Python调用百度API实现语音识别(二)

本篇阅读时间约为 5 分钟。
1
前言
上一篇文章里,大致介绍了百度官方 api 的一些前置准备工作。
想回顾的同学,可以看完本篇在下面找到历史链接。
今天就来上手实战编码,体验一下代码实现以及编程中遇到的坑。
2
环境准备
开始之前,安装百度语音 sdk ,Python 版。
pip install baidu-aip
环境很简单,就这一步,完成即可编码。
3
代码撸起
直接拷贝官方提供的代码,就行了,改点参数,上篇文章介绍百度官方申请到的 key 之类的信息自行填入:
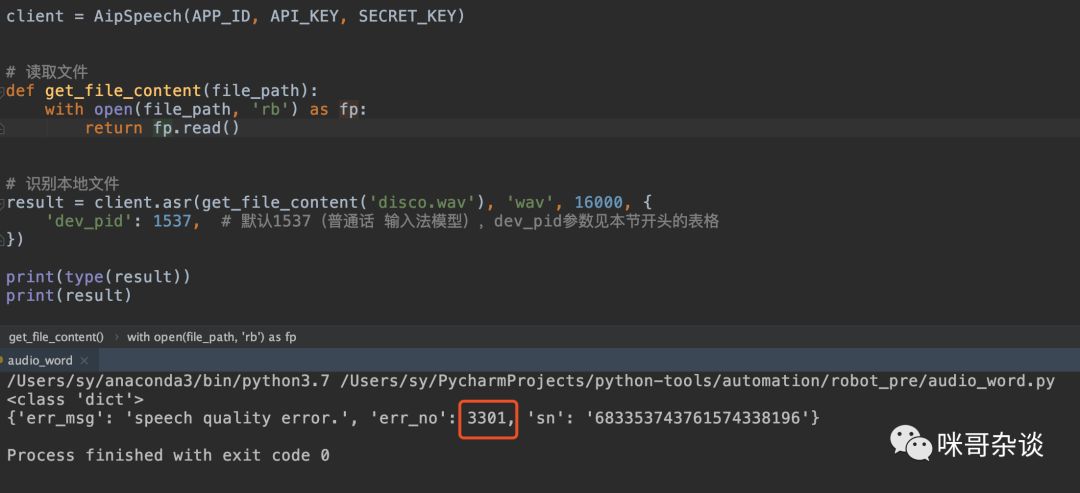
from aip import AipSpeech""" 你的 APPID AK SK """APP_ID = '你的 App ID'API_KEY = '你的 Api Key'SECRET_KEY = '你的 Secret Key'client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)# 读取文件def get_file_content(file_path):with open(file_path, 'rb') as fp:return fp.read()# 识别本地文件result = client.asr(get_file_content('disco.wav'), 'wav', 16000, {'dev_pid': 1537, # 默认1537(普通话 输入法模型),dev_pid参数见本节开头的表格})
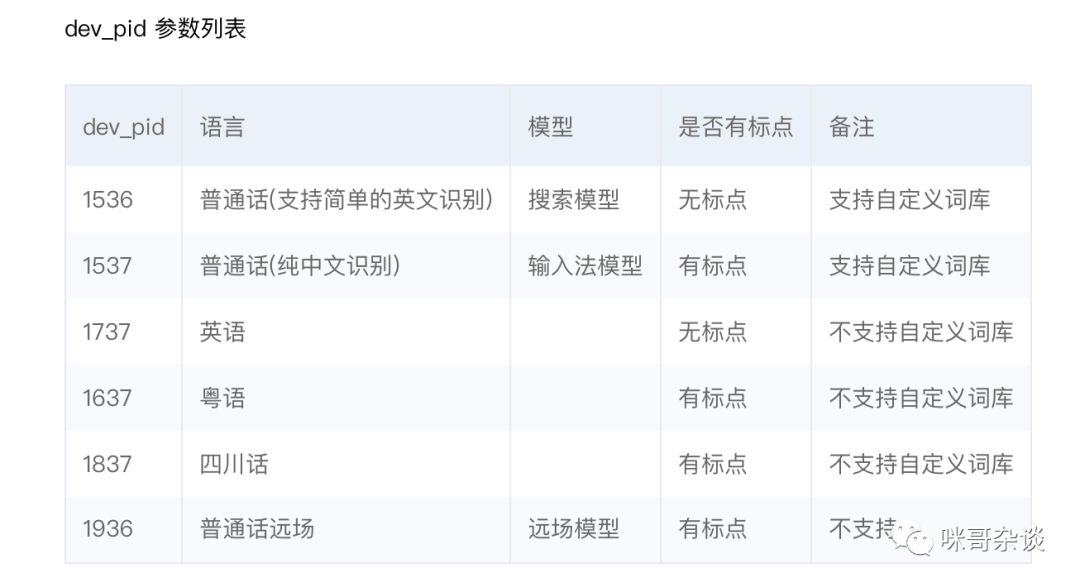
脚本同级目录下,把上次解析的 野狼disco.mp3 改下后缀,变成 wav 格式的,上传。注意下 dev_pid,这里贴出官方参数,用 1537 即可。

2. _requests 函数
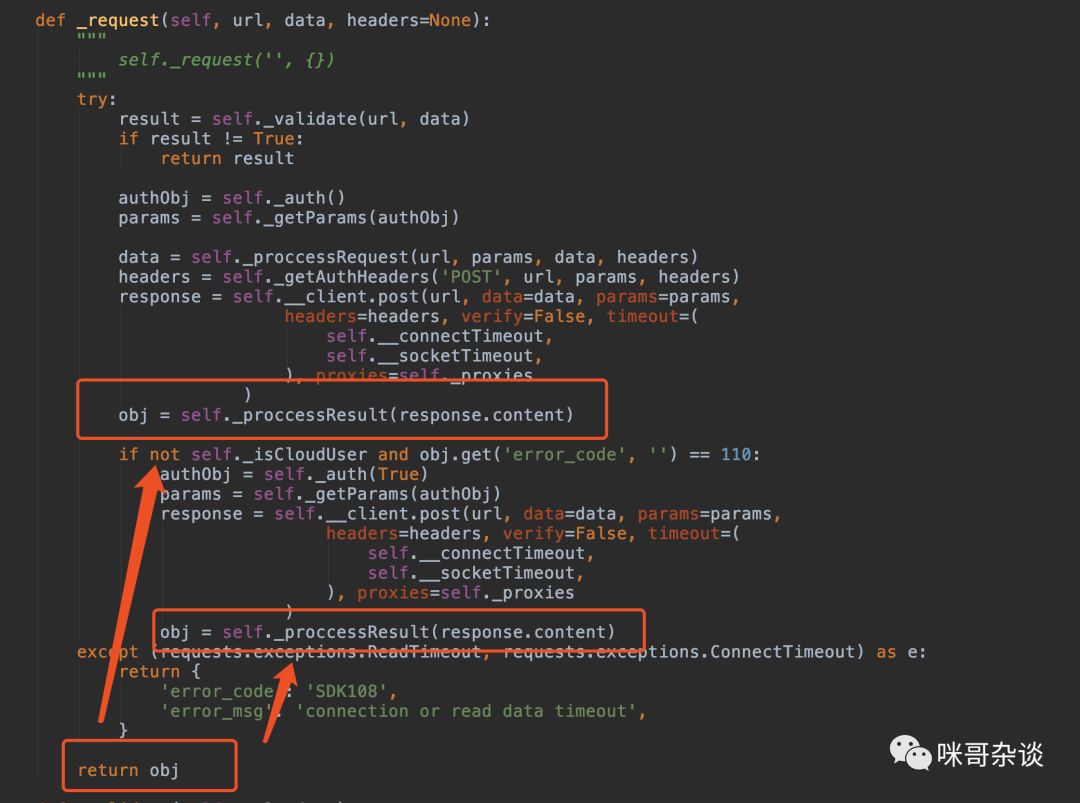
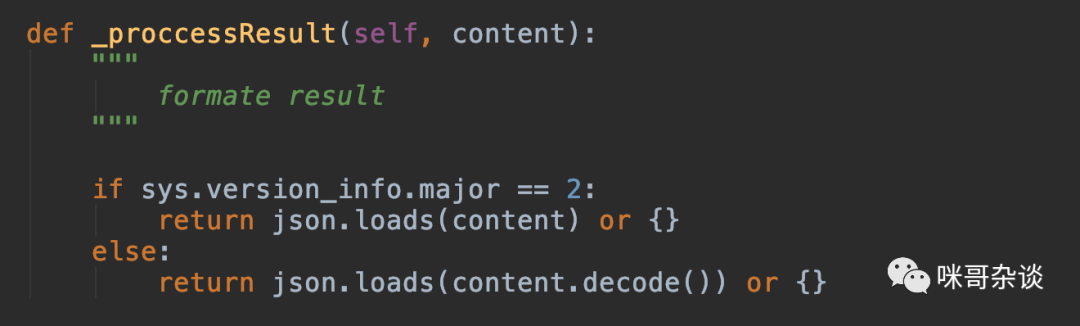
根据 sys.version_info.major 进行不同的 Python 版本号判断,进行不同的 json 解析,如果是 2,则不用对内容进行解码。

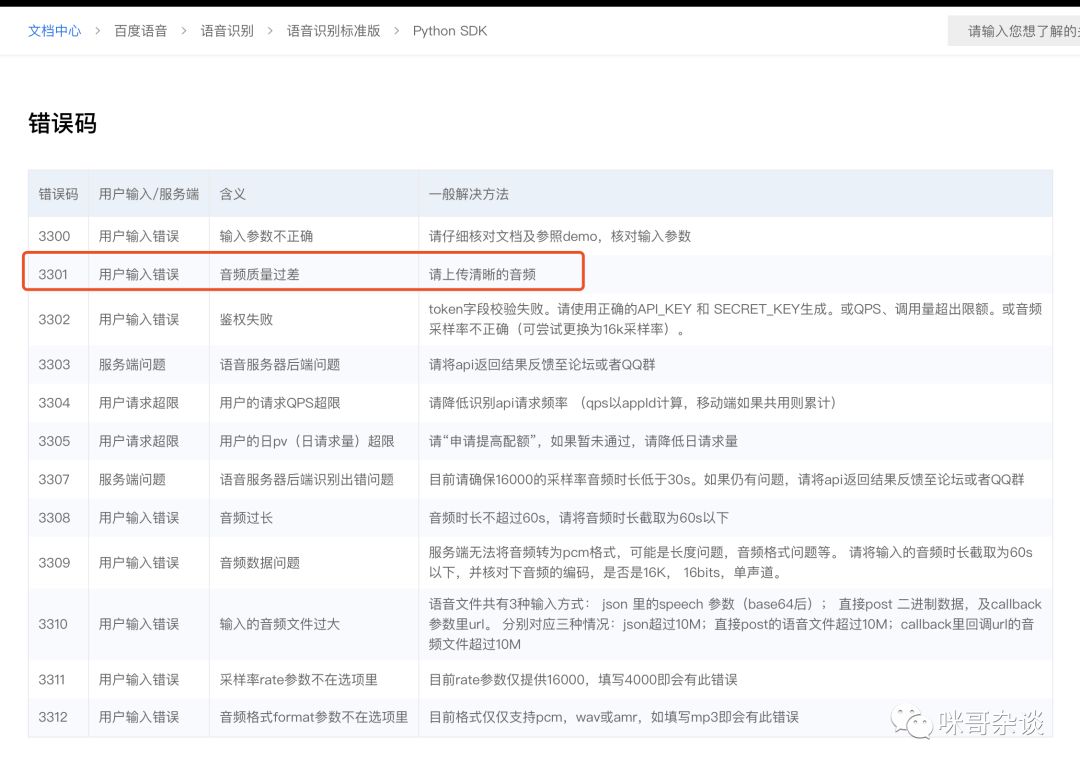

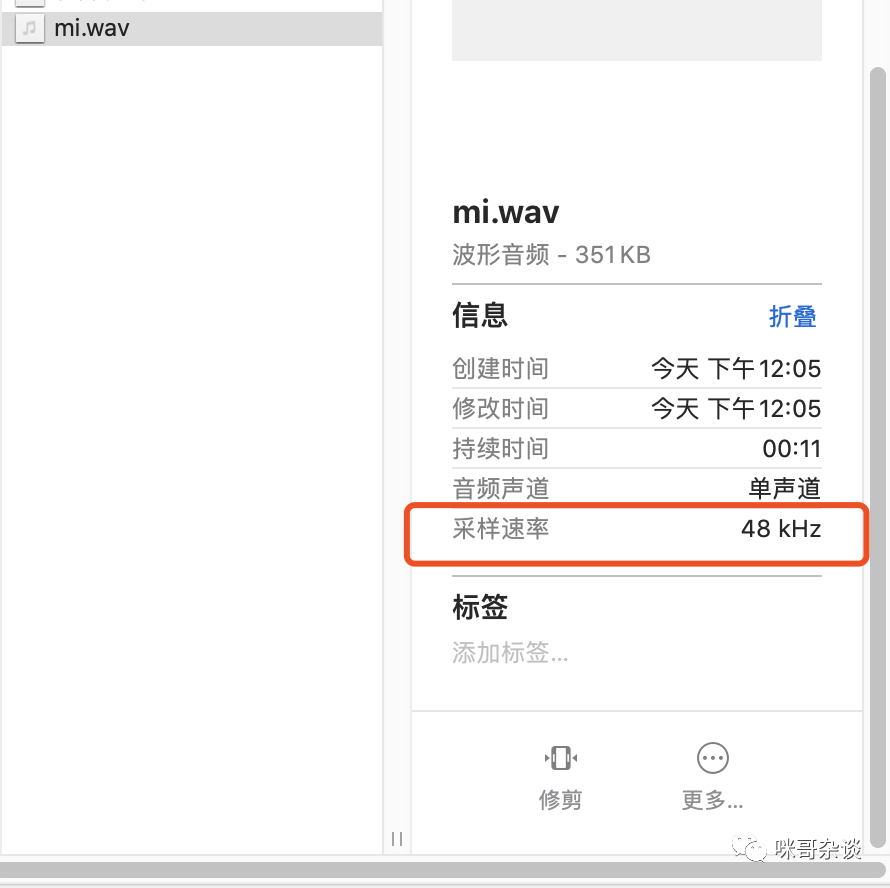

pip install ffmpeg-python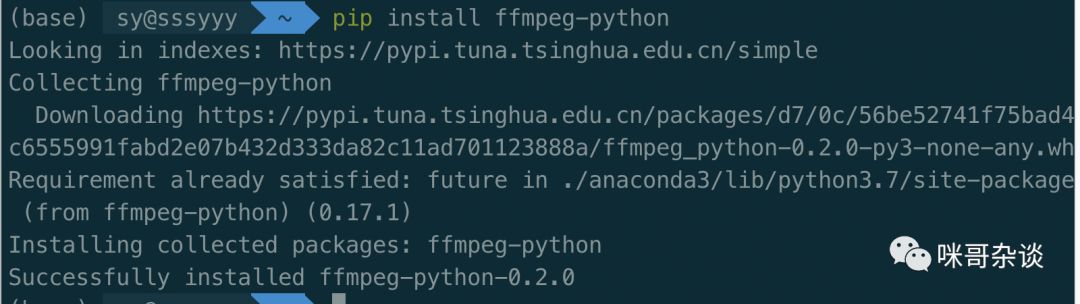
import ffmpegffmpeg.input('mi.wav').output('mi2.wav', ar=16000).run()
brew install ffmpeg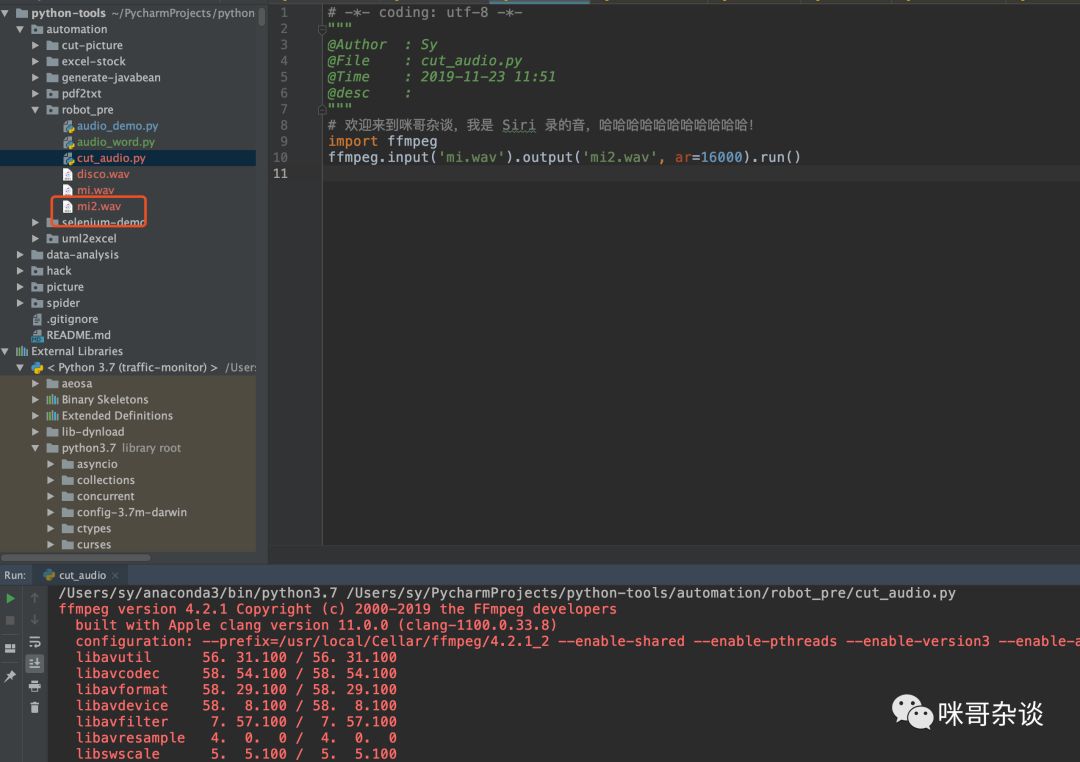

先看百度解析成功,返回的文字结果在 key 为 result 中,其中是个 list,所以直接取出来即可。

4
总结
简单总结下,这篇文章即符合主线机器人,也符合之前后台提问题的那个小伙伴。上述所有过程,都是我在编码过程中亲身遇到的坑。
所以可以借鉴,没遇到相同错误更好,遇到了自己对着百度的官网看看到底是什么错误。
至于本篇文章的编码,涉及的不多,就不上传到 github 了,下一篇要讲下如何用 Python 玩转 Word 操作,所以打算把下篇文章涉及到的代码留个记录,转语音后的文字,落地到 Word 中,敬请期待!
如果学习中遇到什么问题的小伙伴,欢迎评论区下方留言!

作者:weixin_38753698