记录第一次爬虫实验——利用爬有道做一个简易在线翻译器
学习视频来自与小甲鱼——
首先第一步引入python爬取网页常用的两个包
import urllib.request
import urllib.parse
第二步进入有道在线翻译按F12,进入network查看
发现是Get请求。
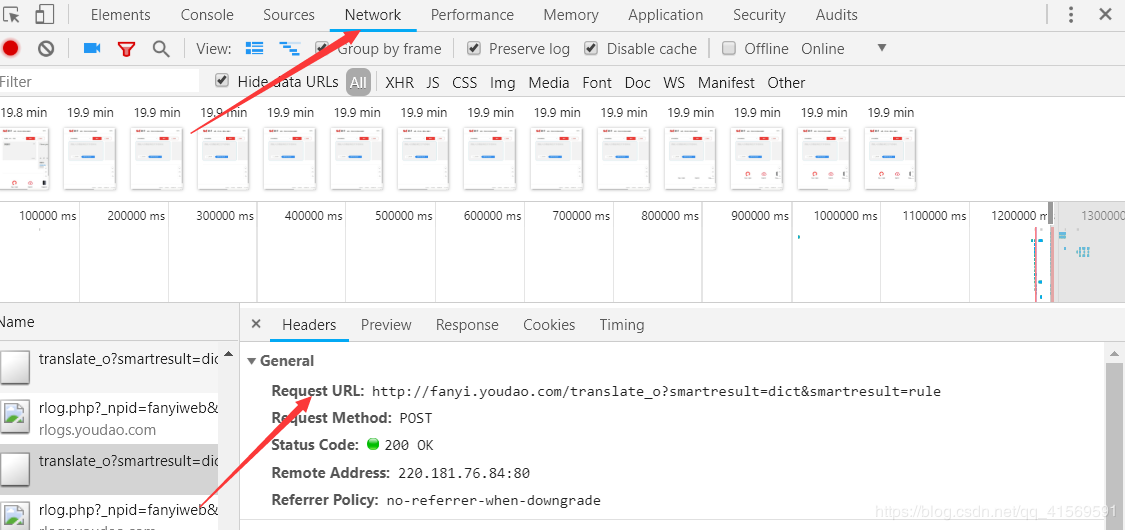
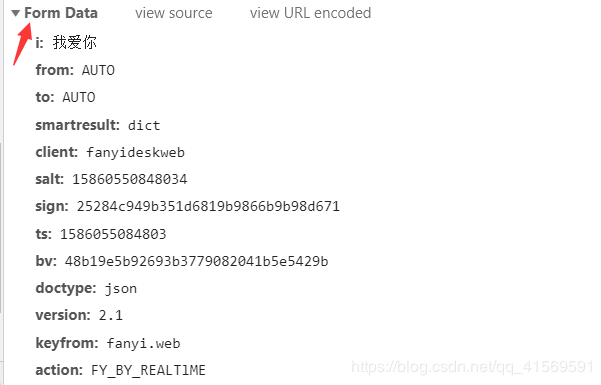
这时候我们就已经拿到了所有需要的数据了。具体实现代码如下
import urllib.request
import urllib.parse
url='http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule '
data={}
data['i']='我爱你'
data['from']='AUTO'
data['to']='AUTO'
data['smartresult']='dict'
data['client']='fanyideskweb'
data['salt']='15860550848034'
data['sign']='25284c949b351d6819b9866b9b98d671'
data['ts']='1586055084803'
data['bv']='48b19e5b92693b3779082041b5e5429b'
data['doctype']='json'
data['version']='2.1'
data['keyfrom']='fanyi.web'
data['action']='FY_BY_REALTlME'
data=urllib.parse.urlencode(data).encode('utf-8')
response=urllib.request.urlopen(url,data)
html=response.read().decode('utf-8')
print(html)
运行后发现error:50
查了一番资料后知道们有道的JS反爬虫代码,完全运行后还需要改你得到的POST请求的URL
我的URL:http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule
需要修改成http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule
需要把_o去掉。
这时候我们在运行一次后就得到了需要的数据了
![]()
我们可以发现我们获得的是一个json格式的值。但是做一个翻译器,这样当然是远远不够的。
我们设置一个target,将json类型解析放在里面,编译知这个是个字典类型的值,获取字典里面的每个键值的value就很容易了
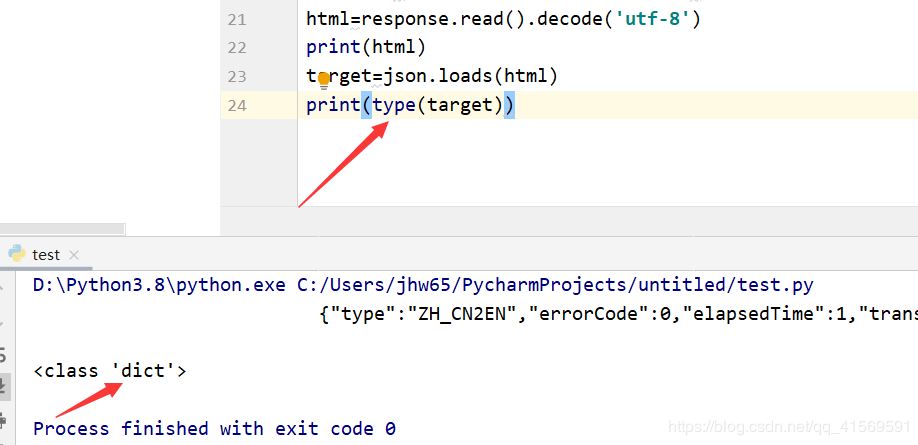
修改后具体实现代码如下:
import urllib.request
import urllib.parse
import json
content=input("请输入需要翻译的内容:")
url='http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule'
data={}
data['i']=content #这里是我们需要转化的中文
data['from']='AUTO'
data['to']='AUTO'
data['smartresult']='dict'
data['client']='fanyideskweb'
data['salt']='15860550848034'
data['sign']='25284c949b351d6819b9866b9b98d671'
data['ts']='1586055084803'
data['bv']='48b19e5b92693b3779082041b5e5429b'
data['doctype']='json'
data['version']='2.1'
data['keyfrom']='fanyi.web'
data['action']='FY_BY_REALTlME'
data=urllib.parse.urlencode(data).encode('utf-8')
response=urllib.request.urlopen(url,data)
html=response.read().decode('utf-8')
target=json.loads(html)
print("翻译结果为:{}".format(target['translateResult'][0][0]["tgt"]))
运行效果图如下:

作者:jhw_12138
相关文章
Irisa
2020-08-22
Angie
2020-10-16
Flower
2020-11-13
Sylvia
2020-02-06
Vidonia
2022-10-17
Gaia
2022-10-23
Faye
2022-10-23
Roselani
2022-10-23
Beth
2022-10-23
Tricia
2022-10-23
Fiorenza
2022-10-23
Hazel
2022-10-23
Nancy
2022-10-23
Bonita
2022-10-23
Liana
2022-10-23
Jenna
2022-10-23
Bambi
2022-11-07