机器学习实战笔记4——主成分分析
1、机器学习导论 8、稀疏表示
2、KNN及其实现 9、核方法
3、K-means聚类 10、高斯混合模型
4、主成分分析 11、嵌入学习
5、线性判别分析 12、强化学习
6、贝叶斯方法 13、PageRank
7、逻辑回归 14、深度学习
维数灾难最早是由理查德·贝尔曼(Richard E. Bellman)在考虑优化问题时提出来的 ,它用来描述当(数学)空间维度增加时,分析和组织高维空间(通常有成百上千维)中的数据,因体积指数增加而遇到各种问题场景。
维数灾难这个概念具有的共同特点是:当维度增加时,空间的体积增加得很快,使得可用的数据变得稀疏。
生活中多维数据比较的例子很多,比如人的三围及身高体重、游戏角色的六维属性等等。我们拿大家最熟悉的成绩来说,小学时,我们可能只有语数英三科(三维),想要和小伙伴比较成绩,关键看到底是哪一个科目(某一特征值)具体影响了我们之间的差距,因为科目不多,还比较容易,但到了中学,我们可能要学八科、九科、十科…,身边小伙伴也变多了,想要比较起来就没有之前那么容易了,而当分析某一数学问题时,可能有成百上千维的数据,样本个数也不在少数,那么总体分析就显得举步维艰。因此,我们就想让数据变得简单一些,就有了维数约简思想。
Ⅱ 维数约简 维数约简又称降维,是机器学习的一种必要手段。若数据X=X=X={xix_ixi}是属于nnn维空间的,通过特征提取或者特征选择的方法,将原空间的维数降至kkk维,要求kkk远小于nnn,并满足:kkk维空间的特性能反映原空间数据的特征,这个过程称之为维数约简
维数约简即通过某种数学变换,将原始高维属性空间转变为一个低维子空间,在这个子空间中样本密度大幅度提高,距离计算也变得容易起来
由线性代数的知识我们知道,空间维度的改变依赖于变换矩阵,如XXX是一个nnn维列向量X=[1,2,...,n]TX=[1,2,...,n]^TX=[1,2,...,n]T,我们想要把它变成Y=[1,2,...,m]TY=[1,2,...,m]^TY=[1,2,...,m]T,即在XXX前面乘上一个m×nm×nm×n的变换矩阵AAA
而主成分分析,就是降维里的一种重要方法。
既然要对已有的特征值进行降维变换,那么首先,我们要先得到原样本集的特征值,回顾一下线性代数的知识。
有一个nnn阶矩阵AAA,若存在数λλλ和非零nnn维列向量XXX,满足AX=λXAX=λXAX=λX,则称λ为A的一个特征值,X为A的对应于λ的一个特征向量
主成分分析(Principal Component Analysis)的出发点是从一组特征(nnn维)中计算出一组按重要性从大到小排列的新特征(kkk维,k≤nk≤nk≤n,通常取远小于nnn),它们是原有特征的线性组合,并且相互之间不相关。(比如你和小伙伴的理科成绩非常接近,那么决定你们之间差距的主要科目(新特征值PC)就是文科类的了,只关注这几科,即降维了)
①主成分特点 1. 源于质心的矢量
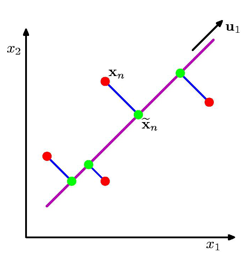
2. 主成分①指向最大方差的方向
3. 各后续主成分与前一主成分正交,且指向残差(剩余)子空间最大方差的方向
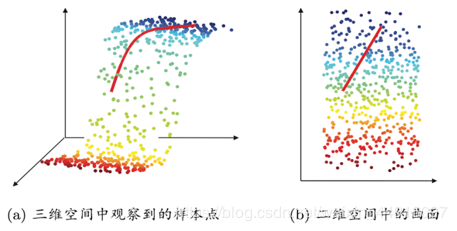
为了便于分析说明,我们举二维样本集的例子:
如下图所示,红色的两向量表示“蓝色椭圆”的长轴短轴,很明显可以看出,假如我们把样本集的点投影到长轴上,更能反映出样本集整体的分布,故在这个例子里我们把长轴记为主成分#1,与长轴正交(互不相关)的短轴记为主成分#2,理想情况下,短轴的模(高维情况下称范数)为0,即仅通过长轴就可以完全分析出样本集的分布,这就实现了完美的降维,因而我们容易知道,长短轴的模(范数)相差越大,即降维的效果越好,所以我们的目标就是,找出尽量长的长轴(标号靠前的主成分)
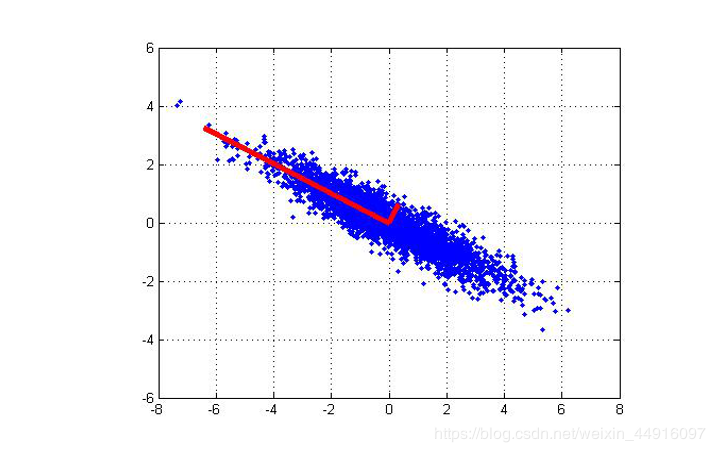
通常,我们认为信号具有较大的方差,噪声具有较小的方差,信噪比就是信号与噪声的功率之差(10lg(PsPn)10lg(\frac{P_s}{P_n})10lg(PnPs)),越大越好。如下图所示,我们把紫色线上的数据认为是信号,而蓝色线上的数据认为是噪声,因此我们的目的就是最大化投影数据的方差(样本点在紫线上最分散),最小化数据点与投影之间的均方距离(蓝线和越小)
PCA的目的就是“降噪”和“去冗余”。
“降噪”即使保留下来的维度间的相关性尽可能小
“去冗余”即使保留下来的维度含有的方差(能量)尽可能大
输入:样本集{xixixi}i=1n^n_{i=1}i=1n,低维空间维数k(即所要保留的新特征值个数)
输出:投影矩阵W=[w1,w2,...,wk]W=[w_1,w_2,...,w_k]W=[w1,w2,...,wk]
下面介绍两种PCA的实现方法:
1.对所有样本进行中心化(和期望作差)xi←xi−1n∑i=1nxix_i←x_i-\frac{1}{n}∑^n_{i=1}x_ixi←xi−n1i=1∑nxi
2.对中心化的数据{x1,x2,...,xnx_1,x_2,...,x_nx1,x2,...,xn},计算主成分#1:(即目标函数)
w1=arg(max∣∣w1∣∣=11n∑i=1n(w1Txi)2)w_1=arg(\underset{||w_1||=1}{max}\frac{1}{n}∑^n_{i=1}(w^T_1x_i)^2)w1=arg(∣∣w1∣∣=1maxn1i=1∑n(w1Txi)2)
w1Txiw^T_1x_iw1Txi即内积运算(w1w_1w1为单位向量),求的是xix_ixi在w1w_1w1上的投影,平方是为了省去求绝对值
利用拉格朗日乘数法求解最优λλλ,约束条件为||w||=1(即wTw=1w^Tw=1wTw=1)
L(w,λ)=1n(wTxi)2−λ(wTw−1)L(w,λ)=\frac{1}{n}(w^Tx_i)^2-λ(w^Tw-1)L(w,λ)=n1(wTxi)2−λ(wTw−1)
(矩阵求导)对www求导∂L∂w=(1n∑i=1nxixiT)w−λw\frac{\partial L}{\partial w}=(\frac{1}{n}∑^n_{i=1}x_ix_i^T)w-λw∂w∂L=(n1∑i=1nxixiT)w−λw
实际上,令X=[x1,x2,...,xn]X=[x_1,x_2,...,x_n]X=[x1,x2,...,xn],则XXT=1n∑i=1nxixiTXX^T=\frac{1}{n}∑^n_{i=1}x_ix_i^TXXT=n1∑i=1nxixiT
3.最大化投影方差
wk=arg(max∣∣w1∣∣=11n∑i=1n[wkT(xi−∑j=1k−1wjwjTxi⏟xi′)]2)w_k=arg(\underset{||w_1||=1}{max}\frac{1}{n}∑^n_{i=1}[w^T_k(\underbrace{x_i-∑^{k-1}_{j=1}w_jw_j^Tx_i}_{\text{$x_i'$}})]^2)wk=arg(∣∣w1∣∣=1maxn1i=1∑n[wkT(xi′xi−j=1∑k−1wjwjTxi)]2)
后面一串 xi−∑j=1k−1wjwjTxix_i-∑^{k-1}_{j=1}w_jw_j^Tx_ixi−∑j=1k−1wjwjTxi 可以简单点理解为,扣掉前面那个主成分的方向,在剩下的残差子空间里求新的主成分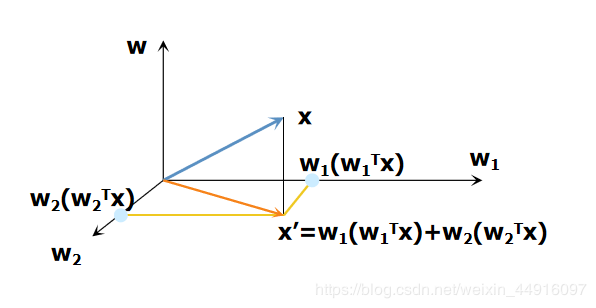
1.对所有样本进行去中心化(和期望作差)xi←xi−1n∑i=1nxix_i←x_i-\frac{1}{n}∑^n_{i=1}x_ixi←xi−n1i=1∑nxi
2.计算样本的协方差矩阵CCC
C=(cij)n×n=[c11c12...c1nc21c22...c2n............cn1cn2...cnn]C=(c_{ij})_{n×n}=\left[
\begin{matrix}
c_{11} & c_{12} & ... & c_{1n}\\
c_{21} & c_{22} & ... & c_{2n} \\
... & ... & ... & ... \\
c_{n1} & c_{n2} & ... & c_{nn}
\end{matrix}
\right]
C=(cij)n×n=⎣⎢⎢⎡c11c21...cn1c12c22...cn2............c1nc2n...cnn⎦⎥⎥⎤
cij=Cov(Xi,Yj)c_{ij}=Cov(X_i,Y_j)cij=Cov(Xi,Yj) i,j=1,2,...,ni,j=1,2,...,ni,j=1,2,...,n
(对角线元素为某一维度的方差)
3.对协方差矩阵C做特征值分解(即求所有满足的特征值和特征向量)CW′=λW′CW'=λW'CW′=λW′(也可以用拉格朗日乘数法只求所需的最大的k个)
4.取最大的k个特征值所对应的特征向量w1,w2,...,wkw_1,w_2,...,w_kw1,w2,...,wk
比较详细的PCA数学推导过程主成分分析(PCA)原理详解
——————————这节课的理论理解是真的费劲啊!————————
今日任务1.给定的图像数据集,可视化并输出聚类性能(上节课还想偷懒,没想到该来的这么快就来了)
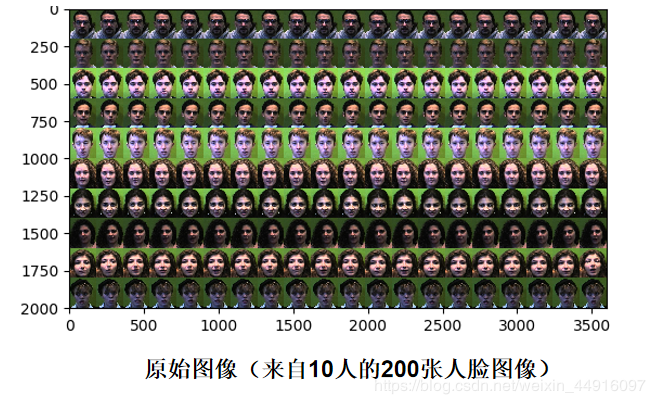
2.给定的图像数据集,计算相应的特征脸(Eigenfaces)
注:不是每一组20张算一个特征脸,是200张取前十个特征脸(这特征脸有点恐怖,不是说好提取完是张伟吗)

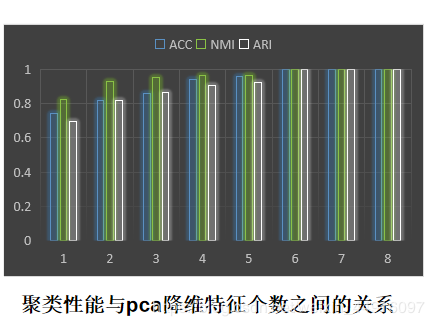
3.给定图像数据集,探讨PCA降维后特征个数与聚类性能的关系
1、今天要用到python的库cv2(版本更新被合并到opencv_python里了),提前装一下
pip install opencv_python -i https://pypi.tuna.tsinghua.edu.cn/simple
import matplotlib.pyplot as plt
import os
import cv2 as cv
import numpy as np
from sklearn.cluster import KMeans
from PIL import Image
from ML_clustering_performance import clusteringMetrics
path = 'C:/Users/1233/Desktop/Machine Learning/face_images/'
h, w = 200, 180
IMAGE_COLUMN = 20 # 列
IMAGE_ROW = 10 # 行
to_image = Image.new('RGB', (IMAGE_COLUMN * w, IMAGE_ROW * h))
def createDatabase(path):
# 查看路径下所有文件
TrainFiles = os.listdir(path) # 遍历每个子文件夹
# 计算有几个文件(图片命名都是以 序号.jpg方式)
Train_Number = len(TrainFiles) # 子文件夹个数
train = []
y_sample = []
# 把所有图片转为1维并存入T中
for k in range(0, Train_Number):
Trainneed = os.listdir(path + '/' + TrainFiles[k]) # 遍历每个子文件夹里的每张图片
Trainneednumber = len(Trainneed) # 每个子文件里的图片个数
for i in range(0, Trainneednumber):
img = Image.open(path + '/' + TrainFiles[k] + '/' + Trainneed[i])
to_image.paste(img, (i * w, k * h)) # 把读出来的图贴到figure上
image = cv.imread(path + '/' + TrainFiles[k] + '/' + Trainneed[i]).astype(np.float32) # 数据类型转换
image = cv.cvtColor(image, cv.COLOR_RGB2GRAY) # RGB变成灰度图
train.append(image)
y_sample.append(k)
train = np.array(train)
y_sample = np.array(y_sample)
return train, y_sample
# n_samples, h, w = 200, 200, 180
X, y = createDatabase(path)
# print(X.shape)
X_ = X.reshape(X.shape[0], h*w)
kms = KMeans(n_clusters=10)
y_sample = kms.fit_predict(X_, y)
print(clusteringMetrics(y, y_sample))
plt.imshow(to_image)
plt.show()
(↓↓↓别人家的代码系列)
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
import matplotlib.image as imgplt
import os
import pandas as pd
from ML_clustering_performance import clusteringMetrics
name = []
target = []
def getimage():
# 获取文件并构成向量
# 预测值为1维,把一张图片的三维(RGB)压成1维,那么n张图片就是二维
global total_photo
file = os.listdir('C:\\Users\\1233\\Desktop\\Machine Learning\\face_images') # 遍历face_images里每个子文件夹
i = 0
for subfile in file:
photo = os.listdir('C:\\Users\\1233\\Desktop\\Machine Learning\\face_images\\' + subfile) # 遍历每个子文件夹里的照片
for name in photo:
photo_name.append('C:\\Users\\1233\\Desktop\\Machine Learning\\face_images\\' + subfile+'\\'+name)
target.append(i)
i += 1
print(photo_name)
for path in photo_name:
photo = imgplt.imread(path)
# photo = cv.imread(path)
photo = photo.reshape(1, -1)
photo = pd.DataFrame(photo)
total_photo = total_photo.append(photo, ignore_index=True)
total_photo = total_photo.values
def kmeans():
clf = KMeans(n_clusters=10)
clf.fit(total_photo)
y_predict = clf.predict(total_photo)
centers = clf.cluster_centers_
result = centers[y_predict]
result = result.astype("int64")
result = result.reshape(200, 200, 180, 3) # 图像的矩阵大小为200,180,3
return result, y_predict
def draw():
fig, ax = plt.subplots(nrows=10, ncols=20, sharex=True, sharey=True, figsize=[15, 8], dpi=80)
plt.subplots_adjust(wspace=0, hspace=0)
count = 0
for i in range(10):
for j in range(20):
ax[i, j].imshow(result[count])
count += 1
plt.show()
def score():
print(clusteringMetrics(target, y_predict))
total_photo = pd.DataFrame()
getimage()
result, y_predict = kmeans()
draw()
score()
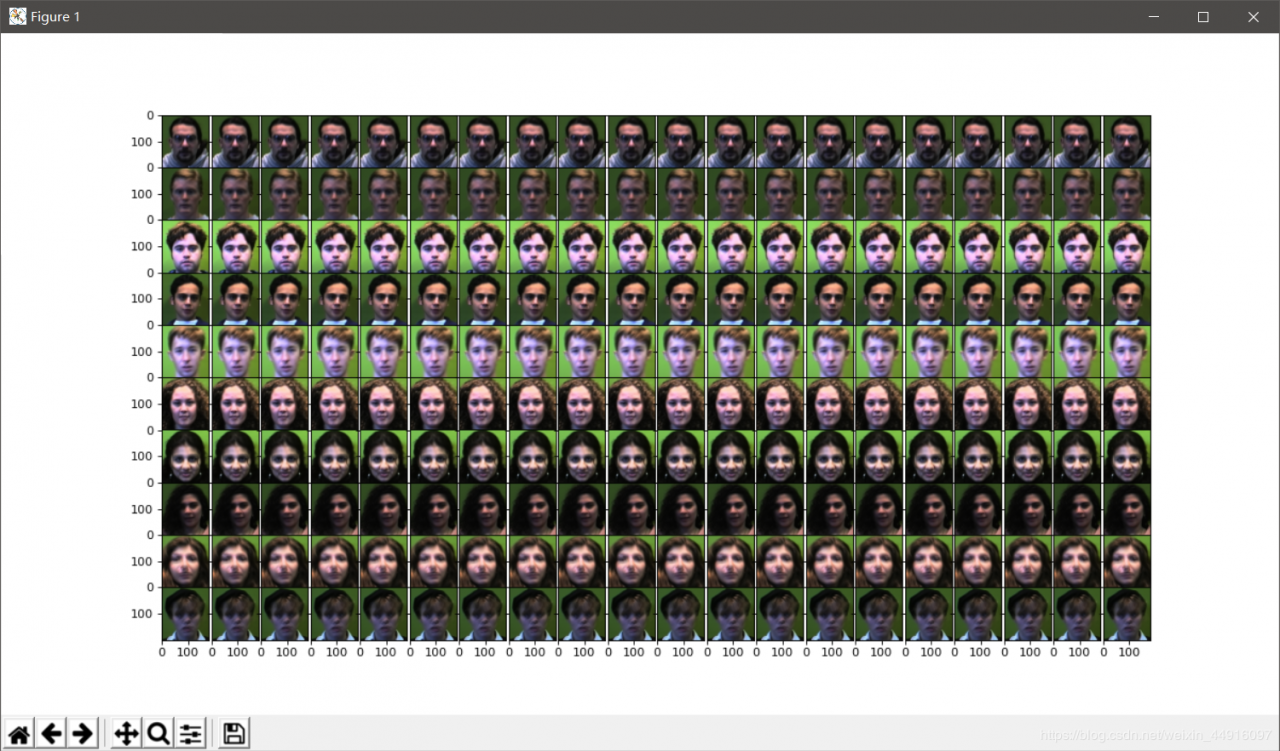
效果图(就这,也跑了十几秒T∩T)
![]()
2、直接放代码吧,PCA理论分析比较难,但用起来挺简单的,学着别人的例子用改改参数就行了(Python真香)
参考了Scikit-learn实例之Pca+Svm人脸识别(AT&T数据集)
import matplotlib.pyplot as plt
import os
import cv2 as cv
import numpy as np
from sklearn.decomposition import PCA
path = 'C:/Users/1233/Desktop/Machine Learning/face_images/'
h, w = 200, 180
IMAGE_COLUMN = 20
IMAGE_ROW = 10
def createDatabase(path):
TrainFiles = os.listdir(path)
Train_Number = len(TrainFiles)
train = []
y_sample = []
for k in range(0, Train_Number):
Trainneed = os.listdir(path + '/' + TrainFiles[k])
Trainneednumber = len(Trainneed)
for i in range(0, Trainneednumber):
image = cv.imread(path + '/' + TrainFiles[k] + '/' + Trainneed[i]).astype(np.float32)
image = cv.cvtColor(image, cv.COLOR_RGB2GRAY)
train.append(image)
y_sample.append(k)
train = np.array(train)
y_sample = np.array(y_sample)
return train, y_sample
# n_samples, h, w = 200, 200, 180
X, y = createDatabase(path)
X_ = X.reshape(X.shape[0], h*w)
# 从200张图里挑出特征值前10的特征脸
n_components = 10
pca = PCA(n_components).fit(X_) # svd_solver='randomized', whiten=True
eigenfaces = pca.components_.reshape((n_components, h, w))
# 将输入数据投影到特征面正交基上
X_train_pca = pca.transform(X_)
def plot_gallery(images, titles, h, w, n_row=1, n_col=10):
"""Helper function to plot a gallery of portraits"""
plt.figure(figsize=(1.8 * n_col, 2 * n_row))
plt.subplots_adjust(bottom=0, left=.01, right=.99, top=.90, hspace=.35) # 图片位置布局
for i in range(10):
plt.subplot(n_row, n_col, i + 1)
plt.imshow(images[i].reshape((h, w)))
# plt.imshow(images[i].reshape((h, w)), cmap=plt.cm.gray)
plt.title(titles[i], size=12)
# 把坐标去了
plt.xticks(())
plt.yticks(())
eigenface_titles = ["eigenface %d" % (i+1) for i in range(eigenfaces.shape[0])]
plot_gallery(eigenfaces, eigenface_titles, h, w)
plt.show()
效果图

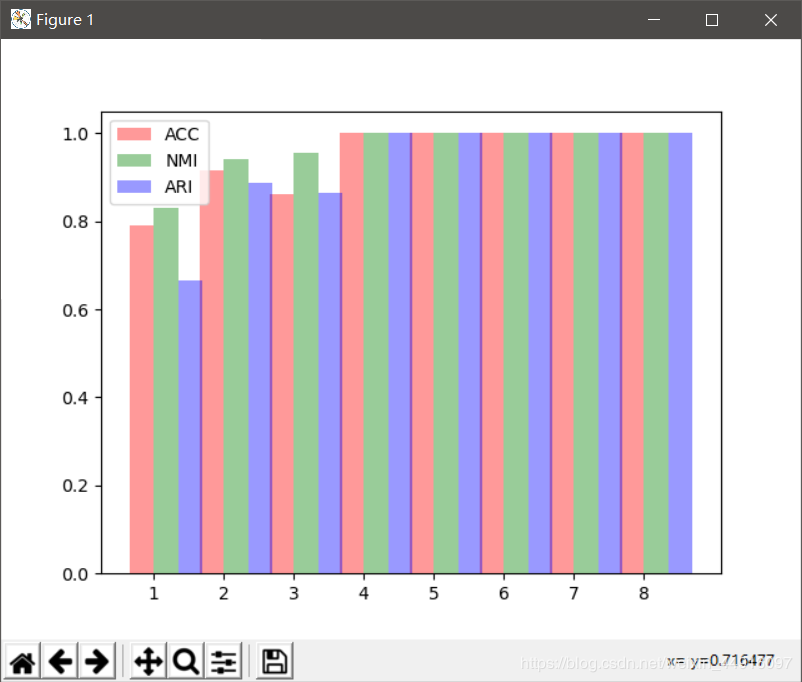
3、循环聚类下画个图就OK了
import matplotlib.pyplot as plt
import os
import cv2 as cv
import numpy as np
from sklearn.cluster import KMeans
from sklearn.decomposition import PCA
from PIL import Image
from ML_clustering_performance import clusteringMetrics
path = 'C:/Users/1233/Desktop/Machine Learning/face_images/'
h, w = 200, 180
IMAGE_COLUMN = 20
IMAGE_ROW = 10
def createDatabase(path):
TrainFiles = os.listdir(path)
Train_Number = len(TrainFiles)
train = []
y_sample = []
for k in range(0, Train_Number):
Trainneed = os.listdir(path + '/' + TrainFiles[k])
Trainneednumber = len(Trainneed)
for i in range(0, Trainneednumber):
img = Image.open(path + '/' + TrainFiles[k] + '/' + Trainneed[i])
image = cv.imread(path + '/' + TrainFiles[k] + '/' + Trainneed[i]).astype(np.float32)
image = cv.cvtColor(image, cv.COLOR_RGB2GRAY)
train.append(image)
y_sample.append(k)
train = np.array(train)
y_sample = np.array(y_sample)
return train, y_sample
# n_samples, h, w = 200, 200, 180
X, y = createDatabase(path)
X_ = X.reshape(X.shape[0], h*w)
n_components = 10
ACCS = []
NMIS = []
ARIS = []
for i in range(1, 9):
n_components = i
pca = PCA(n_components=n_components).fit(X_) # svd_solver='randomized', whiten=True
eigenfaces = pca.components_.reshape((n_components, h, w))
# 将输入数据投影到特征面正交基上
X_train_pca = pca.transform(X_)
# 聚类
kms = KMeans(n_clusters=10)
y_sample = kms.fit_predict(X_train_pca, y)
ACC, NMI, ARI = clusteringMetrics(y, y_sample)
ACCS.append(ACC)
NMIS.append(NMI)
ARIS.append(ARI)
fig, ax = plt.subplots()
bar_width = 0.35
opacity = 0.4 # 不透明度
index = np.arange(8)
# error_config = {'ecolor': '0.3'}
rects1 = ax.bar(index, ACCS, bar_width, alpha=opacity, color='r', label='ACC') # error_kw=error_config
rects2 = ax.bar(index + bar_width, NMIS, bar_width, alpha=opacity, color='g', label='NMI')
rects3 = ax.bar(index + 2*bar_width, ARIS, bar_width, alpha=opacity, color='b', label='ARI')
ax.set_xticks(index + bar_width / 2)
ax.set_xticklabels(('1', '2', '3', '4', '5', '6', '7', '8'))
ax.legend()
plt.show()
效果图
作者:绍少阿