爬取TIOBE的编程语言排行榜
写在前面: 我是「虐猫人薛定谔i」,一个不满足于现状,有梦想,有追求的00后
\quad
本博客主要记录和分享自己毕生所学的知识,欢迎关注,第一时间获取更新。
\quad
不忘初心,方得始终。自己的梦想,终有一天会实现!
\quad
❤❤❤❤❤❤❤❤❤❤
文章目录思路分析代码结果总结 思路分析最近,本人打算搞一个编程语言排名的可视化,需要数据,于是就从TIOBE上爬了一些数据。下面我来分享一下我的思路,思路仅供参考,可能有更好的方法,如果小伙伴们有好方法,可以在评论区留言哦。

本次爬取的目标:TIOBE
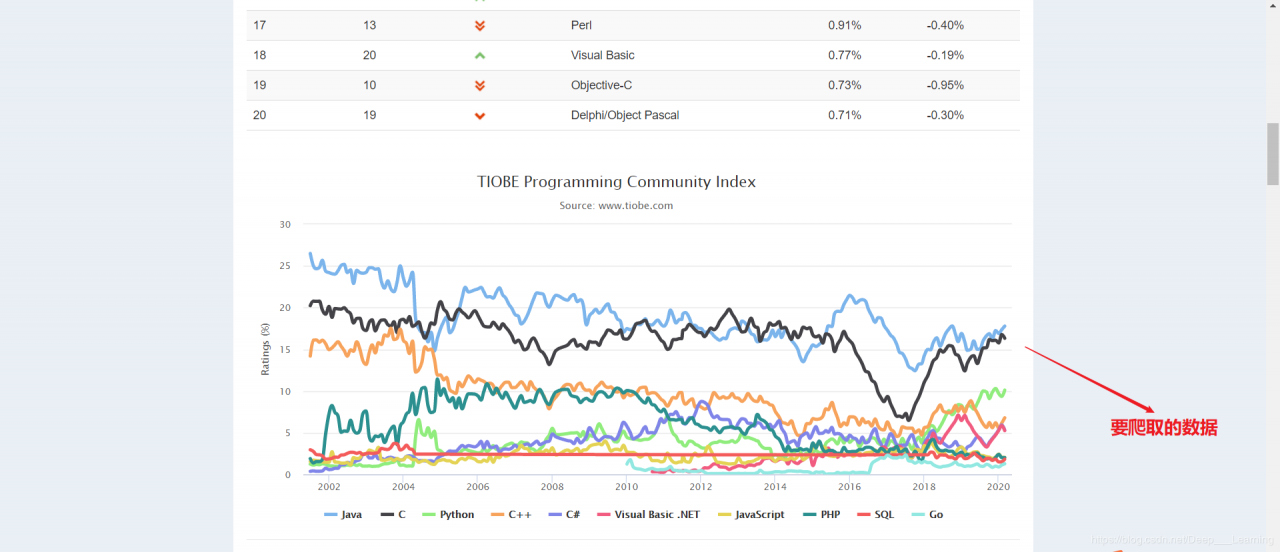
打开网站后,发现其中有一个图表做的挺好看,表上的数据也挺全,包括了从2002年一直到现在,一些主流的编程语言的排名数据。好了,今天就爬它了,淦!
首先,使用F12大法来分析一下网站,通过分析,我们可以发现这些数据就蕴藏在这个页面当中,那就好办了,直接爬这个页面,获取源码后,再提取想要的数据就行了。O(∩_∩)O哈哈~
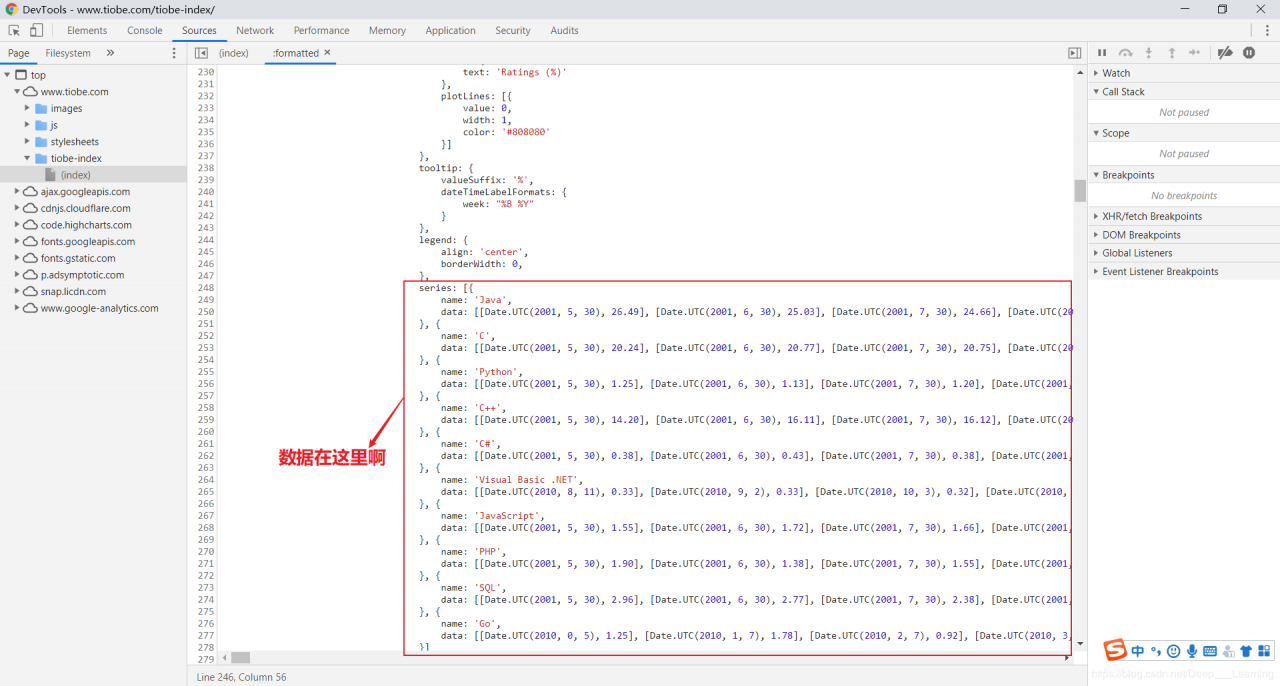
再说一下,我遇到的坑吧!虽然,这次爬数据比较简单,但是在数据清洗上,我又走了不少弯路。ε=(´ο`*)))唉,我一开始想要用json库直接解析,可是爬到的数据不是规范的json格式,json库解析失败,于是,我又把数据规范了一下,可是,还是不行。┭┮﹏┭┮,在这个地方,我卡了好久。最后,我放弃了json解析,直接使用了正则表达式来清洗数据。
import requests
import re
import os
import csv
# 页面的URL
url = 'https://www.tiobe.com/tiobe-index/'
# 伪装请求头
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36'
}
# 打开文件,保存数据
if not os.path.exists('./result/'):
os.makedirs('./result/')
f = open('./result/tiobe.csv', 'w', newline='')
writer = csv.DictWriter(f, ['name', 'type', 'value', 'date'])
writer.writeheader()
# 发送请求,获取数据
response = requests.get(url, headers=headers)
html = response.text
result = ''.join(re.findall(r'series: (.*?)\}\);', html, re.DOTALL))
result = re.findall(r'({.*?})', result, re.DOTALL)
# 数据清洗,将数据整理成想要的格式
for item in result:
name = ''.join(re.findall(r"{name : '(.*?)'", item, re.DOTALL))
data = re.findall(r"\[Date.UTC(.*?)\]", item, re.DOTALL)
for i in data:
i = i.replace(' ', '')
i = re.sub(r'[()]', '', i)
value = i.split(',')[-1]
time_list = i.split(',')[:3]
time = ""
for index, j in enumerate(time_list):
if index !=0:
if len(j) == 1:
j = '0' + j
if index == 0:
time += j
else:
time += '-' + j
temp = {
'name': name,
'type': name,
'value': value,
'date': time
}
print(temp)
writer.writerow(temp)
# 关闭文件
f.close()
结果
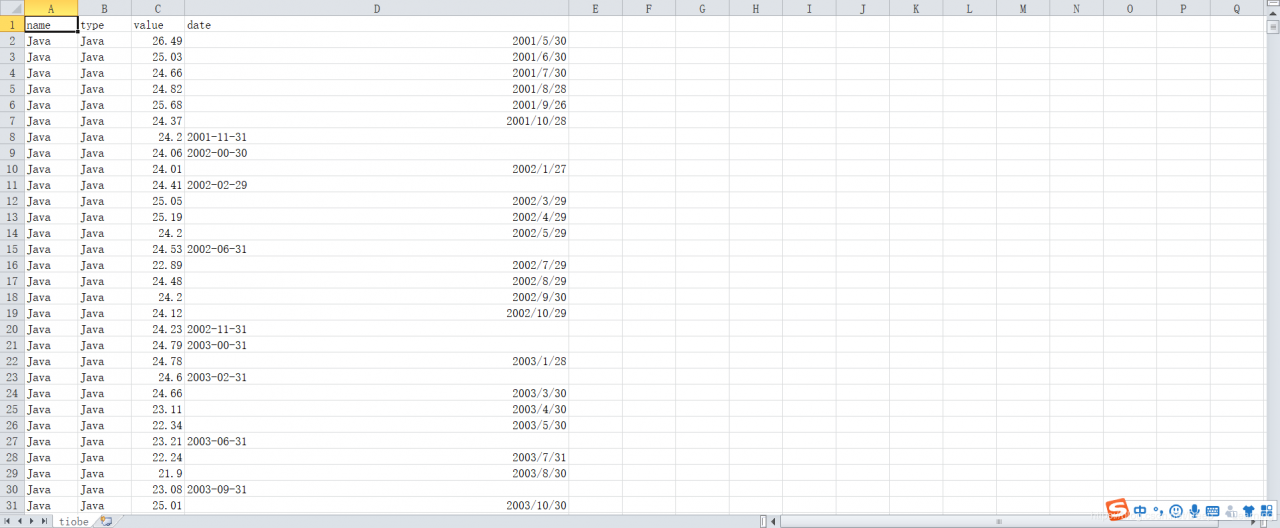

数据之所以要整理成这个样子,是因为那个可视化的模板需要这样的格式。
通过这次数据的爬取,我发现自己在数据的清洗与转换上的操作还不是很熟练,以后要多加强这方面的练习。

作者:虐猫人薛定谔i