pytorch加载自己的数据集源码分享
一、标准的数据集流程梳理
数据来源
二、实现加载自己的数据集
1. 保存在txt文件中(生成训练集和测试集,其实这里的训练集以及测试集也都是用文本文件的形式保存下来的)
2. 在继承dataset类LoadData的三个函数里调用train.txt以及test.txt实现相关功能
三、源码
一、标准的数据集流程梳理分为几个步骤
数据准备以及加载数据库–>数据加载器的调用或者设计–>批量调用进行训练或者其他作用
直接读取了x和y的数据变量,对比后面的就从把对应的路径写进了文本文件中,通过加载器进行读取
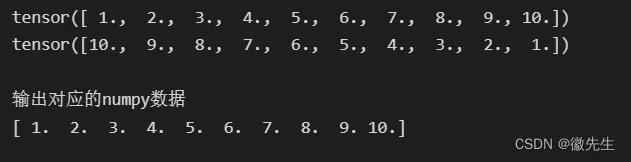
x = torch.linspace(1, 10, 10) # 训练数据 linspace返回一个一维的张量,(最小值,最大值,多少个数)
print(x)
y = torch.linspace(10, 1, 10) # 标签
print(y)
将数据加载进数据库
输出的结果是<torch.utils.data.dataset.TensorDataset object at 0x00000145BD93F1C0>,需要使用加载器进行加载,才能迭代遍历
import torch.utils.data as Data
torch_dataset = Data.TensorDataset(x, y) # 对给定的 tensor 数据,将他们包装成 dataset
#输出的结果是<torch.utils.data.dataset.TensorDataset object at 0x00000145BD93F1C0>,需要使用加载器进行加载,才能迭代遍历
print(torch_dataset)

所以要想看里面的内容,就需要用迭代进行操作或者查看。
BATCH_SIZE=5
loader = Data.DataLoader(#使用支持的默认的数据集加载的方式
# 从数据库中每次抽出batch size个样本
dataset=torch_dataset, # torch TensorDataset format 加载数据集
batch_size=BATCH_SIZE, # mini batch size 5
shuffle=False, # 要不要打乱数据 (打乱比较好)
num_workers=2, # 多线程来读数据
)
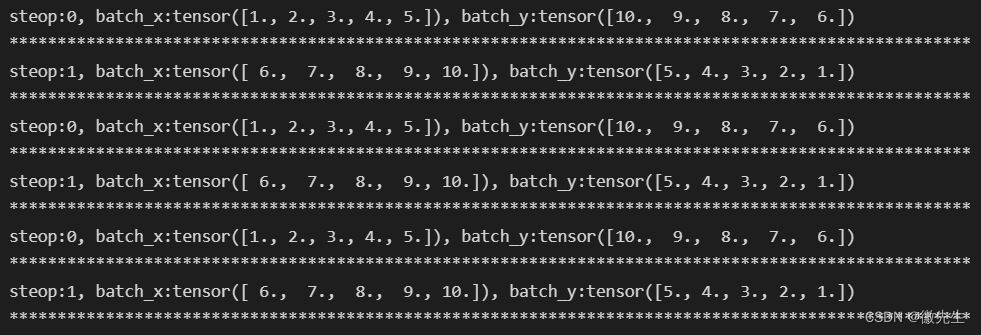
def show_batch():
for epoch in range(3):
for step, (batch_x, batch_y) in enumerate(loader): #加载数据集的时候起的作用很奇怪
# training
print("steop:{}, batch_x:{}, batch_y:{}".format(step, batch_x, batch_y))
print("*"*100)
if __name__ == '__main__':
show_batch()
实现自己的数据集就需要完成对dataset类的重载。这个类的重载完成几个函数的作用
初始化数据集中的数据以及标签__init__()
返回数据和对应标签__getitem__
返回数据集的大小__len__
基本的数据集的方法就是完成以上步骤,但是可以想想数据集通常是一些图片和标签组成,而这些数据集以及标签是保存在计算机上,具有相对应的位置,那么直接访问对应的位置因为是在文件夹下需要进行遍历等一系列操作,而且这就显得和dataset类没有解耦,因为有时候在这些位置的操作可能会有一些特殊操作,所以如果能够将其位置保存在文本文件中可能就会方便很多,所以就采取保存文本文件的方式。
# 自定义数据集类
class MyDataset(torch.utils.data.Dataset):
def __init__(self, *args):
super().__init__()
# 初始化数据集包含的数据和标签
pass
def __getitem__(self, index):
# 根据索引index从文件中读取一个数据
# 对数据预处理
# 返回数据和对应标签
pass
def __len__(self):
# 返回数据集的大小
return len()
1. 保存在txt文件中(生成训练集和测试集,其实这里的训练集以及测试集也都是用文本文件的形式保存下来的)
所以这里新建一个数据库就是新建了两个文本文件,然后加载器通过文本文件就将图片以及label加载进去了。而标准的数据集操作是使用了自带的数据集接口,在加载的时候也不用再去实现相关的__getitem__方法
数组定义
将绝对路径加载进数组中
数组定义
将绝对路径加载进数组中
通过os.walk操作
os.walk可以获得根路径、文件夹以及文件,并会一直进行迭代遍历下去,直至只有文件才会结束
将数组的内容打乱顺序
分别将绝对路径对应的数组内容写进文本文件里,那么这里的文本文件就是保存的数据库,其实数据就是一个保存相关信息或者其内容的文件,而标准也是将将其数据保存在了一个地方,然后对应到标准接口就可以加载了(Data.TensorDataset以及Data.DataLoader)
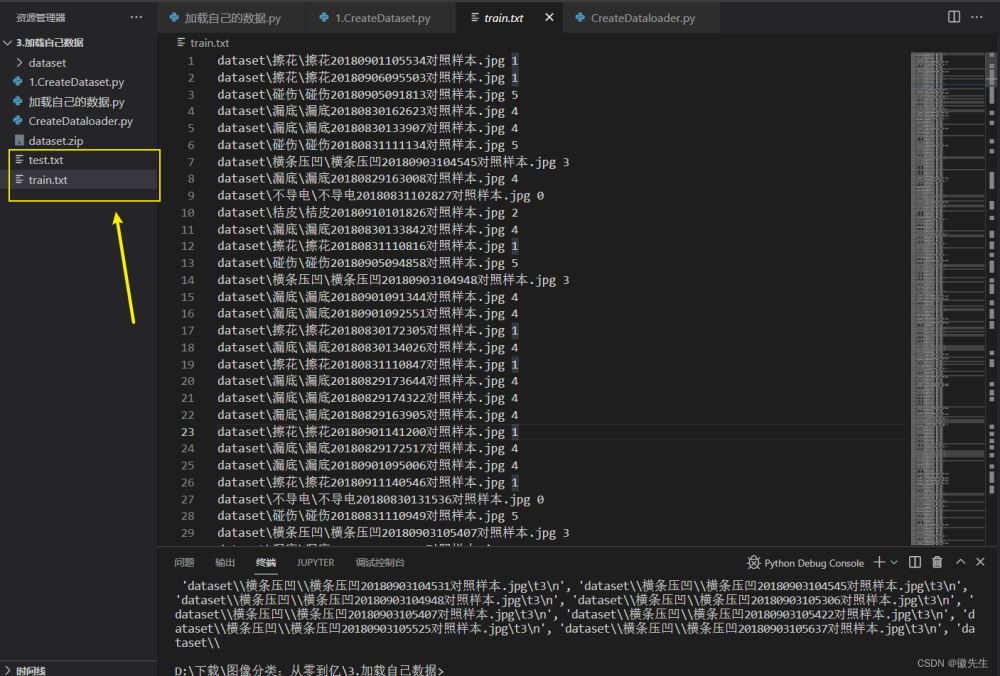
以下代码用于生成对应的train.txt val.txt
'''
生成训练集和测试集,保存在txt文件中
'''
import os
import random
train_ratio = 0.6
test_ratio = 1-train_ratio
rootdata = r"dataset"
#数组定义
train_list, test_list = [],[]
data_list = []
class_flag = -1
# 将绝对路径加载进数组中
for a,b,c in os.walk(rootdata):#os.walk可以获得根路径、文件夹以及文件,并会一直进行迭代遍历下去,直至只有文件才会结束
print(a)
for i in range(len(c)):
data_list.append(os.path.join(a,c[i]))
for i in range(0,int(len(c)*train_ratio)):
train_data = os.path.join(a, c[i])+'\t'+str(class_flag)+'\n' #class_flag表示分类的类别
train_list.append(train_data)
for i in range(int(len(c) * train_ratio),len(c)):
test_data = os.path.join(a, c[i]) + '\t' + str(class_flag)+'\n'
test_list.append(test_data)
class_flag += 1
print(train_list)
# 将数组的内容打乱顺序
random.shuffle(train_list)
random.shuffle(test_list)
#分别将绝对路径对应的数组内容写进文本文件里
with open('train.txt','w',encoding='UTF-8') as f:
for train_img in train_list:
f.write(str(train_img))
with open('test.txt','w',encoding='UTF-8') as f:
for test_img in test_list:
f.write(test_img)
初始化数据集中的数据以及标签、相关变量__init__()
def __init__(self, txt_path, train_flag=True):
#初始化图片对应的变量imgs_info以及一些相关变量
self.imgs_info = self.get_images(txt_path) #imgs_info保存了图片以及标签
self.train_flag = train_flag
self.train_tf = transforms.Compose([#对训练集的图片进行预处理
transforms.Resize(224),
transforms.RandomHorizontalFlip(),
transforms.RandomVerticalFlip(),
transforms.ToTensor(),
transform_BZ
])
self.val_tf = transforms.Compose([#对测试集的图片进行预处理
transforms.Resize(224),
transforms.ToTensor(),
transform_BZ
])
返回数据和对应标签__getitem__
def __getitem__(self, index):
img_path, label = self.imgs_info[index]
#打开图片,并将RGBA转换为RGB,这里是通过PIL库打开图片的
img = Image.open(img_path)
img = img.convert('RGB')
img = self.padding_black(img) #将图片添加上黑边的
if self.train_flag: #选择是训练集还是测试集
img = self.train_tf(img)
else:
img = self.val_tf(img)
label = int(label)
return img, label
返回数据集的大小__len__
def __len__(self):
return len(self.imgs_info)
由于前面已经对集成dataset的类进行了实现三种方法,那么就可以在加载器中进行加载,将加载后的数据传入到train函数或者test函数都可以
train_dataloader = DataLoader(dataset=train_data, num_workers=4, pin_memory=True, batch_size=batch_size, shuffle=True):使用加载器加载数据
train(train_dataloader, model, loss_fn, optimizer) test(test_dataloader, model):将数据传入train或者test中进行训练或者测试
注意:LoadData是继承了dataset的类
if __name__=='__main__':
batch_size = 16
# # 给训练集和测试集分别创建一个数据集加载器
train_data = LoadData("train.txt", True)
valid_data = LoadData("test.txt", False)
train_dataloader = DataLoader(dataset=train_data, num_workers=4, pin_memory=True, batch_size=batch_size, shuffle=True)
test_dataloader = DataLoader(dataset=valid_data, num_workers=4, pin_memory=True, batch_size=batch_size)
for X, y in test_dataloader:
print("Shape of X [N, C, H, W]: ", X.shape)
print("Shape of y: ", y.shape, y.dtype)
break
三、源码
链接: https://pan.baidu.com/s/19Oo87gbcm9e8zvYGkBi95A 提取码: 2tss
到此这篇关于pytorch加载自己的数据集源码分享的文章就介绍到这了,更多相关pytorch加载自己的数据集内容请搜索软件开发网以前的文章或继续浏览下面的相关文章希望大家以后多多支持软件开发网!