pytorch_task4机器翻译及相关技术;注意力机制与Seq2seq模型
机器翻译(MT):将一段文本从一种语言自动翻译为另一种语言,用神经网络解决这个问题通常称为神经机器翻译(NMT)。 主要特征:输出是单词序列而不是单个单词。 输出序列的长度可能与源序列的长度不同。
步骤:
1、数据预处理。将数据集清洗、转化为神经网络的输入minbatch
2、分词。字符串—单词组成的列表
3、建立词典。单词组成的列表—单词id组成的列表
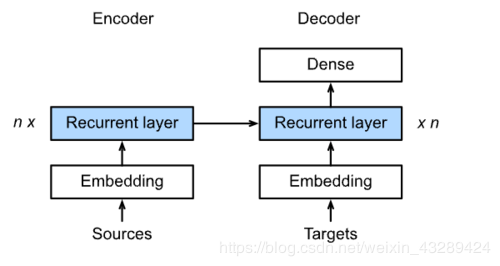
4、Encoder-Decoder
encoder:输入到隐藏状态
decoder:隐藏状态到输出
训练:
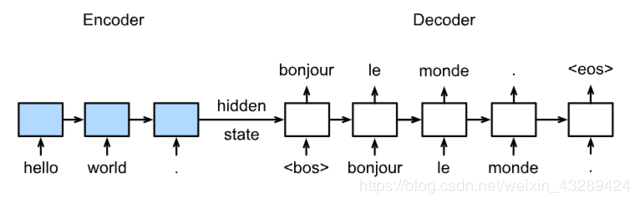
预测
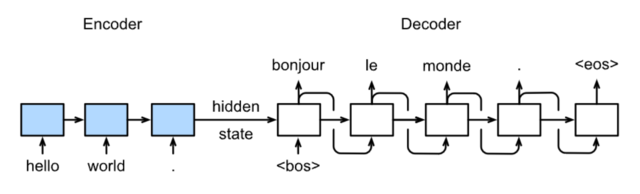
具体结构:
在“编码器—解码器(seq2seq)”⼀节⾥,解码器在各个时间步依赖相同的背景变量(context vector)来获取输⼊序列信息。当编码器为循环神经⽹络时,背景变量来⾃它最终时间步的隐藏状态。将源序列输入信息以循环单位状态编码,然后将其传递给解码器以生成目标序列。然而这种结构存在着问题,尤其是RNN机制实际中存在长程梯度消失的问题,对于较长的句子,我们很难寄希望于将输入的序列转化为定长的向量而保存所有的有效信息,所以随着所需翻译句子的长度的增加,这种结构的效果会显著下降。
与此同时,解码的目标词语可能只与原输入的部分词语有关,而并不是与所有的输入有关。例如,当把“Hello world”翻译成“Bonjour le monde”时,“Hello”映射成“Bonjour”,“world”映射成“monde”。在seq2seq模型中,解码器只能隐式地从编码器的最终状态中选择相应的信息。然而,注意力机制可以将这种选择过程显式地建模。
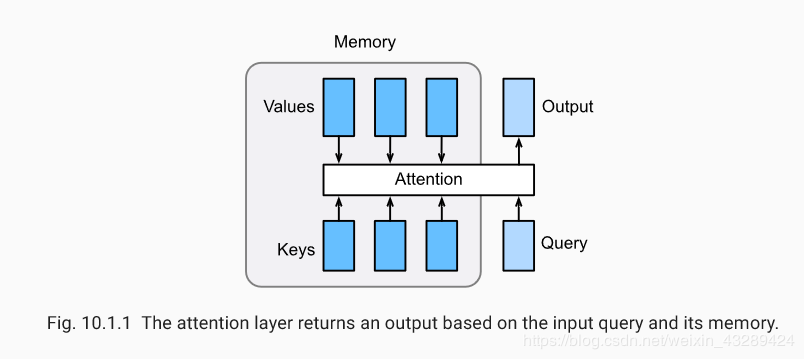
引入注意力机制的Seq2seq模型
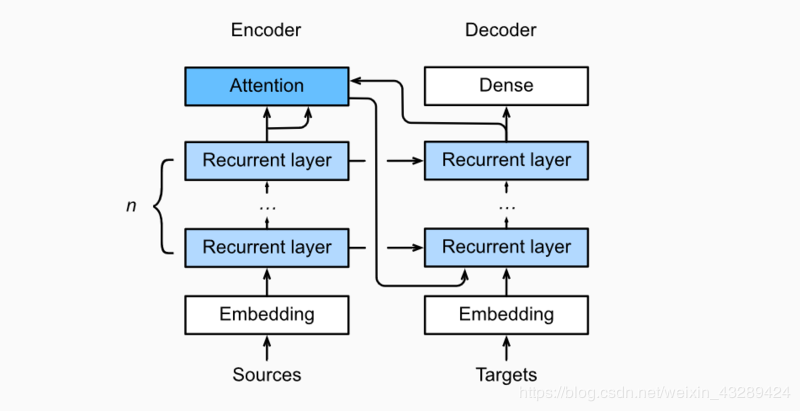
本节中将注意机制添加到sequence to sequence 模型中,以显式地使用权重聚合states。下图展示encoding 和decoding的模型结构,在时间步为t的时候。此刻attention layer保存着encodering看到的所有信息——即encoding的每一步输出。在decoding阶段,解码器的 t 时刻的隐藏状态被当作query,encoder的每个时间步的hidden states作为key和value进行attention聚合. Attetion model的输出当作成上下文信息context vector,并与解码器输入 Dt 拼接起来一起送到解码器:
作者:2017133130