jmeter-正则表达式实例讲解
实例1:从JDBC查询数据,并提取查询结果
实例3(简单):提取单个字符串
实例4(简单):提取多个字符串
实例5(简单):找到所有小数的数字,比如10.2
实例6(简单):找到所有小数点后的数字
实例7(简单):找到第一个有小数的数字
实例8(简单):找到所有小数的数字
正则表达式语法
过年前产假归来,jmeter很多知识生疏了,这两天打开jmeter摸索了几下,老了记不住,还是准备弄个jmeter系列随笔吧。
言归正传,使用jmeter时经常有这样的情况:一个完整的操作流程,需先完成某个操作,获得某个值或数据信息,然后才能进行下一步的操作(也就是常说的关联/将上一个请求的响应结果作为下一个请求的参数); 在jmeter中,利用正则表达式提取器来轻松帮助我们完成这一动作。正则表达式就是用于描述这些规则的工具。换句话说,正则表达式就是记录文本规则的代码。学习正则表达式最好就是从实例下手。下面让我们进入实例。
实例1:从JDBC查询数据,并提取查询结果1、新建线程组并把相关jar放到/lib或/lib/ext目录、添加JDBC Connection Configuration等,此处省略,直接附上截图
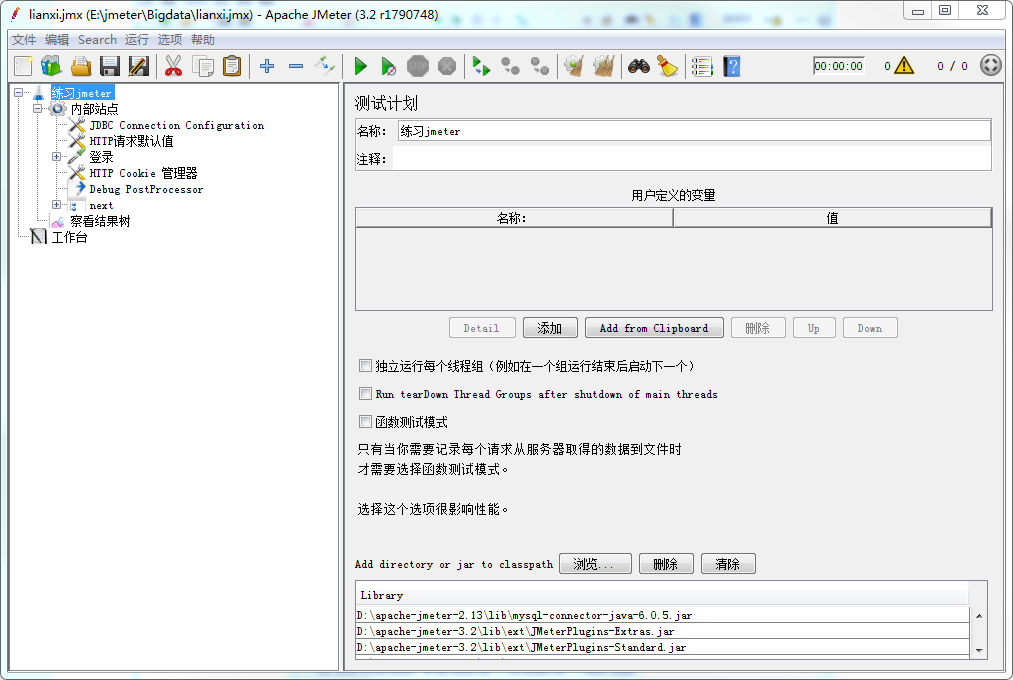


2、添加JDBC Request,Query Type=Select Statement,Varibale name=MySQL。建议在数据库工具执行一次后,在后面察看结果树时做对比,检查是否提取正确。
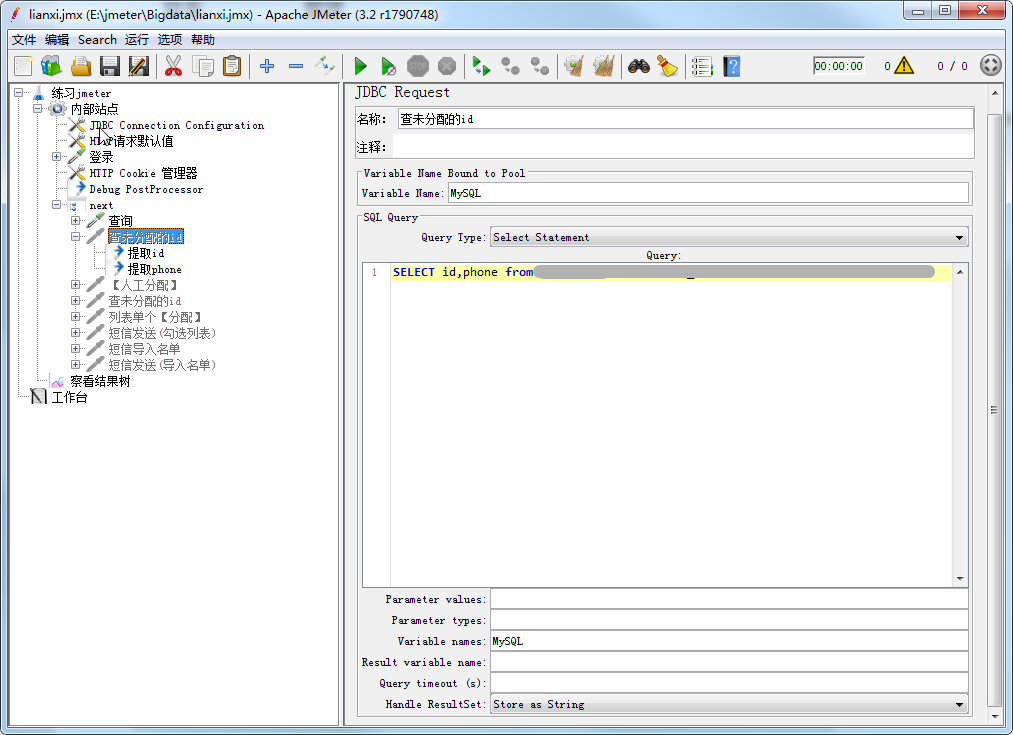
3、在JDBC Request下创建正则表达式提取器,在JDBC Request元件下右击【添加】-【后置处理器】-【正则表达式提取器】即可。本例子查询两列,所以需创建两个正则表达式提取器

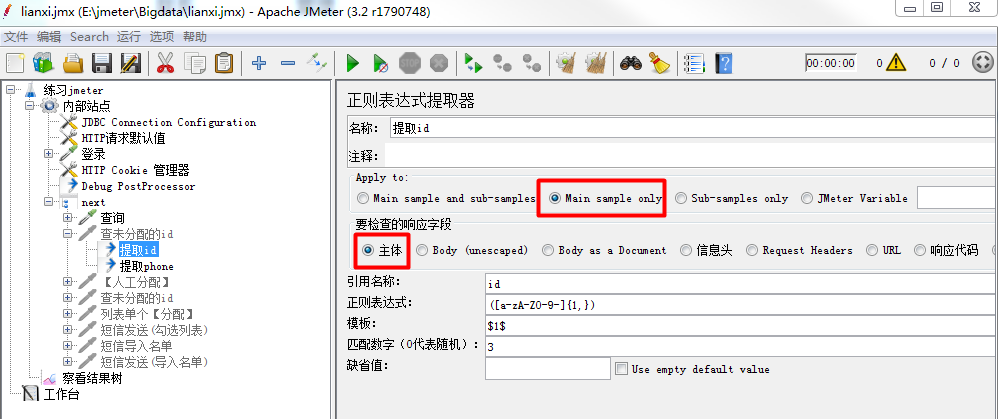
4、配置提取第一列字段,
Apply to通常是Main sample only,
要检查的响应字段视情况选择,在此例选【主体】,
引用名称填id,即下一个请求要引用的参数名称,使用格式${id},注意引用名称命名不要跟线程组内其他变量名称重复
正则表达式,则是本文章重点,这里填([a-zA-Z0-9-]{1,}) ,
():括起来的部分就是要提取的。
.:匹配任何字符串。
+:一次或多次。
?:不要太贪婪,在找到第一个匹配项后停止。
模板,选择第一个匹配的字段,填$1$,用$$引用起来,如果在正则表达式中有多个正则表达式,则可以是$2$$3$等等,表示解析到的第几个值给id。如:$1$表示解析到的第1个值
匹配数字,0代表随机取值,-1表示全部,0随机,1第一个,2第二个,
缺省值如果参数没有取得到值,那默认给一个值让它取。可填可不填,看具体使用场景。
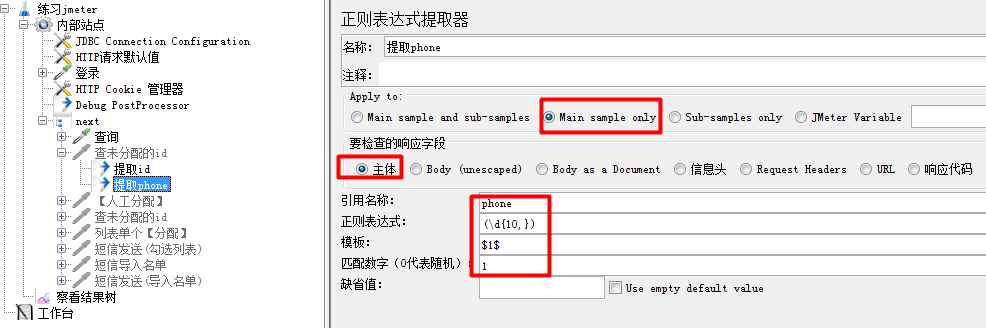
5、配置提取第二列字段
Apply to填Main sample only,
要检查的响应字段选【主体】,
引用名称填phone,后面请求使用变量时格式${phone},
正则表达式,填(\d{10,}) ,
模板,选择第一个匹配的字段,填$1$,
匹配数字,除了0,建议填1,
缺省值不填
6、检查提取器提取结果,有两种方法校验结果。第一种。另外一个,就是不使用请求,。
方法1:添加Debug PostProcessor也可打印所有变量的值,添加即可,然后运行结果

,在察看结果树可以看到提取变量的值是否正确


方法2:引用到下一个请求

实例2:从登录响应请求头提取JSESSIONID
1、继续在实例1的基础上,描述实例2。添加HTTP请求,用于登录

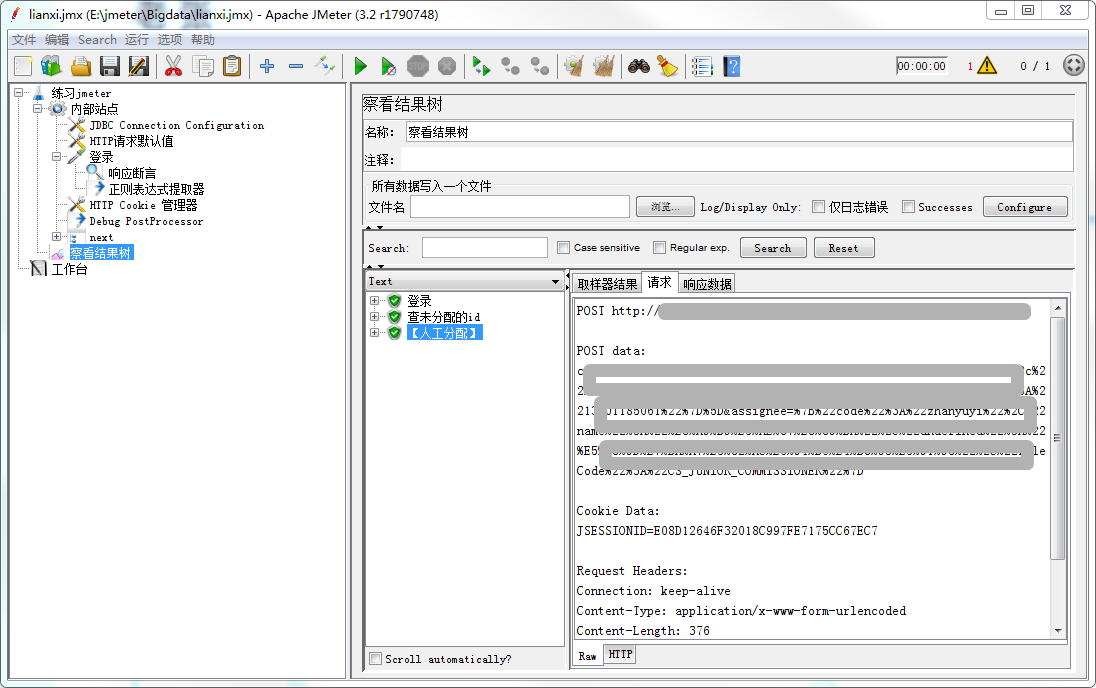
运行一次,在察看结果树看到取样器结果有Set-Cookie: JSESSIONID。

2、在登录HTTP请求元件下右击【添加】-【后置处理器】-【正则表达式提取器】即可。正则表达式填写:(?<=Set-Cookie: JSESSIONID=)\w+\b

3、在线程组内部站点下创建HTTP Cookie管理器,并引用正则表达式提取的引用变量JSESSIONIDw。格式为${JSESSIONIDw}
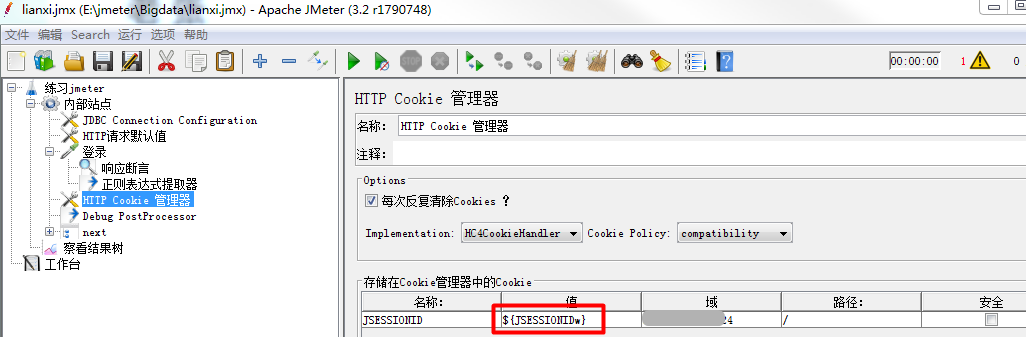
4、运行一次,在察看结果树其他需要登录才能请求的请求检查
例匹配Web页面的如下部分:name = "file" value = "readme.txt">并提取readme.txt。一个合适的正则表达式:name = "file" value = "(.+?)">。
():封装了待返回的匹配字符串。
.:匹配任何单个字符串。
+:一次或多次。
?:不要太贪婪,在找到第一个匹配项后停止。
例匹配Web页面的如下部分:name = "file.name" value = "readme.txt">并提取file.name和readme.txt。一个合适的正则表达式:name = "(.+?)" value = "(.+?)"。这样就会创建2个组,分别用于$1$和$2$
比如:
引用名称:MYREF
模板:$1$$2$
如下变量的值将会被设定:
MYREF: file.namereadme.txt
MYREF_g0: name = "file.name"value = "readme.txt"
MYREF_g1: file.name
MYREF_g2: readme.txt
在需要引用地方可以通过:${MYREF}, ${MYREF_g1}进行使用
实例5(简单):找到所有小数的数字,比如10.2引用名称:aa
正则表达式:([0-9]+\.[0-9]+)
模板:$0$区配数字:-1调用:
${aa_1}:取出第一个满足要求的数字
${aa_2}:取出第二个满足要求的数字
实例6(简单):找到所有小数点后的数字引用名称:aa
正则表达式:([0-9]+)\.([0-9]+),必须用括号分组
模板:$2$(第二组)
区配数字:-1取出所有符合要求的调用:
${aa_1}:取出第一个满足要求的数字
${aa_2}:取出第二个满足要求的数字
实例7(简单):找到第一个有小数的数字引用名称:aa
正则表达式:([0-9]+)\.([0-9]+),必须用括号分组
模板:不写可以,也可以$2$$1$
区配数字:1(第一个)调用:
${aa_g1}:取出满足要求的第一组数字
${aa_g2}:取出满足要求的第二组数字
实例8(简单):找到所有小数的数字引用名称:aa
正则表达式:([0-9]+)\.([0-9]+),必须用括号分组
模板:不写可以,也可以$2$$1$
区配数字:-1取出所有符合要求的调用:
${aa_1_g1}:取出第一个满足要求的第一组数字
${aa_1_g2}:取出第一个满足要求的第二组数字
${aa_2_g1}:取出第一个满足要求的第一组数字
${aa_2_g2}:取出第一个满足要求的第二组数字
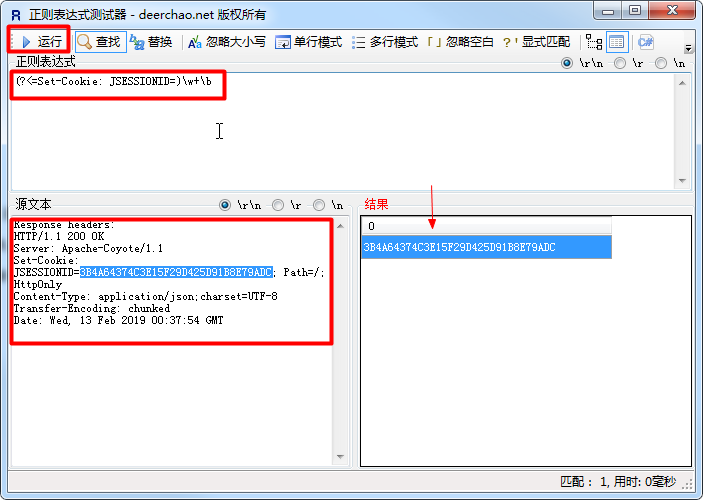
如何检查正则表达式
工具使用Regester检查编写的正则表达式是否正确。可访问deerchao.net下载
jmeter正则表达式提取器参数说明
后置处理器:在请求结束或者返回响应结果时发挥作用。
正则表达式提取器:允许用户从服务器的响应中通过使用perl的正则表达式提取值。该元素会作用在指定范围取样器,用正则表达式提取所需值,生成模板字符串,并将结果存储到给定的变量名中。
APPly to:作用范围(返回内容的断言范围)
Main sample and sub-samples:作用于父节点的取样器及对应子节点的取样器
Main sample only:仅作用于父节点的取样器
Sub-samples only:仅作用于子节点的取样器
JMeter Variable:作用于jmeter变量(输入框内可输入jmeter的变量名称)
要检查的响应字段ResponseFieldtocheck:需检查的响应报文的范围
Body:主体,响应报文的主体,一个网页页面的内容,除了信息头以外的内容
Body(unescaped):主体,响应的主体内容且替换了所有的html转义符,注意html转义符处理时不考虑上下文,因此可能有不正确的转换,不太建议使用
BodyasaDocument:从不同类型的文件中提取文本,注意这个选项比较影响性能
Response Headers:响应信息头
Request Headers:请求信息头
URL:统一资源定位符,即Internet上用来描述信息资源的字符串
Response Code:响应状态码,比如200、404等
Response Message:响应信息
引用名称(ReferenceName):Jmeter变量的名称,存储提取的结果;即下个请求需要引用的值、字段、变量名。每个存储组需要使用共结果时,应使用:[refname]_g#,其中[refname]是你输入的名字,#是组号,0是整个匹配结果,而1是指第一组匹配值
引用方法:${引用名称}
正则表达式(RegularExpression):使用正则表达式解析响应结果,“()”表示提取字符串中的部分值,请不要使用“||”,除非你需要匹配这字符。
下面是常用的正则表达式操作符:

模板(Template):从匹配的结果中创建一个字符串,这是通过正则表达式匹配出来的一组值,意为使用提取到的第几个值(可能有多个值匹配,因此使用模板);从1开始匹配,以此类推。
通过正则表达式匹配出来的一组值,语法为:$1$指代第一组,$2$指代第二组,$0$指代整个匹配结果
参数可以在取值模板组合使用,例如:“11-22”作为模板得到的值是使用“-”连接的第一个待匹配内容与第二个待匹配内容组合而成的字符串。
匹配数字(MatchNo):正则表达式匹配数据的结果可以看做一个数组,表示如何取值:0代表随机取值,正数n则表示取第n个值(比如1代表取第一个值),负数则表示提取所有符合条件的值。一般与ForEach控制器配合使用。
缺省值(DefaultValue):匹配不到数据时,引用变量返回一个默认值,在调试中此功能很有用,如果没有设置默认值,那么很难分辨出正则表达式是否有匹配到数据或使用是否正确,当然也可据测试需求,在调试完成后去掉默认值的设置。通常用于后续的逻辑判断,一般通常为特定含义的英文大写组合,比如:ERROR
正则表达式语法1\bhi\b : 匹配只有hi的字符,\b代表的位置,第一个\b代表单词开始的位置,第二个\b代表单词结束的位置2\bhi\b.*\bthis\b : 匹配hi的字符后,中间有任意个字符后,后面是this的字符3 . : 表示任意字符的元字符,例如Perl正则表达式,r.t匹配这些字符串:rat、rut、rt,但是不匹配root4 *:表示任意数量的元字符,代表的不是字符,也不是位置,而是数量。匹配0或多个正好在它之前的那个字符。例如Perl正则表达式.*意味着能够匹配任意数量的任何字符5 \d : 表示任意一个数字[0-9]6\d+: 匹配一个或更多连续的数字。这里的+是和*类似的元字符,不同的是*匹配重复任意次(可能是0次),而+则匹配重复1次或更多次。7\D: 匹配任意非数字的字符[^0-9] \w:8 \d{2}: 表示任意一个数字出现两次,相当于\d\d9 \s : 匹配任意的空白符,包括空格,换行符,制表符(tab),中文全角空格。即空白 [ \r\t\n\f]10\S: 匹配任意不是空白符的字符。即非空白 [^ \r\t\n\f]11\w : 匹配字母,数字,下划线或汉字。即任意单词字符 [_0-9a-zA-Z]12\W: 匹配任意不是字母,数字,下划线,汉字的字符。即任意非单词字符 [^_0-9a-zA-Z]13\b\w{2}\b : 匹配刚好有两个字符的单词14\b : 匹配单词的开始和结束15^ : 匹配字符串的开始。例如Perl正则表达式^Whenin能够匹配字符串"Wheninthecourseofhumanevents"的开始,但是不能匹配"WhatandWheninthe"16$ : 匹配字符串的结束, 例: ^\d{2,5}$ 表示输入的数字必须是2位(包含)到5位(包含)之间;
例如Perl正则表达式weasel$能够匹配字符串"He'saweasel"的末尾,但是不能匹配字符串"Theyareabunchofweasels."
17\ : 转义字符,如果要查找元字符就需要用转义字符来完成,比如: deerchao\.net 实际上是deerchao.net。
用来将这里列出的这些元字符当作普通的字符来进行匹配。例如Perl正则表达式\$被用来匹配美元符号,而不是行尾,类似的,Perl正则表达式\.用来匹配点字符,而不是任何字符的通配符
18 重复次数说明: *是重复0次或多次,+是重复1次或多次,?是重复零次或一次,{n} 是重复n次,{n,}是重复n次到多次,{n,m}是重复n次到m次19[]、[c1-c2]、[^c1-c2]: 括号里的字符会被匹配,比如[ab]匹配a或b字符,[,?]匹配逗号或问号
例如Perl正则表达式r[aou]t匹配rat、rot和rut,但是不匹配ret。
可以在括号中使用连字符-来指定字符的区间,例如Perl正则表达式[0-9]可以匹配任何数字字符;
还可以制定多个区间,例如Perl正则表达式[A-Za-z]可以匹配任何大小写字母。
另一个重要的用法是“排除”,要想匹配除了指定区间之外的字符——也就是所谓的补集——在左边的括号和第一个字符之间使用^字符,例如Perl正则表达式[^269A-Z]将匹配除了2、6、9和所有大写字母之外的任何字符
20 [a-z0-9A-Z] : 相当于匹配\w
21 | : 匹配或规则,将两个匹配条件进行逻辑“或”(Or)运算。比如: \(0\d{2}\)[- ]?\d{8}|\(0\d{3}\)[- ]\d{7}|0\d{2}[- ]?\d{8}|0\d{3}[- ]?\d{7} 这个就是匹配电话号码的,如:012-56236562, 0536-1234567,(0536)-1234567,01212345678
例如Perl正则表达式(him|her)匹配"itbelongstohim"和"itbelongstoher",但是不能匹配"itbelongstothem."。注意:这个元字符不是所有的软件都支持的
22 ():匹配分组,255.134.123.123 或 193.168.1.1 匹配表达式为:(([01]?\d\d?|25[0-5]|2[0-4]\d)\.){3}([01]?\d\d?|25[0-5]|2[0-4]\d)
23 \B : 匹配不是单词开头或结尾的位置
24 + :匹配1或多个正好在它之前的那个字符。例如Perl正则表达式9+匹配9、99、999、98、93dsf、9.....等。注意:这个元字符不是所有的软件都支持的
25 ? :匹配0或1个正好在它之前的那个字符。注意:这个元字符不是所有的软件都支持的
26 [^x] : 匹配除了x以外的任意字符
27 [^aeiou] : 匹配除了aeiou以外的任意字符
28 (?<word>\w+) 或(?'word'\w+) 后向引用,用于重复搜索前面某个分组已经匹配的文本,引用时就可以写成\k<word>。实际上分组0对应整个正则表达式;组号分配过程是从左到右分配两遍的,第一遍先扫描未命名的分组,第二遍扫描已命名的分组,所以命名分组的组号永远大于未命名分组的组号的; 可以用(?:exp)来剥夺组号分配的参与权
29 分组命名的几种语法: (exp) 匹配exp表达式并将文本匹配的内容自动分配到分组里;
(?<name> exp)匹配exp表达式里的文本内容到name组名下,也可以写成(?'name'exp); (?:exp)匹配exp表达式里内容,但是不捕获匹配的文本也不给匹配的文本分配组号;(?=exp)匹配exp前面的位置; (?<=exp)匹配exp后面的位置 ; (?!exp)匹配后面不是exp的位置 ; (?<!exp) 匹配前面不是exp的位置; (?#comment)添加注释,对正则表达式没有任何影响;
30 (?=exp)与(?<=exp)为零宽断言,其中(?=exp)为零宽度正预测先行断言,(?<=exp)为零宽度正回顾后发断言。(?=exp)表示自exp断言表达式出现的位置开始匹配断言之前的内容,如\b\w+(?=er\b) 源文件为tester,则匹配结果为:test。(?<=exp)表示自exp断言表达式内容结束后的位置开始匹配后面的内容,如(?<=test)\w+\b 源文件为test, 则匹配结果为:er。
31 {i}、{i,}、{i,j}:匹配指定数目的字符,这些字符是在它之前的表达式定义的。例如Perl正则表达式A[0-9]\{3\}能够匹配字符"A"后面跟着正好3个数字字符的串,例如A123、A348等,但是不匹配A1234。Perl正则表达式[0-9]\{4,\}匹配连续的任意4个或4个以上数字字符。Perl正则表达式[0-9]\{4,6\}匹配连续的任意4个、5个或者6个数字字符。注意: 这个元字符不是所有的软件都支持的
32 \ba\w*\b:匹配以字母a开头的单词——先是某个单词开始处(\b),然后是字母a,然后是任意数量的字母或数字(\w*),最后是单词结束处(\b)
更多语法详情可以访问http://deerchao.net/tutorials/regex/regex.htm
到此这篇关于jmeter-正则表达式实例讲解的文章就介绍到这了,更多相关jmeter正则表达式内容请搜索软件开发网以前的文章或继续浏览下面的相关文章希望大家以后多多支持软件开发网!