如何提高语音识别模型的准确率?
“智能客服+人工坐席”的新型客户服务模式,通过自动化的语音识别技术,降低客服中心的人力成本,提升客服中心的运营效率。
应用场景:客服质检、机器人外呼、语音导航
智能客服和领域非常相关,不同领域的话题各不相同,还有大量的领域词汇,所以需要根据不同领域来训练相应的语音识别模型。
客服语音识别的技术挑战:
1、有些客户普通话口音重:不同地域有不同的口音特点
2、自然风格说话:语速快、吐字不清、抢话叠字
3、电话信道、领域术语多:电话信道8Kh采样,音质差。不同行业有自己独特的领域术语
4、有些客户讲方言:中国有七大方言区、数十种方言
语音数据训练测试实验:
一、全领域客服测试
测试数据:涵盖金融、电信、教育、电商、房产等领域的客服语音
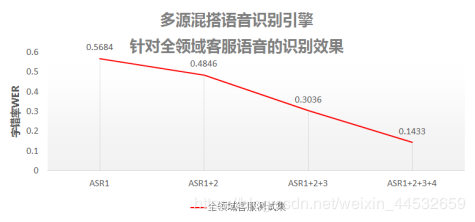
ASR1: “普通话朗读数据”训练所得模型
ASR1+2: ASR1基础上,增加“重口音普通话数据”
ASR1+2+3: ASR1+2基础上,增加“普通话自然对话数据”
ASR1+2+3+4: 在ASR1+2+3基础上,增加“实网客服语音数据”
结论:
只使用数据堂普通话朗读数据训练后,识别模型的字错率是54.8%,在叠加数据堂重口音普通话、普通话自然对话、实网客服语音后,字错率降到了12.5%.
二、金融领域客服测试
测试数据:金融领域的客服语音
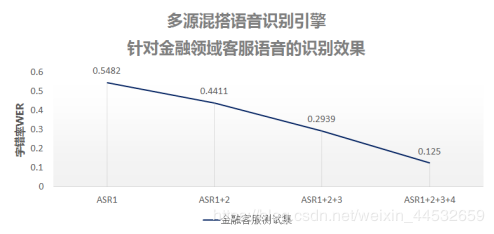
ASR1: “普通话朗读数据”训练所得模型
ASR1+2: ASR1基础上,增加“重口音普通话数据”
ASR1+2+3: ASR1+2基础上,增加“普通话自然对话数据”
ASR1+2+3+4: 在ASR1+2+3基础上,增加“实网客服语音数据”
结论:
只使用数据堂普通话朗读数据训练后,识别模型的字错率是54.8%,在叠加数据堂重口音普通话、普通话自然对话、实网客服语音后,字错率降到了12.5%.
相关实验数据:
一、普通话朗读语音
1505小时普通话手机采集语音数据

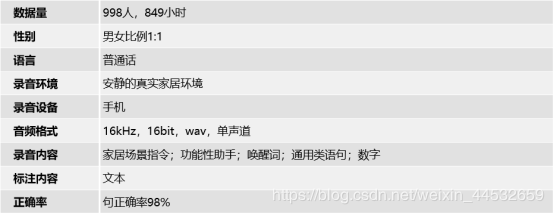
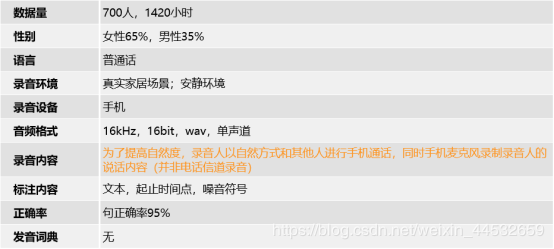
849小时普通话家居交互手机语音数据
二、普通话自然对话语音
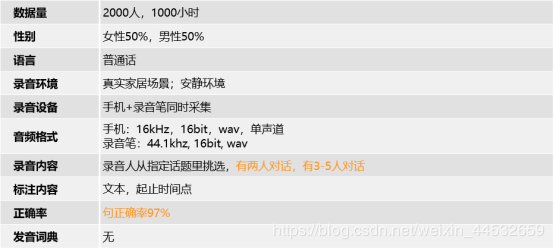
1000小时普通话多人自然对话语音数据
2000小时普通话两人自然对话语音数据
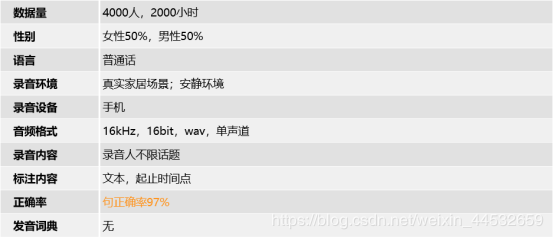
1420小时普通话自然语音手机采集数据
三、重口音普通话语音
1026小时重口音普通话手机采集语音数据
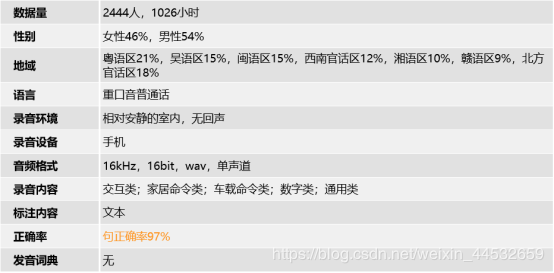
662小时重口音普通话手机采集语音数据

132小时重口音普通话手机采集语音数据

四、实网客服语音
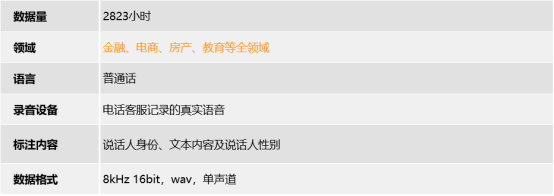
2823小时普通话客服实网语音采集数据
555小时全领域客服实网语音采集数据

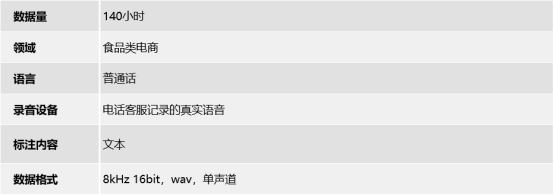
140小时电商客服普通话实网采集语音数据
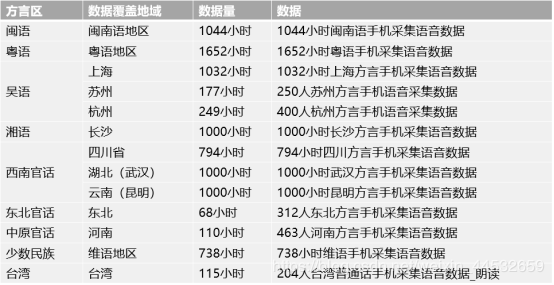
五、方言语音
方言语音-朗读
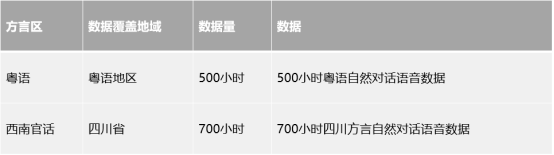
方言语音-自然对话
https://www.datatang.com/dataset/all/1
作者:数据堂官方账号