nbihi\begin{aligned}a_i &=F_{att}(h_j,H_i)\\b_i&=softmax(a_i)\\c_i&=\sum^n_{i=1}b_ih_i\end{aligned}aibici=Fatt(hj,Hi)=softmax(ai)=i=1∑nbihi
参考blog:https://www.jianshu.com/p/e14c6a722381
2.常见的注意力层 (1)点积注意力(dot product/multiplicative attention) 表达式:fatt(hi,sj)=HiTWahjf_{att}(h_i,s_j)=H_i^TW_a h_jfatt(hi,sj)=HiTWahj (2)多层感知机注意力 表达式:fatt(hi,sj)=vTtanh(Wkk+Wqq)f_{att}(h_i,s_j)=v^Ttanh(W_kk+W_qq)fatt(hi,sj)=vTtanh(Wkk+Wqq) (3)引入注意力机制的Seq2seq模型 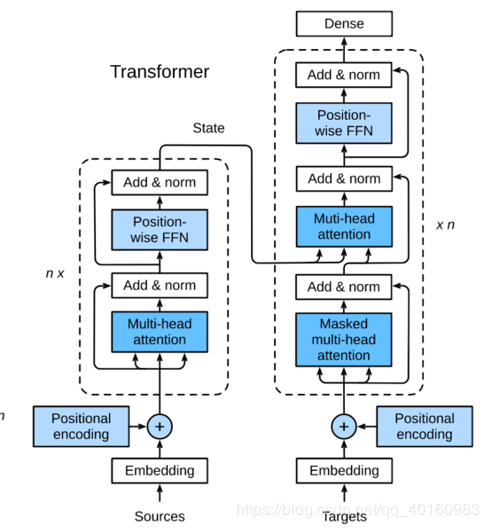
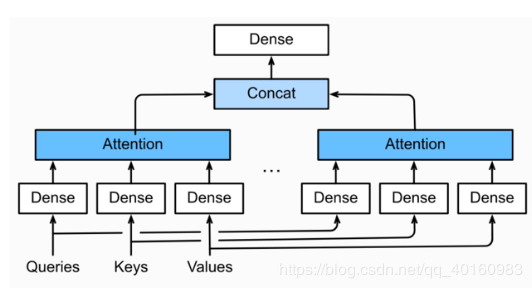
多头注意层 多头注意力层包含hhh个并行的自注意力层,每一个自注意力层是一个head,每次先计算并行的自注意力层输出,然后对这hhh个注意力头的输出拼接后整合到一个线性层中。 自注意力层结构如下图: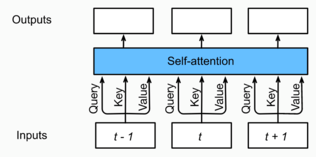
 表达式:
表达式:
每个头的输出:o(i)=fattention(Wq(i)q,Wk(i)k,Wv(i)v)o^{(i)}=f_{attention}(W_q^{(i)}q,W_k^{(i)}k,W_v^{(i)}v)o(i)=fattention(Wq(i)q,Wk(i)k,Wv(i)v)线性整合:o=Wo[o(1),…,o(h)]o=W_o[o^{(1) },\ldots,o^{(h)}]o=Wo[o(1),…,o(h)]
作者:shinning0
一、机器翻译(MT) 用神经网络进行机器翻译-----神经机器翻译(NMT)。困难点在于输入和输出的序列长度不一样。 有一种结构可以解决这个困难,如下图。在Encoder结构中将原语言转换为语义编码c(隐藏状态),再通过Decoder过程转换为目标语言。
Encoder到Decoder有一种Sequence to Sequence模型,如下图所示。将源语言和目标语言的单词都形成词向量输入到隐藏层中,再根据对应的编码实现从输入到输出。二、注意力机制 1.基本概念 上面的Sequence to Sequence模型在各个时间步数上依赖相同的背景变量(循环神经网络的背景变量是最终时间步的隐藏状态)。由于RNN机制存在长程梯度消失的问题,随着句子长度增加,seq2seq模型的结构效果不佳。 另一个问题是Decoder的目标词语可能只与输入的部分词语有关而不是与所有的输入有关,在Encoder-Decoder模型中,所有输出的单词使用的语义编码C是相同的,而语义编码C是根据输入句子X的单词经过Encoder编码产生的,所以句子X的任意单词对生成最后的目标单词的影响力是相同的。而在seq2seq模型中由于RNN的结构原因,后输入的单词影响较前输入的单词的影响力大,非等权影响。 注意力机制(Attention)可以部分解决以上问题。注意力机制可以分配给不同单词不同的注意力大小,这意味着在生成输出单词yiy_iyi时,Encoder-Decoder模型中固定的语义编码C会换成加入根据输出单词进行调整的注意力模型变化的CiC_iCi。
注意力机制具体过程:
第一步计算attention scores:将当前隐藏状态HiH_iHi与输入句子的每个单词对应的隐藏单元节点状态hjh_jhj对比,即通过函数F(hj,Hi)F(h_j,H_i)F(hj,Hi)获得目标单词和每个输入单词对应的可能性。(不同attention layer 的区别在于该函数的选择)
第二步将函数经过softmaxsoftmaxsoftmax归一化,取得注意力权重。
最后输入值与权重相乘加权求和输出。
表达式:ai=Fatt(hj,Hi)bi=softmax(ai)ci=∑i=1nbihi\begin{aligned}a_i &=F_{att}(h_j,H_i)\\b_i&=softmax(a_i)\\c_i&=\sum^n_{i=1}b_ih_i\end{aligned}aibici=Fatt(hj,Hi)=softmax(ai)=i=1∑nbihi
参考blog:https://www.jianshu.com/p/e14c6a7223812.常见的注意力层 (1)点积注意力(dot product/multiplicative attention) 表达式:fatt(hi,sj)=HiTWahjf_{att}(h_i,s_j)=H_i^TW_a h_jfatt(hi,sj)=HiTWahj (2)多层感知机注意力 表达式:fatt(hi,sj)=vTtanh(Wkk+Wqq)f_{att}(h_i,s_j)=v^Ttanh(W_kk+W_qq)fatt(hi,sj)=vTtanh(Wkk+Wqq) (3)引入注意力机制的Seq2seq模型 
多头注意层 多头注意力层包含hhh个并行的自注意力层,每一个自注意力层是一个head,每次先计算并行的自注意力层输出,然后对这hhh个注意力头的输出拼接后整合到一个线性层中。 自注意力层结构如下图:
表达式:每个头的输出:o(i)=fattention(Wq(i)q,Wk(i)k,Wv(i)v)o^{(i)}=f_{attention}(W_q^{(i)}q,W_k^{(i)}k,W_v^{(i)}v)o(i)=fattention(Wq(i)q,Wk(i)k,Wv(i)v)线性整合:o=Wo[o(1),…,o(h)]o=W_o[o^{(1) },\ldots,o^{(h)}]o=Wo[o(1),…,o(h)]
作者:shinning0
相关文章
Iris
2021-08-03
Coral
2021-01-26
Belle
2020-06-06
Ula
2023-05-13
Jacinda
2023-05-13
Winona
2023-05-13
Fawn
2023-05-13
Echo
2023-05-13
Maha
2023-05-13
Kande
2023-05-15
Viridis
2023-05-17
Pandora
2023-07-07
Tallulah
2023-07-17
Janna
2023-07-20
Ophelia
2023-07-20
Natalia
2023-07-20
Irma
2023-07-20