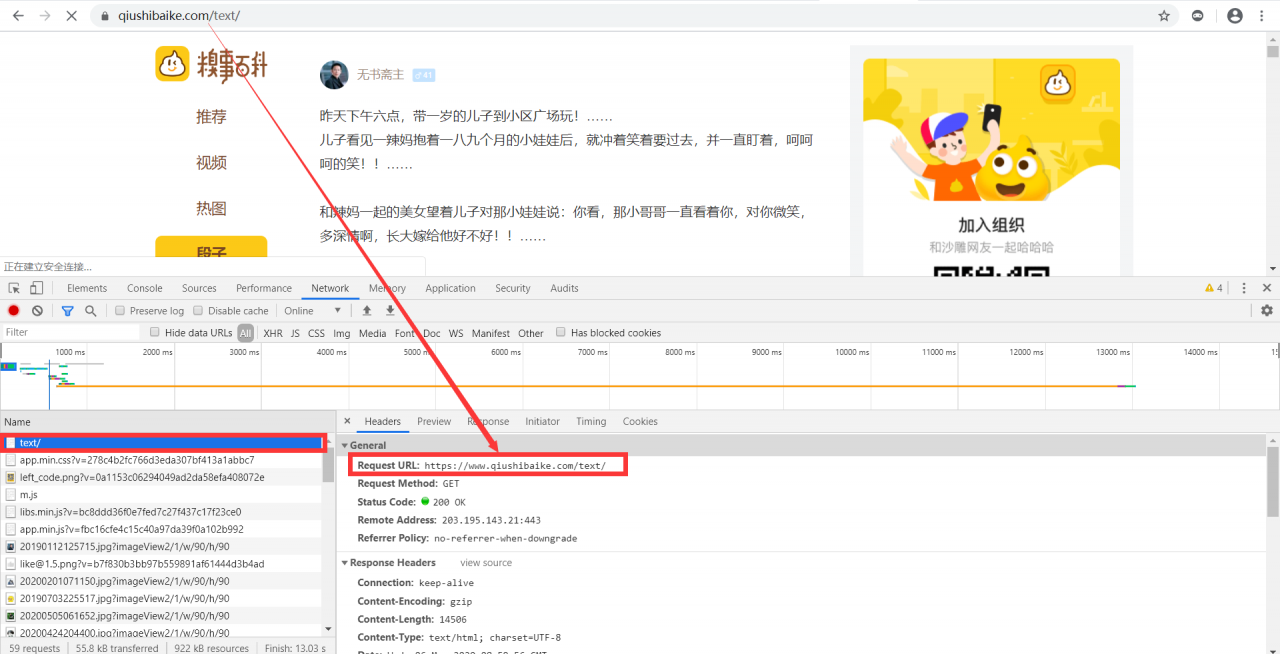
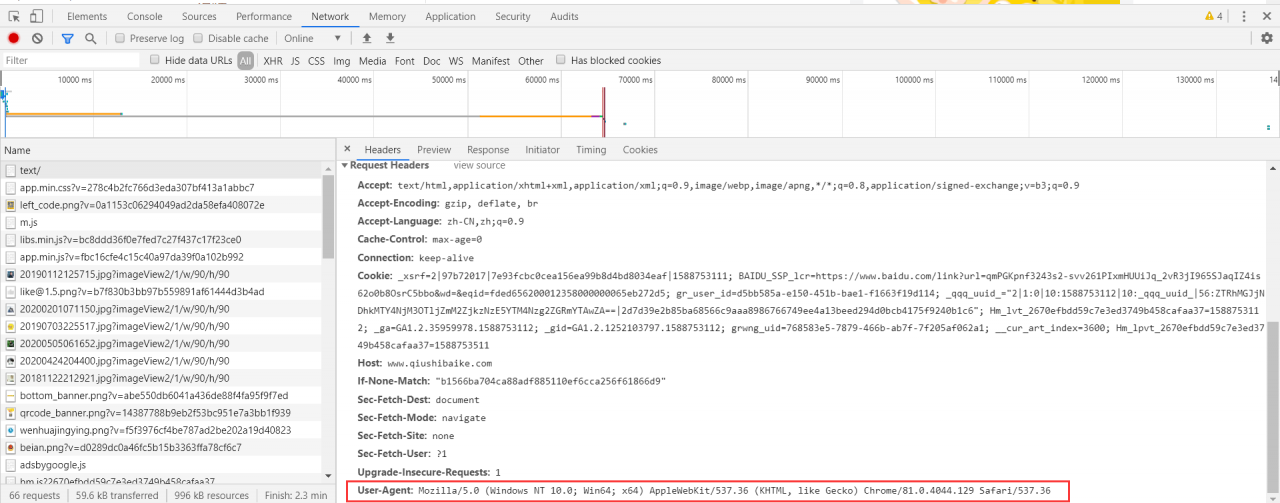
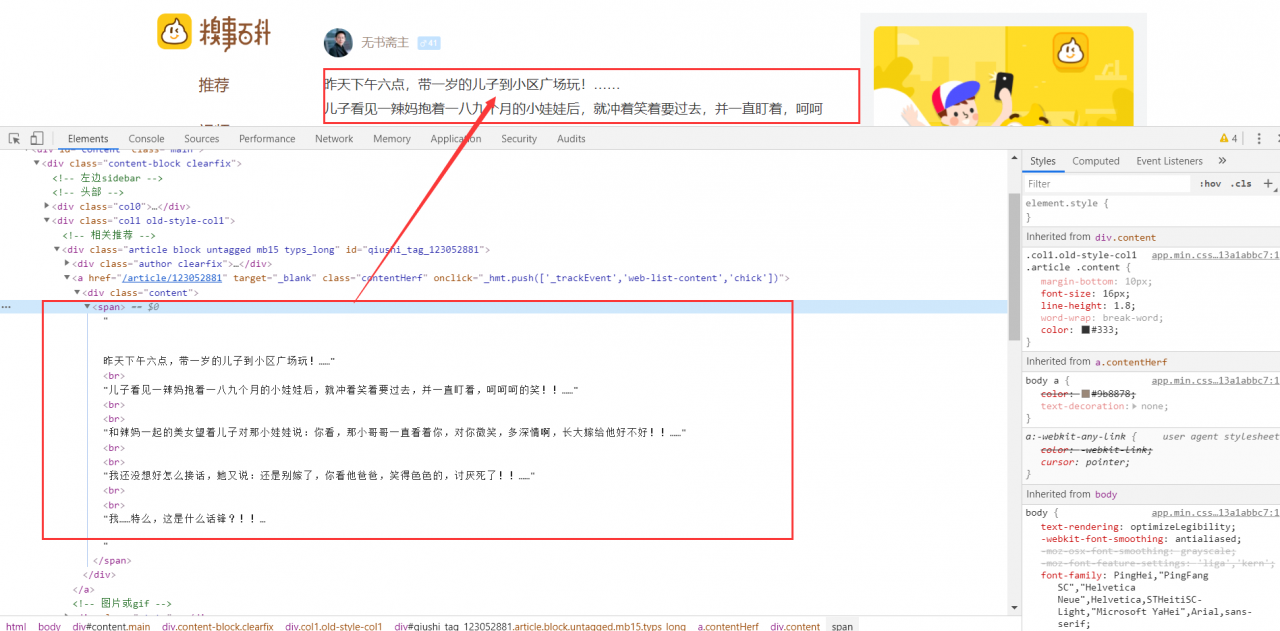
所有完整的代码如下:
import requests
import re
urls = 'https://www.qiushibaike.com/text/page/{}/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36'
}
i = 0
#使用死循环,获取页数
while True:
url = urls.format(i +1)
response = requests.get(url,headers=headers)
info = response.text
# print(info)
infos = re.findall(r'
 还在挣扎的python菜鸟
还在挣扎的python菜鸟
 原创文章 9获赞 0访问量 306
关注
私信
展开阅读全文
原创文章 9获赞 0访问量 306
关注
私信
展开阅读全文