深度学习之图像分类----多分类支持向量机(Multi-SVM)与softmax分类
本文学习自该大V
概述:
由于KNN算法的局限性,我们需要实现更强大的方法来实现图像分类,一般情况下该方法包含两个函数,一是评分函数(score function),它是原始图像到每个分类的分值映射,二是损失函数(loss function),它是用来量化预测分类标签的得分与真实标签的一致性的。该方法可以转化为一个最优化问题,在最优化过程中,将通过更新评分函数的参数来最小化损失函数的值,从而使得我们找到一个更好的评分函数(参数W)。
评分函数将图像的像素值映射为各个类别的得分,得分越高说明越有可能属于该类别。
我们定义一个简单的函数映射:$ f(x_i,W,b) = Wx_i + b $
参数W被称为权重(weights)。b被称为偏差向量(biasvector),这是因为它影响输出数值,但是并不和原始数据xi产生关联。每个输入图像xi经过该评分映射后会得到一个[K×1]的矩阵,每一个表示该图像在该分类中的得分,即可能是该分类的可能性参数W被称为权重(weights)。b被称为偏差向量(bias vector),这是因为它影响输出数值,但是并不和原始数据x_i产生关联。每个输入图像x_i经过该评分映射后会得到一个[K × 1 ]的矩阵,每一个表示该图像在该分类中的得分,即可能是该分类的可能性参数W被称为权重(weights)。b被称为偏差向量(biasvector),这是因为它影响输出数值,但是并不和原始数据xi产生关联。每个输入图像xi经过该评分映射后会得到一个[K×1]的矩阵,每一个表示该图像在该分类中的得分,即可能是该分类的可能性
需要注意的几点:
1.该方法的一个优势是训练数据是用来学习到参数W和b的,一旦训练完成,训练数据就可以丢弃,留下学习到的参数即可。这是因为一个测试图像可以简单地输入函数,并基于计算出的分类分值来进行分类。
2.输入数据(xi,yi)(x_i,y_i)(xi,yi)是给定不变的,我们的目的是通过设置权重W和偏差值b,使得计算出来的分类分值情况和训练集中图像的数据真实类别标签相符合

一个将图像映射到分类分值的例子。为了便于可视化,假设图像只有4个像素(都是黑白像素,这里不考虑RGB通道),有3个分类(红色代表猫,绿色代表狗,蓝色代表船,注意,这里的红、绿和蓝3种颜色仅代表分类,和RGB通道没有关系)。首先将图像像素拉伸为一个列向量,与W进行矩阵乘,然后得到各个分类的分值。需要注意的是,这个W一点也不好:猫分类的分值非常低。从上图来看,算法倒是觉得这个图像是一只狗。
偏差和权重的合并技巧:
在进一步学习前,要提一下这个经常使用的技巧。它能够将我们常用的参数W和b合二为一。回忆一下,分类评分函数定义为:
$f(x_i,W,b) = Wx_i + b $
分开处理这两个参数(权重参数W和偏差参数b)有点笨拙,一般常用的方法是把两个参数放到同一个矩阵中,同时x_i向量就要增加一个维度,这个维度的数值是常量1,这就是默认的偏差维度。这样新的公式就简化成下面这样:f(xi,W)=Wxif(x_i,W) = Wx_if(xi,W)=Wxi
还是以CIFAR-10为例,那么x_i的大小就变成[3073x1],而不是[3072x1]了,多出了包含常量1的1个维度)。W大小就是[10x3073]了。W中多出来的这一列对应的就是偏差值b,具体见下图:
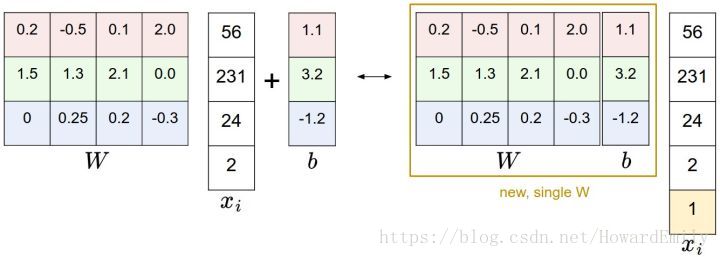
偏差技巧的示意图。左边是先做矩阵乘法然后做加法,右边是将所有输入向量的维度增加1个含常量1的维度,并且在权重矩阵中增加一个偏差列,最后做一个矩阵乘法即可。左右是等价的。通过右边这样做,我们就只需要学习一个权重矩阵,而不用去学习两个分别装着权重和偏差的矩阵了.
损失函数假设对于输入的一个图片,我们通过评分函数计算出它对于每一个分类的得分,那么怎么去评价他的好坏呢?这时候我们需要使用损失函数来衡量我们对该评分的满意程度。我们可以通过调整参数W来使得评分函数的结果(最高分所在类别)与训练集真实标签是一致的。一般来说,评分函数输出结果与真实结果差别越大,损失函数值越大,反之越小。
多分类支持向量机(multi-SVM)的损失函数
我们定义其损失函数为 对于第i个输入数据
$ L_i = \sum_{j \ne y_i} max(0,s_j - s_{y_i} + \Delta)$
我们这里定义每一类的得分为s,sjs_jsj即为对于第i个输入数据经过评分函数后在第j个分类的得分,syis_{y_i}syi表示对于第i个输入数据经过评分函数,在正确分类处的得分。Δ\DeltaΔ 这里是一个边界值,具体的意思就是,Multi-SVM 我不关心正确的分类得分,我关心的是对于我在正确分类处所得的分数,是否比我在错误分类处所得的分数高,而且要出一定边界值$\Delta ,如果高于,如果高于,如果高于\Delta$ 那么我便不管它,否则我就需要计算我的损失
举例:
用一个例子演示公式是如何计算的。假设有3个分类,并且得到了分值s=[13,-7,11]。其中第一个类别是正确类别,即yi=0y_i = 0yi=0同时设Δ=10\Delta = 10Δ=10 上面的公式是将所有不正确分类(j≠yi)(j\not=y_i)(j=yi)加起来,所以我们得到两个部分:
Li=max(0,−7−13+10)+max(0,11−13+10)L_i = max(0,-7-13+10) + max(0,11-13+10)Li=max(0,−7−13+10)+max(0,11−13+10)
可以看到第一个部分结果是0,这是因为[-7-13+10]得到的是负数,经过max(0,-)函数处理后得到0。这一对类别分数和标签的损失值是0,这是因为正确分类的得分13与错误分类的得分-7的差为20,高于边界值10。而SVM只关心差距至少要大于10,更大的差值还是算作损失值为0。第二个部分计算[11-13+10]得到8。虽然正确分类的得分比不正确分类的得分要高(13>11),但是比10的边界值还是小了,分差只有2,这就是为什么损失值等于8。简而言之,SVM的损失函数想要正确分类类别yiy_iyi的分数比不正确类别分数高,而且至少要高Δ\DeltaΔ。如果不满足这点,就开始计算损失值。
还必须提一下的属于是关于0的阀值:max(0,−)max(0,-)max(0,−)函数,它常被称为折叶损失(hinge loss)。有时候会听到人们使用平方折叶损失SVM(即L2-SVM),它使用的是max(0,−)2max(0,-)^2max(0,−)2,将更强烈(平方地而不是线性地)地惩罚过界的边界值。不使用平方是更标准的版本,但是在某些数据集中,平方折叶损失会工作得更好。可以通过交叉验证来决定到底使用哪个。
梯度推导:
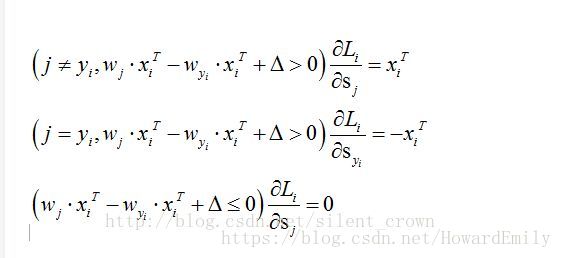
这里需要矩阵求导公式:
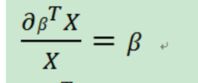
代码实现:
"""
不加入正则化的多分类SVM的损失函数的实现,采用三种方法,一是两层循环,二是一层循环,三是不用循环
"""
import numpy as np
def L_i(x,y,W,reg):
"""
unvectorized version. Compute the multiclass svm loss for a single example (x,y)
- x is a column vector representing an image (e.g. 3073 x 1 in CIFAR-10)
with an appended bias dimension in the 3073-rd position (i.e. bias trick)
- y is an integer giving index of correct class (e.g. between 0 and 9 in CIFAR-10)
- W is the weight matrix (e.g. 10 x 3073 in CIFAR-10)
"""
delta = 1.0 #delta 为1.0 一般是安全的
# f(xi,W) = Wx,x 为 3073 * 1,W = 10 * 3073
scores = np.dot(W,x)
correct_class_score = scores[y]
D = W.shape[0]
loss_i = 0.0
for j in xrange(D):
if j == y: # 对所有错误的分类进行Iterate,j == y 为正确classification,so skip it.
continue
"""
multi SVM 只关注正确评分的损失,即要求正确分类所获得的分数要大于错误分类所获得分数,且至少要大delta,
否则就计算loss.
"""
loos_i += max(0,scores[j] - correct_class_score[y] + delta)
return loss_i
def L_i_vectorized(x,y,W):
"""
A faster half-vectorized implementation. half-vectorized
refers to the fact that for a single example the implementation contains
no for loops, but there is still one loop over the examples (outside this function)
需要一个循环对每个 test 进行call L_i_vectorized.
"""
delta = 1.0
scores = np.dot(W,x) # W = 10 * 3073 , x = 3073 * 1
margins = np.maximum(0,scores - scores[y] + delta) # 矩阵运算
margins[y] = 0
loss_i = np.sum(margins)
return loss_i
def L(X,y,W):
"""
fully-vectorized implementation :
- X holds all the training examples as columns (e.g. 3073 x 50,000 in CIFAR-10)
- y is array of integers specifying correct class (e.g. 50,000-D array)
- W are weights (e.g. 10 x 3073)
不用循环实现,这里可以利用numpy的broadcasting机制.
"""
delta = 1.0
scores = np.dot(W,X)# 10 * 50000
num_train = X.shape[1]
num_class = W.shape[0]
scores_correct = scores[y,np.arange(num_train)] # 1 * 50000
scores_correct = np.reshape(scores_correct,(1,num_train)) # 1 * 50000
# scores is 10 * 50000, broadcasting makes scores_correct to 10 * 50000
margins = scores - scores_correct + delta
margins = np.maximum(margins,0)
margins[y,np.arange(num_train)] = 0 # 正确分类不计算
loss_i = np.sum(margins)
return loss_i
"""
我们有评分函数为 F = WX. 怎么求W呢?还是使用gradient descent.初始给W随机比较小的值,
如: {
生成一个很小的SVM随机权重矩阵
真的很小,先标准正态随机然后乘0.0001
}
W = np.random.randn(3073, 10) * 0.0001
一边计算损失函数,一遍计算W的梯度dW,对于损失函数loss关于W的偏导数,我们这里还是使用了矩阵求导公式
"""
def svm_loss_naive(W,X,y,lamda):
"""
使用循环实现的SVM loss 函数。
输入维数为D,有C类,我们使用N个样本作为一批输入。
输入:
-W: 一个numpy array,形状为 (D, C) ,存储权重。
-X: 一个numpy array, 形状为 (N, D),存储一个小批数据。
-y: 一个numpy array,形状为 (N,), 存储训练标签。y[i]=c 表示 x[i]的标签为c,其中 0 <= c 0:
loss += margin
dW[:,y[i]] += -X[i,:].T
dW[:,j] += X[i,:].T
dW /= num_train
loss /= num_trian # 获得损失函数的均值
dW += lamda * W # 梯度要加入正则化部分
return loss,dW
"""
偶尔会出现梯度验证时候,某个维度不一致,导致不一致的原因是什么呢?这是我们要考虑的一个因素么?梯度验证失败的简单例子是?
提示:SVM 损失函数没有被严格证明是可导的.
可以看上面的输出结果,turn on reg前有一个是3.954297e-03的loss明显变大.
参考答案
解析解和数值解的区别,数值解是用前后2个很小的随机尺度(比如0.00001)进行计算,当Loss不可导的,两者会出现差异。比如SyiSyi刚好比SjSj大1.
"""
def svm_vectorized(W,X,y,lamda):
"""
使用向量来实现
"""
delta = 1.0
loss = 0.0
dW = np.zeros(W.shape)
scores = np.dot(X,W) # num_train * num_class
num_class = W.shape[1]
num_train = X.shape[0]
scores_correct = scores[np.arange(num_train),y] # 1 * num_train
scores_correct = np.reshape(scores_correct,(num_train,-1)) # num_train * 1
margins = scores - scores_correct + delta
margins = np.maximum(0,margis)
margins[np.arange(num_train),y] = 0
loss += np.sum(margins) / num_train
loss += 0.5 * lamda * np.sum(W * W)
"""
使用向量计算SVM损失函数的梯度,把结果保存在dW
"""
margins[margins > 0] = 1
row_sum = np.sum(margins,axis = 1)
margins[np.arange(num_train),y] = -row_sum # 1 by N
dW += np.dot(X.T,margins) / num_train + lamda * W
return loss , dW
"""
上面的代码都是来计算损失函数的,现在我们采用SGD(随机梯度下降)来最小化损失函数
"""
def train_SGD(self,X,y,alpha = 1e-3,lamda = 1e-5,numIterations = 1000,batch_size = 200,verbose = False):
"""
Train this linear classifier using stochastic gradient descent.
使用随机梯度下降来训练这个分类器。
输入:
-X:一个 numpy array,形状为 (N, D), 存储训练数据。 共N个训练数据, 每个训练数据是N维的。
-Y:一个 numpy array, 形状为(N,), 存储训练数据的标签。y[i]=c 表示 x[i]的标签为c,其中 0 <= c <= C 。
-learning rate: float, 优化的学习率。
-reg:float, 正则化强度。
-num_iters: integer, 优化时训练的步数。
-batch_size: integer, 每一步使用的训练样本数。
-verbose: boolean,若为真,优化时打印过程。
输出:
一个存储每次训练的损失函数值的list。
"""
num_train ,dim = X.shape
num_class = np.max(y) + 1# 假设y的值是0...K-1,其中K是类别数量
if self.W is None:
# 简易初始化,给W初始化比较小的值
self.W = 0.001 * np.random.randn(dim,num_class)
# 使用随机梯度下降SGD,优化W
loss_history = []
for it in range(numIterations):
x_batch = None
y_batch = None
"""
从训练集中采样batch_size个样本和对应的标签,在这一轮梯度下降中使用。
把数据存储在 X_batch 中,把对应的标签存储在 y_batch 中。
"""
batch_index = np.random.choice(num_train,batch_size)
x_batch = X[batch_index,:]
y_batch = y[batch_index]
# 用随机产生的样本,求损失函数,以及梯度。
loss,gradient = self.svm_vectorized(X,y,W,lamda)
loss_history.append(loss)
# GradientDescent 更新W
self.W = self.W - alpha * gradient
return loss_history
"""
使用验证集去调整超参数(正则化强度lamda,和学习率alpha)
# 使用验证集去调整超参数(正则化强度和学习率),你要尝试各种不同的学习率
# 和正则化强度,如果你认真做,将会在验证集上得到一个分类准确度大约是0.4的结果。
# 设置学习率和正则化强度,多设几个靠谱的,可能会好一点。
# 可以尝试先用较大的步长搜索,再微调。
"""
learning_rates = [2e-7, 0.75e-7,1.5e-7, 1.25e-7, 0.75e-7]
regularization_strengths = [3e4, 3.25e4, 3.5e4, 3.75e4, 4e4,4.25e4, 4.5e4,4.75e4, 5e4]
# 结果是一个词典,将形式为(learning_rate, regularization_strength) 的tuples 和形式为 (training_accuracy, validation_accuracy)的tuples 对应上。准确率就简单地定义为数据集中点被正确分类的比例。
results = {}
best_val = -1 # 出现的正确率最大值
best_svm = None # 达到正确率最大值的svm对象
################################################################################
# 任务: #
# 写下你的code ,通过验证集选择最佳超参数。对于每一个超参数的组合,
# 在训练集训练一个线性svm,在训练集和测试集上计算它的准确度,然后
# 在字典里存储这些值。另外,在 best_val 中存储最好的验证集准确度,
# 在best_svm中存储达到这个最佳值的svm对象。
#
# 提示:当你编写你的验证代码时,你应该使用较小的num_iters。这样SVM的训练模型
# 并不会花费太多的时间去训练。当你确认验证code可以正常运行之后,再用较大的
# num_iters 重跑验证代码。
################################################################################
for rate in learning_rates:
for regular in regularization_strengths:
svm = LinearSVM()
svm.train(X_train, y_train, learning_rate=rate, reg=regular,
num_iters=1000)
y_train_pred = svm.predict(X_train)
accuracy_train = np.mean(y_train == y_train_pred)
y_val_pred = svm.predict(X_val)
accuracy_val = np.mean(y_val == y_val_pred)
results[(rate, regular)]=(accuracy_train, accuracy_val)
if (best_val < accuracy_val):
best_val = accuracy_val
best_svm = svm
################################################################################
# 结束 #
################################################################################
for lr, reg in sorted(results):
train_accuracy, val_accuracy = results[(lr, reg)]
print ('lr %e reg %e train accuracy: %f val accuracy: %f' % (lr, reg, train_accuracy, val_accuracy))
print ('best validation accuracy achieved during cross-validation: %f' % best_val)
"""
随堂练习 2:
描述你的SVM可视化图像,给出一个简单的解释
参考答案:
将学习到的权重可视化,从图像可以看出,权重是用于对原图像进行特征提取的工具,与原图像关系很大。
很朴素的思想,在分类器权重向量上投影最大的向量得分应该最高,训练样本得到的权重向量,
最好的结果就是训练样本提取出来的共性的方向,类似于一种模板或者过滤器。
"""
作者:Statusrank