中国大学排名定向爬虫实例
功能描述:
#第一个大学
... ... ... .......
#第N个大学
... ... ... .......
爬虫代码:


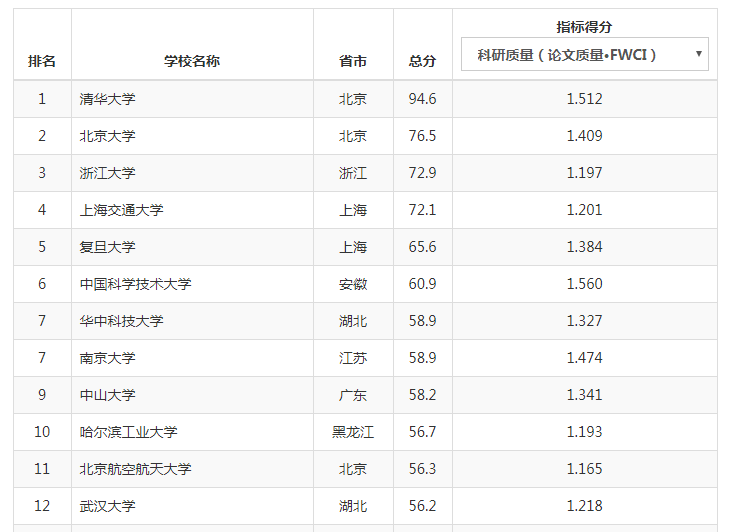
.......
.......
import requests
from bs4 import BeautifulSoup
import bs4
def getHTMLText(url): #输入url,返回HTML
try:
r=requests.get(url,timeout=30)
r.raise_for_status()
r.encoding=r.apparent_encoding
return r.text
except :
return "爬取失败"
def fillUnivList(ulist,html): #将HTML页面放到ulist列表中
soup=BeautifulSoup(html,"html.parser")
for tr in soup.find('tbody').children:
if isinstance(tr,bs4.element.Tag): #将tr不是Tag的标签过滤
tds=tr('td') #查tr中的td标签
ulist.append([tds[0].string,tds[1].string,tds[2].string,tds[3].string])
def printUnivList(ulist,num): #将ulist信息打印出来,num为个数
print("{:^10}\t{:^6}\t{:^6}\t{:^10}".format("排名","学校名称","省市","总分")) #打印表头
for i in range(num):
u=ulist[i]
print("{:^10}\t{:^6}\t{:^6}\t{:^10}".format(u[0],u[1],u[2],u[3]))
if __name__=="__main__":
uinfo=[]
url="http://www.zuihaodaxue.cn/zuihaodaxuepaiming2019.html"
html=getHTMLText(url)
fillUnivList(uinfo,html)
printUnivList(uinfo,20) #20个学校的信息
爬取结果:
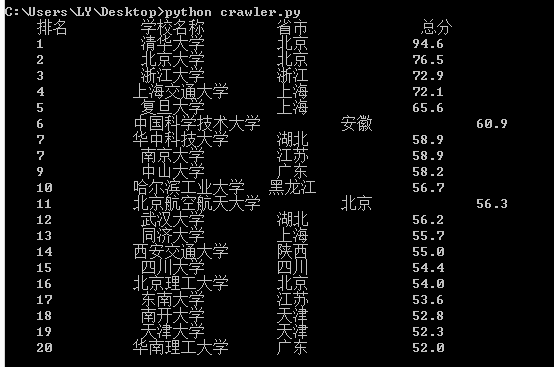
输出格式优化:
上述爬取结果可以看出格式不是很好对齐,进行优化
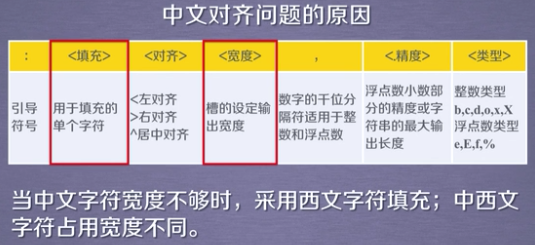

原代码:
def printUnivList(ulist,num): #将ulist信息打印出来,num为个数
print("{:^10}\t{:^6}\t{:^6}\t{:^10}".format("排名","学校名称","省市","总分")) #打印表头
for i in range(num):
u=ulist[i]
print("{:^10}\t{:^6}\t{:^6}\t{:^10}".format(u[0],u[1],u[2],u[3]))
优化后代码:
def printUnivList(ulist,num): #将ulist信息打印出来,num为个数
tplt="{0:^10}\t{1:{4}^10}\t{2:^6}\t{3:^10}" #{1:{4}^10}中的{4}表示用format格式中的4(即第五个)参数:chr(12288)
print(tplt.format("排名","学校名称","省市","总分",chr(12288))) #打印表头
for i in range(num):
u=ulist[i]
print(tplt.format(u[0],u[1],u[2],u[3],chr(12288)))
优化后的结果:
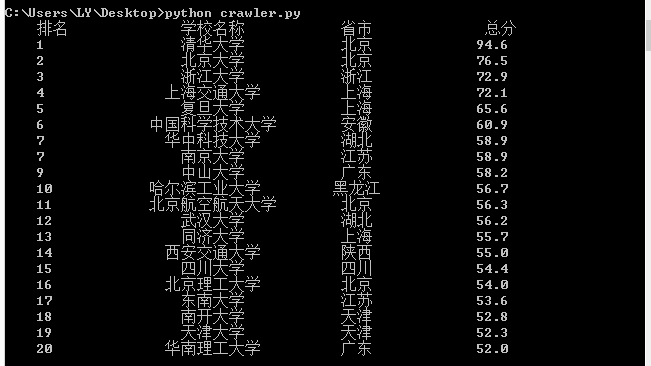
作者:LY_624
相关文章
Vanna
2021-01-09
Rosalba
2020-03-05
Flower
2020-11-13
Faye
2022-10-23
Roselani
2022-10-23
Beth
2022-10-23
Tricia
2022-10-23
Fiorenza
2022-10-23
Hazel
2022-10-23
Nancy
2022-10-23
Bonita
2022-10-23
Veronica
2022-10-23
Liana
2022-10-23
Jenna
2022-10-23
Bambi
2022-11-07
Rhea
2023-02-26
Tricia
2023-04-30
Tallulah
2023-05-12