《动手学深度学习》机器翻译及相关技术;注意力机制与Seq2seq模型;Transformer
机器翻译(MT):将一段文本从一种语言自动翻译为另一种语言,用神经网络解决这个问题通常称为神经机器翻译(NMT)。
主要特征:输出是单词序列而不是单个单词。 输出序列的长度可能与源序列的长度不同。
在翻译时,输入句子和输出句子往往不一样长,所以为了处理输入和输出都是不定长序列时,可以使用编码器–解码器或者seq2seq模型。它们本质上都用到了两个神经网络,分别叫做编码器和解码器。
编码器:分析输入序列
解码器:生成输出序列
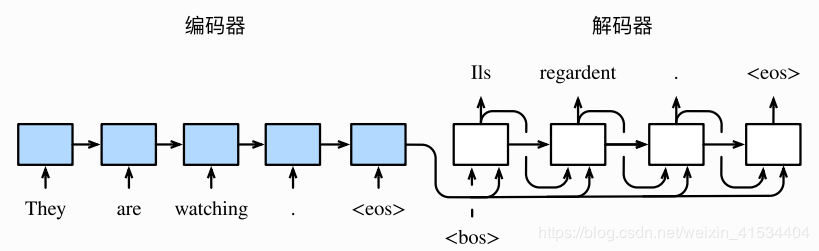
句子先进入输入网络,再将输出的表征或编码信息作为解码器网络的输入。
解码器在各个时间步中使用输入句子的编码信息和上个时间步的输出及隐藏状态作为输入。
在句子的末尾增加了特殊符号""(end of sequence),解码器的最初时间步增加了特殊符号""(beginning of sequence)
不定长输入序列 -> 定长的背景变量ccc(包含输入序列信息)
循环神经网络隐藏层的变换:
ht=f(xt,ht−1)h_t=f(x_t,h_t-1)ht=f(xt,ht−1)
转换为背景变量:
c=q(h1,...,ht)c=q(h_1,...,h_t)c=q(h1,...,ht)
背景变量ccc+上一时间步输出yt′y_{t'}yt′ -> 解码器隐藏状态 -> 输出序列的条件概率P(yt′∣11,...,yt′−1,c)P(y_{t'}|1_1,...,y_{t'-1},c)P(yt′∣11,...,yt′−1,c)
解码器隐藏层的变换:
st′=g(yt′,c,st′−1)s_{t'}=g(y_{t'},c,s_{t'-1})st′=g(yt′,c,st′−1)
有了解码器的隐藏状态后,使用自定义的输出层和softmax运算计算P(yt′∣11,...,yt′−1,c)P(y_{t'}|1_1,...,y_{t'-1},c)P(yt′∣11,...,yt′−1,c)。
上面我们得到了一个条件概率的解空间,现在我们需要在解空间中寻找最优解。
贪婪搜索第一个解决发难:贪婪搜素(greedy search),即贪心搜索。对于数去序列任意时间步t′t't′,我们从∣y∣|y|∣y∣个词中搜索出条件概率最大的词
yt′=argmaxP(y∣y1,...yt′−1,c)y_{t'}=argmaxP(y|y1,...y_{t'-1},c)yt′=argmaxP(y∣y1,...yt′−1,c)
作为输出。一旦搜索出""符号,或者输出序列长度已经达到了最大长度T′T'T′,便完成输出。
但是这样的搜索策略并不能保证得到最优输出,他没有考虑输出词间的语义关系。
改进贪婪搜索。定义超参数kkk(束宽)。在时间步选择条件概率最大的kkk个词,分别组成kkk个候选输出序列,
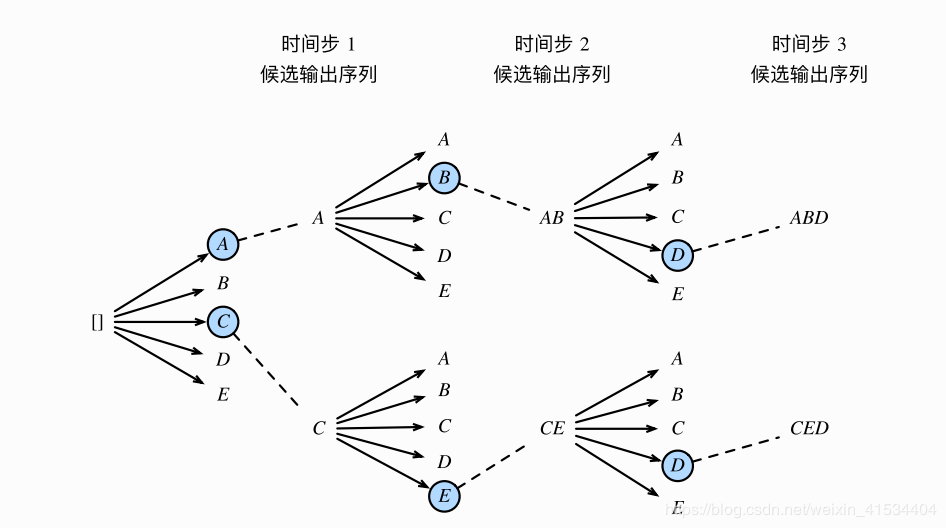
如图k=2k=2k=2,最后选出全局条件概率最优的即可。
在最终候选输出序列的集合中,我们取以下分数最高的序列作为输出序列:
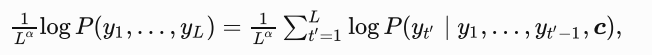
其中LLL为最终候选序列长度,α\alphaα一般可为0.75.分母上的LαL^{\alpha}Lα是为了惩罚较长序列在以上分数中较多的对数相加项。
例如,输入英文序列“They are watching.”,输出法语序列“IIs regardent.”。其中在解码器每个时间步可能只需要输入序列的部分信息。如“They are” -> “IIs”.
看上去就像是在解码器的每一时间步对输入序列中不同时间步的表征或编码信息分配不用的注意力。这也是注意力机制的由来。
具体做法,上面st′=g(yt′,c,st′−1)s_{t'}=g(y_{t'},c,s_{t'-1})st′=g(yt′,c,st′−1),解码器每个时间步使用相同的背景变量,这了我们在每个时间步使用加权过的不同的背景变量st′=g(yt′,ct′,st′−1)s_{t'}=g(y_{t'},c_{t'},s_{t'-1})st′=g(yt′,ct′,st′−1)
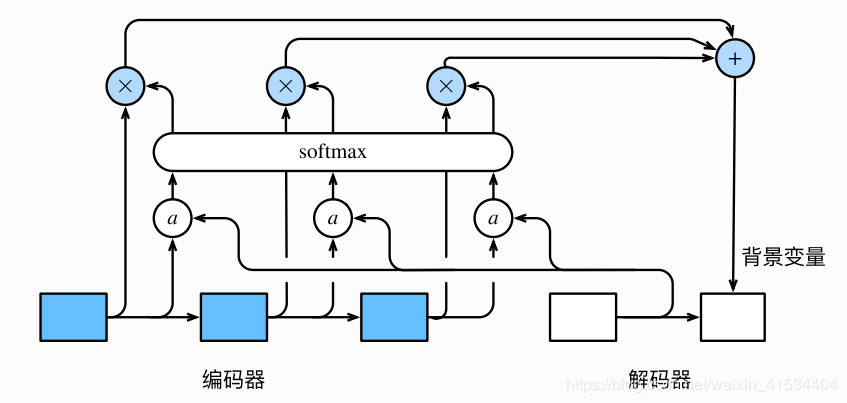
解码器在时间步t′t't′的背景变量为所有编码器隐藏状态的加权平均:
ct′=∑t=1Tαt′thtc_{t'}=\sum_{t=1}^T\alpha_{t't}h_tct′=∑t=1Tαt′tht
αt′t=exp(et′t)∑k=1Texp(et′k),t=1,...T\alpha_{t't}=\frac{exp(e_{t't})}{\sum_{k=1}^Texp(e_{t'k})},t=1,...Tαt′t=∑k=1Texp(et′k)exp(et′t),t=1,...T
et′t=a(st′−1,ht)e_{t't}=a(s_{t'-1},h_t)et′t=a(st′−1,ht)
这里函数a有多种选择,如果两个输入向量长度相同,一个简单的选择是计算它们内积a(s,h)=sTha(s,h)=s^Tha(s,h)=sTh。而最早提出注意力机制的论文则将输入连结后通过含单隐层的多层感知机交换:
a(s,h)=vTtanh(Ess+Whh)a(s,h)=v^Ttanh(E_ss+W_hh)a(s,h)=vTtanh(Ess+Whh)
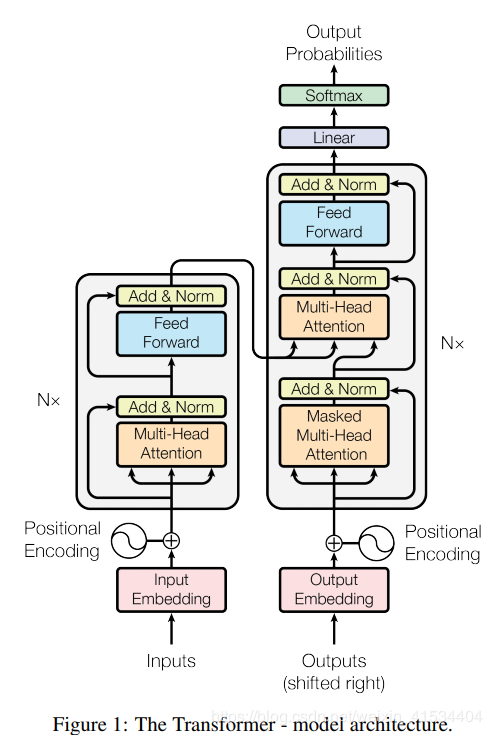
变形金刚
在之前的章节中,我们已经介绍了主流的神经网络架构如卷积神经网络(CNNs)和循环神经网络(RNNs)。让我们进行一些回顾:
· CNNs 易于并行化,却不适合捕捉变长序列内的依赖关系。
· RNNs 适合捕捉长距离变长序列的依赖,但是却难以实现并行化处理序列。
为了整合两者优势,Vaswani et al., 2017 创新性地使用注意力机制设计了Transformer模型。该模型利用attention机制实现了并行化捕捉序列依赖,并且同时处理序列的每个位置的tokens,上述优势使得Transformer模型在性能优异的同时大大减少了训练时间
讲解推荐:台大 李宏毅老师
作者:Void_Pointer -