用python爬取豆瓣电影Top250信息
这是一个用python爬取豆瓣电影Top250信息
文章目录这是一个用python爬取豆瓣电影Top250信息1.导入库2.写程序的主函数(爬虫框架)3.获取网页信息4.解析网页数据5.保存数据6.写入程序入口7.总结
1.导入库
作者:极简机器学习
# -*- coding:UTF-8 -*-
import re
import urllib.request
import urllib.error
import xlwt
from bs4 import BeautifulSoup
2.写程序的主函数(爬虫框架)
简单流程可见上节写的内容。
def main():
baseurl = 'https://movie.douban.com/top250?start='
# 1.爬取网页
# 2.获取自己想要的内容
datalist = getData(baseurl)
savepath = './豆瓣Top250.xls'
saveData2(datalist, savepath) # 3.保存数据
需要指出的是,baseurl中需要写下start,因为豆瓣每页显示的是25部电影信息,需要循环遍历
需要写一个函数,提取网页html内容。
def askURL(url):
head = { # 模拟的头部
"User-Agent": " Mozilla/5.0(Windows NT 10.0;WOW64) AppleWebKit/537.36(KHTML, likeGecko) Chrome/78.0.3904.108Safari/537.36"
# 用户代理,告诉服务器我们是什么类型的浏览器
}
request = urllib.request.Request(url, headers=head)
html = ''
try:
response = urllib.request.urlopen(request) # response便是网页信息
html = response.read().decode('utf-8')
# print(html)
except urllib.error.URLError as e: #这一步是写错误处理
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
return html
askURL返回的便是网页信息。是一个很长的字符串
In[2]:html
Out[2]: '\n<html lang="zh-CN"...
In[5]:type(html)
Out[5]: str
4.解析网页数据
这一步是用bs4来解析上面返回的html,这是因为bs4返回得到的树状数据,可以用正则表达式来提取我们想到的内容。
def getData(baseurl):
datalist = []
for i in range(0, 10):
url = baseurl + str(i * 25) # 获取所有的网页
html = askURL(url)
接着上面写解析的代码:
# 2.逐一解析数据
soup = BeautifulSoup(html, "html.parser")
# 查找符合要求的字符串,形成列表
for item in soup.find_all('div', class_="item"): # div 同时是class属性,加下划线
# print(item) #查看电影item
data = []
item = str(item)
#下面开始用正则表达式来寻找电影的中文名字、评分、评论数、年份
name= re.findall(findname, item)[0] # 可能只有一个名字
data.append(name) #中文名字
score = re.findall(findSore, item)[0]
data.append(score) #评分
judge = re.findall(findJudge, item)[0]
data.append(judge) #评论数
year= re.findall(findtime, item)[0].strip()
year= "".join(year.split()) #这个写法是为了去掉字符串中间的空格
# print(t1)
year= re.findall(findnum, year)[0]
data.append(year) #年份
datalist.append(data)
# print(datalist)
return datalist
这一步如何写正则表达式是关键,下面写了8个豆瓣电影的信息,写法多样,可以自由发挥,写对的就可以了。这块代码可以放在最前面,用全局变量。
findlink = re.compile(r'') # 创建正则表达对象,表示规则
findname = re.compile(r'(.*)') # 创建正则表达对象,表示规则
findImg = re.compile(r'<img.*src="(.*?)"', re.S) # 让换行符在在字符串中
findSore = re.compile(r'')
findJudge = re.compile(r'(\d*)人评价')
findBd = re.compile(r'(.*?)
', re.S)
findtime = re.compile(r'(.*?)
', re.S)
findnum = re.compile(r'
(\d*.*/.*)/.*')
5.保存数据
这一步用excel保存数据
# 3.保存数据
def saveData(datalist, savepath):
workbook = xlwt.Workbook(encoding='utf-8', style_compression=0)
worksheet = workbook.add_sheet('豆瓣电影Top250', cell_overwrite_ok=True) # 可覆盖
col = ('影片中文名', '评分', '评价数', '时间/地区')
for i in range(0, 4):
worksheet.write(0, i, col[i]) # 列名
for i in range(0, 250):
print("第%d条" % (i + 1))
data = datalist[i]
for j in range(0, 4):
worksheet.write(i + 1, j, data[j]) # 数据
workbook.save(savepath)
6.写入程序入口
if __name__ == '__main__': # 程序执行的时候,运行下面的程序(程序的入口)
main()
print("done!")
7.总结
到这一步爬虫便结束了,爬虫流程很简单,如下:

最后看下我们爬虫后的信息:
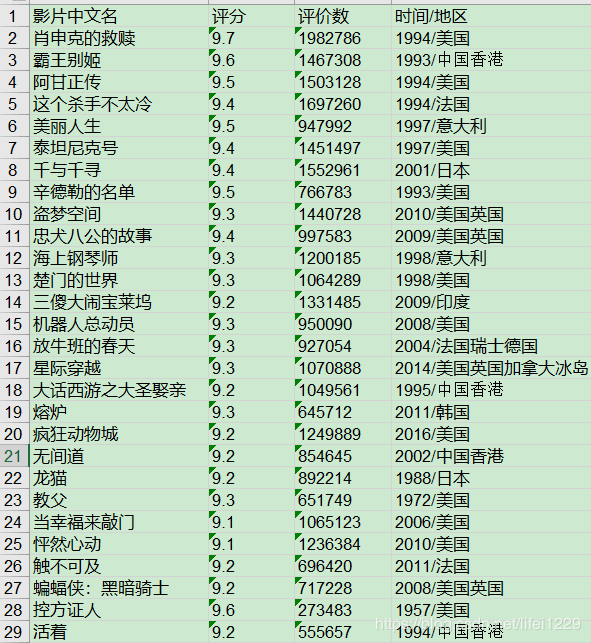
作者:极简机器学习