MySQL 原理优化之Group By的优化技巧
今天来看看MySQL 中如何多Group By 语句进行优化的。
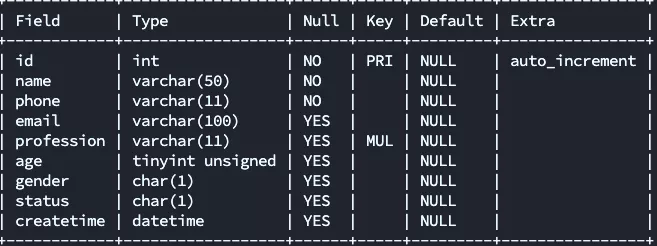
先创建tb_user 表如下:
通过show index from tb_user; 命令查看表,没有存在任何的索引。

执行如下代码,查看SQL 执行情况
explain select profession, count(*) from tb_user group by profession ;

发现返回结果中 type 为“ALL” ,Extra 返回“Using temporary” 说明没有使用索引。
于是,创建基于profession,age和status 的索引如下:
create index index_user_pro_age_sta on tb_user(profession ,age, status);
这里创建索引从左到右的顺序是 profession ,age, status。
此时再次执行SQL执行计划如下:
explain select profession, count(*) from tb_user group by profession ;

发现使用了索引“index_user_pro_age_sta”。说明在执行 group by操作的时候,使用联合索引是有效的。
接着在看使用如下代码:
explain select age, count(*) from tb_user group by age;
SQL 语句使用age 进行group by,查看explain的结果如下:

在Extra 字段中发现使用了“Using temporary”,说明没有走索引,是因为没有满足索引的最左前缀法则。
联合索引 index_user_pro_age_sta的顺序从左到右分别是 profession ,age, status。
上面的SQL 语句Group by 后面接着的是age ,因此出现“Using temporary”。
这里对SQL 进行修改。如下:
explain select profession,age, count(*) from tb_user group by profession, age;

由于group by 后面跟着profession, age ,符合联合索引的创建顺序,因此索引生效。
我们再来试试再加入过滤条件的情况,加入profession = 软件工程,此时group by 里面只显示 age,那么此时是否会走索引, 答案是 using index。因为满足了最左前缀法则。
explain select age, count(*) from tb_user where profession = '软件工程' group by age;

总结一下:
SQL在分组操作的时候,可以通过索引来提高效率。做分组操作的时候,索引的使用需要满足最左前缀法则。
到此这篇关于MySQL 原理优化之Group By的优化技巧的文章就介绍到这了,更多相关MySQLGroup By优化内容请搜索软件开发网以前的文章或继续浏览下面的相关文章希望大家以后多多支持软件开发网!