论文阅读课7-使用句子级注意力机制结合实体描述的远程监督关系抽取(APCNN+D)2017
Ji, G., et al. (2017). Distant Supervision for Relation Extraction with Sentence-Level Attention and Entity Descriptions. Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence (AAAI-17).
ecml数据集 abstract
远程监督关系提取是一种将关系提取扩展到包含数千个关系的超大型语料库的有效方法。但是,现有方法在选择有效实例方面存在缺陷,并且缺乏有关实体的背景知识。在本文中,我们提出了一个句子级别的注意力模型来选择有效实例,该模型充分利用了知识库中的监督信息。我们从Freebase和Wikipedia页面中提取实体描述,以补充我们任务的背景知识。背景知识不仅为预测关系提供了更多信息,而且还为注意力模块带来了更好的实体表示形式。我们对一个广泛使用的数据集进行了三个实验,实验结果表明我们的方法明显优于所有基线系统。
大规模语料库:远程监督 以前的不足: 在选择有效实例方面不足 缺少实体的背景知识 本文: attention:用以选择有效实体 提取实体描述,补充背景知识(Freebase,Wikipedia) 用途:为预测关系提供了更多的信息,而且还为注意力模块带来了更好的实体表示 1. Introduction远程监督下的关系提取(RE)旨在预测受知识库(KBs)监督的文本中的成对实体之间的语义关系。它启发式地将文本中的实体与给定的KB对齐,并使用此对齐来学习关系提取器。训练数据自动标记如下:对于KB中的三元组r(e1,e2),所有同时提及实体和的句子均视为关系r的训练实例。图1显示了三元组/ location / location / contains(内华达州,拉斯维加斯)的训练实例。从S1到S4的句子都提到了内华达州和拉斯维加斯实体,因此它们都是关系/ location / location / contains的训练实例。对于许多自然语言处理(NLP)应用程序(例如自动知识完成和问题解答)而言,该任务至关重要。
文本中实体与给定KB的实体对齐 训练实例:对KB的三元组r(e1,e2),包含e1,e2提及的所有句子,均为r的训练实例。 远程监督:错误标记多—共现不等于有关系远程监管策略是一种自动标记训练数据的有效方法,但是它受到错误标记问题的困扰(Riedel,Yao和McCallum 2010)。提到两个实体的句子可能无法表达将它们在KB中链接的关系。这两个实体可能只是出现在同一句子中,因为他们和同一个主题相关。
例如,在图1中,句子S2和S4都提到了内华达州和拉斯维加斯,但是它们没有表达关系/ location / location / contains。
远程监督方法
Mintz等人(2009)忽略了这个问题,并从所有句子中提取了特征以提供一个关系分类器。 Riedel,Yao和McCallum(2010)提出了**“最少一次表达”**的假设,并使用无向图模型来预测哪些句子表达了这种关系。 基于多实例学习(Dietterich,Lathrop和Lozano-P'erez 1997),Hoffmann等(2011)和Surdeanu等(2012)还使用概率图形模型选择句子并添加与其关系提取系统重叠的关系。 概率图形模型(Riedel,Yao和McCallum,2010年; Hoffmann等,2011年; Surdeanu等,2012年)已经考虑了观察,但是他们设计用来选择有效句子的功能通常来自于先前存在的NLP工具,这些工具遭受了错误传播和累积(Bach和Badaskar,2007年)。 Zeng等人(2015年)将多实例学习(MIL)和分段卷积神经网络(PCNN)结合起来,选择最可能的有效句子并预测了关联,从而在(Riedel)开发的数据集(Riedel, Yao, and McCallum 2010)上取得了最先进的性能。 用PCNN提取特征(免于nlp工具的错误积累) 但是,在学习过程中,其MIL模块仅选择了一个具有最大概率成为有效候选者的句子。此策略未充分利用监督信息。 —>可能有多个句子APCNN
任务定义 所有句子被分到N组bags中,{B1,B2,⋯,Bi}\{B_1,B_2,⋯,B_i\}{B1,B2,⋯,Bi} 每个bag中的的句子都描述了同一组实体的关系r(e1,e2)。 每个bag中有qi句句子,Bi={b1,b2,⋯,bqi}B_i=\{b_1,b_2,⋯,b_{q_i}\}Bi={b1,b2,⋯,bqi}(i=1,2,…,N) 这个任务的目标是,预测每个bag对应的label。 预测看不见的袋子的标签。 instance–句子 以上的不足: (1)一个袋子可能包含多个有效句子。 (2)实体描述可以提供有用的背景知识,是完成任务的有用资源。 基于此提出本文的创新点: 结合zeng和概率图:使用神经网络提取特征+从一个包提取多个有效句子 PCNN(得到句子特征)–>结果加权和(权重是隐层计算)–>(包的特征) attention:用以选择有效的实体 权重:句子向量v;e1-e2 添加实体描述信息 使用传统CNN从Freebase或Wikipedia中抽取实体特征 用途:为预测关系提供了更多的信息,而且还为注意力模块带来了更好的实体表示 本文贡献: (1)我们引入了一个句子级别的注意力模型来选择一个袋子中的多个有效句子。该策略充分利用了监督信息。 (2)我们使用实体描述为预测关系和改善实体表示提供背景知识; (3)我们对广泛使用的数据集3进行实验,并达到了最新水平。 *
为了选择多个有效句子,我们提出了一个基于PCNN的句子层次注意模型(用APCNN表示),该模型使用PCNN提取句子特征并通过注意模块学习句子的权重。我们希望注意机制能够通过为有效句子分配较高的权重,为无效句子分配较低的权重,来有选择地关注相关句子。这样,APCNN可以识别出一个书包中的多个有效句子。具体而言,受TransE(Bordes等人,2013年)的启发,该模型用(粗体,斜体字母表示矢量)对三元组进行建模,我们使用来e1-e2表示句子中e1和e2之间的关系(我们将在后面显示更多解释) 。对于皮包,我们首先使用PCNN提取每个句子的特征向量v,然后通过连接方式[v;e1-e2](Luong,Pham和Manning 2015)通过隐藏层计算每个句子的注意力权重。最后,所有句子特征向量的加权总和就是包的特征。此外,为了将更多背景知识编码到我们的模型中,我们使用卷积神经网络(CNN)提取实体描述的特征向量,并通过在APCNN的目标函数(称为APCNNs +D)上添加约束,使其接近相应的实体向量。 D,其中“ D”表示描述)。背景知识不仅为预测关系提供了更多信息,而且还为注意力模块带来了更好的实体表示形式。
2.方法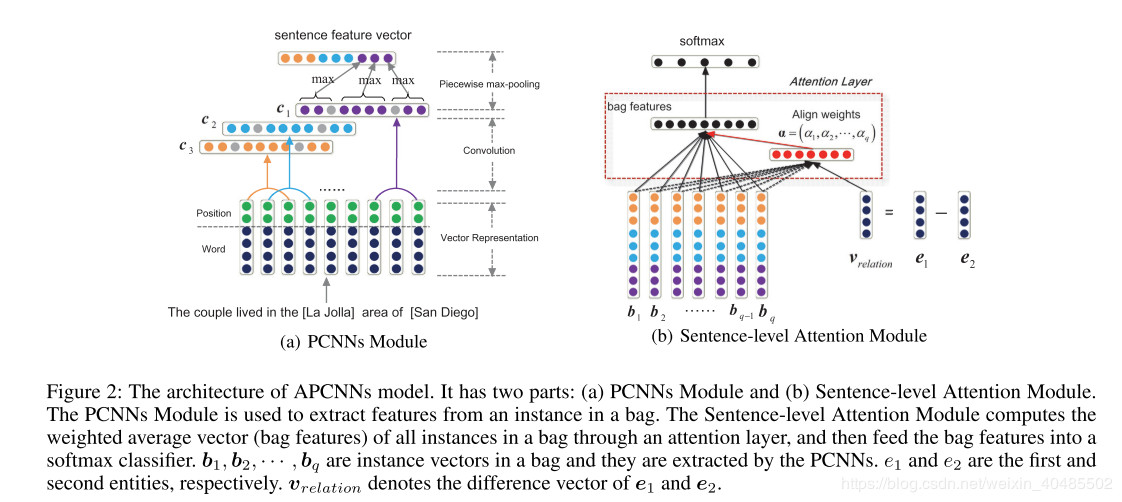

通过将Freebase5关系与纽约时报(NYT)语料保持一致,我们使用(Riedel,Yao和McCallum 2010)开发的数据集评估了我们的方法。培训数据与NYT语料库的2005-2006年保持一致,而测试数据与2007年保持一致。(Hoffmann等人2011; Surdeanu等人2012; Zeng等人2015)也使用了该数据集。它的实体带有Stanford NER注释,并链接到Freebase。数据集包含52个关系(不包括关系“ NA”)和39,528个实体。我们使用word2vec6在NYT语料库上训练单词嵌入,并将嵌入用作初始值
ecml数据集–Freebase与NYT对齐 远程监督 Distant Supervision for Relation Extraction with Sentence-Level Attention and Entity Descriptions NYT 4.2 评价指标 Held-out evaluation 比较freebase的标签和预测的标签(包的标签) 远程监督可能会产生一些错误标签(freebase的不完整本质 Human evaluation 手动检查不存在于freebase的标签(freebase中标记为NA top-k 4.3实验结果和分析 4.3.1参数设置In our experiments, we tune all of the models using
three-fold validation on the training set dimension of word embedding kw among {50, 100, 200, 300}, the dimension of position embedding kd among {5, 10, 20}, the windows size w among {3, 5, 7}, the number of feature maps n among {50, 100, 150, 200, 230}, the weight λ among {0.001, 0.01, 0.1, 1.2}, batch size among {50, 100, 150, 200}. The best configurations are: kw =50, kd =5, w =3, n = 200, λ =0.01, the batch size is 50. Following (Hinton et al. 2012), we set the dropout rate 0.5. 4.3.2 baseline Mintz is proposed by (Mintz et al. 2009) which extracted features from all instances; MultiR is a multi-instance learning method proposed by (Hoffmann et al. 2011); MIML is a multi-instance multi-labels method proposed by (Surdeanu et al. 2012); PCNNs+MIL is the state-of-the-art method proposed by (Zeng et al. 2015). 4.3.3 conclusion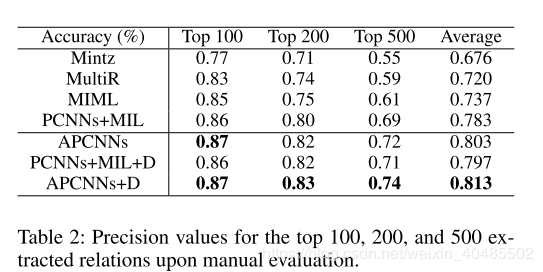
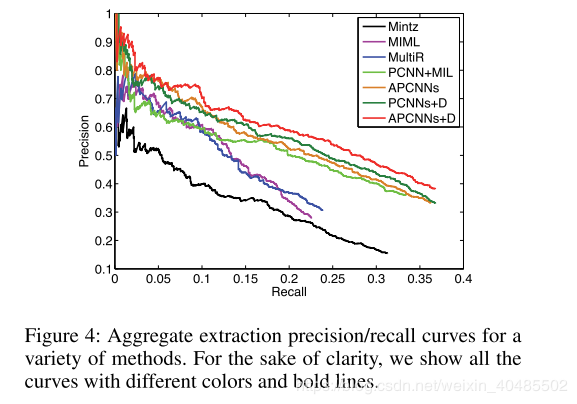
held-out evaluation
注意力机制:可以比其他模型使用更多的监督信息 加D的比不加的好:实体描述可以提供背景知识以提高预测准确性 APCNN+D最好:A+D的结合对任务有好处 held-out评估:所有模型的recall都低,因为遭受了freebase的误报手动评估来消除这个问题:(结论一样)
(1)APCNNs比PCNNs + MIL获得更好的预测精度,这表明关注模块可以选择更多有效实例; (2)PCNNs + MIL + D也优于PCNNs + MIL,这证明了实体描述提供了更多有用的背景信息; (3)APCNNs + D具有最先进的性能,因此注意模块和实体描述都非常有用。
显然,注意力模块借助实体描述可以更好地识别无效/有效实例。因此,实体描述提供的背景知识可以提高注意力模块的性能。
不可用的句子比重低 5.相关工作 5.1监督学习 多分类问题 GuoDong等人(2005年)探索了通过进行文本分析而选择的一组功能(词汇和句法),然后他们将这些功能转换为符号ID,并将其输入到SVM分类器中。其他工作 (Bunescu和Mooney 2005; Moneyy和Bunescu 2005; Zelenko,Aone和Richardella 2003)使用内核方法(例如子序列内核和依赖树内核)完成任务,这需要使用NLP工具预处理输入数据。这些方法是有效的。相反, Zeng等人(2014)利用卷积深度神经网络(CNN)提取词法和句子层次特征。 dos Santos,Xiang和Zhou(2015)基于CNN模型,提出了一种基于CNN排名的分类模型(CR-CNN)。这些方法已经实现了高精度和召回率。 不幸的是,他们需要明确的人工注释文本,这使得它们不太可能扩展到大型文本语料库。 5.2远程监督学习 用于关系提取的远程监管方法将文本启发式地对齐给定的KB,并使用对齐来学习关系提取器。他们将大量结构化数据源(例如Freebase)视为薄弱的监管信息。由于这些方法不需要手工标记的数据集,并且KB近年来增长很快,因此吸引了很多关注。 Mintz等人(2009年)从所有句子中提取特征,然后将它们输入到分类器中,该分类器忽略了数据噪声并会学习一些无效实例。 Riedel,Yao和McCallum(2010),Hoffmann等人(2011)和Surdeanu等人(2012)使用图形模型选择有效的句子和预测关系。 Nguyen和Moschitti(2011)利用关系定义和Wikipedia文档来改善他们的系统。这些方法依靠传统的NLP工具提取句子特征。 Zeng等人(2015年)使用PCNN来自动学习句子级特征并考虑了实体位置的结构信息。但是其MIL模块在训练过程中只能选择一个有效的句子,而没有充分利用监督信息。 Lin et al。,(2016)提出利用注意力来选择内容丰富的句子。 与之相比,我们的工作有两个创新: (1)Lin等人(2016)将关系r的嵌入初始化为模型中的参数,并且我们的工作使用 表示关系,其中和是嵌入在两个给定的实体中; 2)我们模型中的描述为RE任务提供了更多的背景知识,并改善了注意力模块的实体表示。另一行是介绍诸如知识图之类的外部语义存储库(Weston等,2013; Wang等,2014)。这些工作通过连接知识图和文本进行关系提取实验。作者:叶落叶子