在Python中使用K-Means聚类和PCA主成分分析进行图像压缩
各位读者好,在这片文章中我们尝试使用sklearn库比较k-means聚类算法和主成分分析(PCA)在图像压缩上的实现和结果。 压缩图像的效果通过占用的减少比例以及和原始图像的差异大小来评估。 图像压缩的目的是在保持与原始图像的相似性的同时,使图像占用的空间尽可能地减小,这由图像的差异百分比表示。 图像压缩需要几个Python库,如下所示:
# image processing
from PIL import Image
from io import BytesIO
import webcolors
# data analysis
import math
import numpy as np
import pandas as pd
# visualization
import matplotlib.pyplot as plt
from importlib import reload
from mpl_toolkits import mplot3d
import seaborn as sns
# modeling
from sklearn.cluster import KMeans
from sklearn.decomposition import PCA
from sklearn.preprocessing import MinMaxScaler
探索图像

每个颜色通道的图像
图像中的每个像素都可以表示为三个0到255之间的8位无符号(正)整数,或缩放为三个0到1之间的无符号(正)浮点数。这三个值分别指定红色,绿色,蓝色的强度值,这通常称为RGB编码。 在此文章中,我们使用了220 x 220像素的lena.png,这是在图像处理领域广泛使用的标准测试图像。
ori_img = Image.open("images/lena.png")
ori_img

原始图像
X = np.array(ori_img.getdata())
ori_pixels = X.reshape(*ori_img.size, -1)
ori_pixels.shape
图像储存方式是形状为(220、220、3)的3D矩阵。 前两个值指定图像的宽度和高度,最后一个值指定RBG编码。 让我们确定图像的其他属性,即图像大小(以千字节(KB)为单位)和原色的数量。
def imageByteSize(img):
img_file = BytesIO()
image = Image.fromarray(np.uint8(img))
image.save(img_file, 'png')
return img_file.tell()/1024
ori_img_size = imageByteSize(ori_img)
ori_img_n_colors = len(set(ori_img.getdata()))
lena.png的原始图像大小为86 KB,并具有37270种独特的颜色。 因此,我们可以说lena.png中的两个像素具有相同的精确RGB值的可能性很小。
接下来,让我们计算图像的差异作为压缩结果的基准。
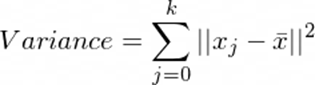
ori_img_total_variance = sum(np.linalg.norm(X - np.mean(X, axis = 0), axis = 1)**2)
我们得到方差为302426700.6427498。 但是我们无法解释方差本身的价值。 我们稍后将在K-Means聚类中使用它。
k-means聚类
具有三个聚类中心的二维k-means聚类图像
算法k-means聚类是一种常用的无监督学习算法,用于将数据集划分为k个聚类中心,其中k必须由用户预先指定。 该算法的目标是将现有数据点分类为几个集群,以便:
同一集群中的数据尽可能相似 来自不同集群的数据尽可能不同每个集群由聚类中心表示,聚类中心是聚类数据点的平均值。 这是算法:
用户指定集群数k 从数据集中随机选择k个不同的点作为初始聚类中心 将每个数据点分配给最近的聚类中心,通常使用欧几里得距离 通过取属于该集群的所有数据点的平均值来计算新聚类中心 重复步骤3和4,直到收敛为止,即聚类中心位置不变请注意,结果可能并不理想,因为它取决于随机的初始化。
理念我们的原始图像包含数千种颜色。 我们将利用K-Means聚类算法来减少颜色数量,因此它仅需要存储一定数量的RGB值。 我们将减小图像尺寸使其更有效率地进行储存。 我们可以将像素值视为具有(宽度×高度)观察值和3个与RGB值相对应的特征的数据帧。 对于lena.png,我们将具有220×220(48400)个观测值和3个特征。
因此,我们可以可视化三维图中的每个像素。 这是前220个像素,代表原始图像中的第一行像素。
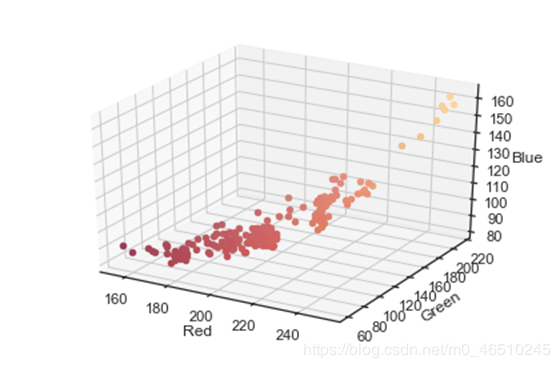
像素值的三维图
在我们对颜色数k使用各种值进行迭代之前,让我们使用k = 2来了解我们的目的。 到本节末,我们希望图像只有2种颜色。 首先,我们创建一个KMeans对象,该对象适合我们的原始像素X。
kmeans = KMeans(n_clusters = 2,
n_jobs = -1,
random_state = 123).fit(X)
kmeans_df = pd.DataFrame(kmeans.cluster_centers_, columns = ['Red', 'Green', 'Blue'])
然后我们将RGB值转换为其英文颜色名称:
def closest_colour(requested_colour):
min_colours = {}
for key, name in webcolors.CSS3_HEX_TO_NAMES.items():
r_c, g_c, b_c = webcolors.hex_to_rgb(key)
rd = (r_c - requested_colour[0]) ** 2
gd = (g_c - requested_colour[1]) ** 2
bd = (b_c - requested_colour[2]) ** 2
min_colours[(rd + gd + bd)] = name
return min_colours[min(min_colours.keys())]
def get_colour_name(requested_colour):
try:
closest_name = actual_name = webcolors.rgb_to_name(requested_colour)
except ValueError:
closest_name = closest_colour(requested_colour)
return closest_name
kmeans_df["Color Name"] = list(map(get_colour_name, np.uint8(kmeans.cluster_centers_)))
kmeans_df
当我们指定2为n_clusters参数值时,我们得到两个聚类中心。下一步,我们可以通过聚类中心来表示该群集中的每个像素值。 因此,在压缩图像中将只有两个像素值。
def replaceWithCentroid(kmeans):
new_pixels = []
for label in kmeans.labels_:
pixel_as_centroid = list(kmeans.cluster_centers_[label])
new_pixels.append(pixel_as_centroid)
new_pixels = np.array(new_pixels).reshape(*ori_img.size, -1)
return new_pixels
new_pixels = replaceWithCentroid(kmeans)
我们的聚类步骤已经完成,让我们看一下压缩图像的结果。
def plotImage(img_array, size):
reload(plt)
plt.imshow(np.array(img_array/255).reshape(*size))
plt.axis('off')
return plt
plotImage(new_pixels, new_pixels.shape).show()

只有两种颜色的压缩图片
K-Means仅使用两种颜色成功地保留了lena.png的形状。 在视觉上,我们可以比较原始图像相似与压缩图像是否相似。 但是,我们如何用程序做到这一点? 让我们介绍一组评估压缩图像的指标:
在群集平方和(WCSS)中,测量群集中所有点与其群集中心的欧几里德距离平方的总和。
在群集的平方和(BCSS)之间,测量所有聚类中心之间的欧几里得距离平方的总和。
解释方差,衡量压缩图像效果可以通过压缩图像解释原始图像的百分比。 如果将每个像素视为一个单独的群集,则WCSS等于0。因此,Exparined Variance = 100%。
图像大小,以千字节为单位,以评估缩小/压缩性能。
def calculateBCSS(X, kmeans):
_, label_counts = np.unique(kmeans.labels_, return_counts = True)
diff_cluster_sq = np.linalg.norm(kmeans.cluster_centers_ - np.mean(X, axis = 0), axis = 1)**2
return sum(label_counts * diff_cluster_sq)
WCSS = kmeans.inertia_
BCSS = calculateBCSS(X, kmeans)
exp_var = 100*BCSS/(WCSS + BCSS)
print("WCSS: {}".format(WCSS))
print("BCSS: {}".format(BCSS))
print("Explained Variance: {:.3f}%".format(exp_var))
print("Image Size: {:.3f} KB".format(imageByteSize(new_pixels)))
WCSS: 109260691.314189
BCSS: 193071692.34763986
Explained Variance: 63.861%
Image Size: 4.384 KB
图像大小从86 KB大幅下降到4.384 KB,但是要注意的是,压缩图像解释原始图像的能力达到63.861%。 我们期望比这更高的解释方差百分比。 接下来,我们将重复上述过程并改变