利用python的mlxtend实现简单的集成分类器
实验环境
作者:葛伟平
python 3.7.1+Anaconda 1.9.7+pycharm 2019.1
主要pkgpandas、numpy、sklearn、mlxtend
数据格式Label:
features:
首先利用pandas的read_系列函数读入数据,我用的是read_excel,(很奇怪,不知道为什么用read_csv就会一直读入失败,,)
然后,
千万要注意,要处理好数据中的字符串!否则后面fit是要报错的!!!,比如:
read_excel函数会默认将第一行剔除掉,如果不想剔除的话加一句header=None就可以了;
字符串列也要删除或映射;
续上,label中的字符串都要映射成对应的数值,可以采用简单的序号自增;
❤关于映射,有些包的分类器会将非数值类型自动映射的,但有的就不能,比如这里使用的stackingclassifier
#数据读入
df= pd.read_excel("单细胞测序数据Labels.csv",header=None)#read_csv就是不好用啊
label=df.values.tolist()
tmp = [] #去掉小列表
for i in label:
tmp.append(i[0])#此处是为了将[[a],[b]]这种嵌套列表变成[a,b]
label = tmp
df= pd.read_excel("单细胞测序数据.csv")
feature=df.values.tolist()
for i in feature:#这里是要删除非数字的列,对应数据中的第一列
del i[0]
#label映射
tmp = []
tmp.append(0)
for i in range(1,len(label)):
if label[i] != label[i-1]:
tmp.append(tmp[i-1]+1)
else:
tmp.append(tmp[i-1])
label = tmp
其实主要的部分都在数据处理部分(hhh菜鸡),剩下的就是调用相应模块的函数了。
对于关于stacking的思想多说几句,白话来讲就是用k(这里k=3)个分类器作为初级分类器,分别训练之后将其预测值作为新的训练集加入原有集合,再利用一个meta-classifier进行分类,得到最终预测值。
这里的算法我理解的可能有所偏差,请各位多多指教,互相讨论。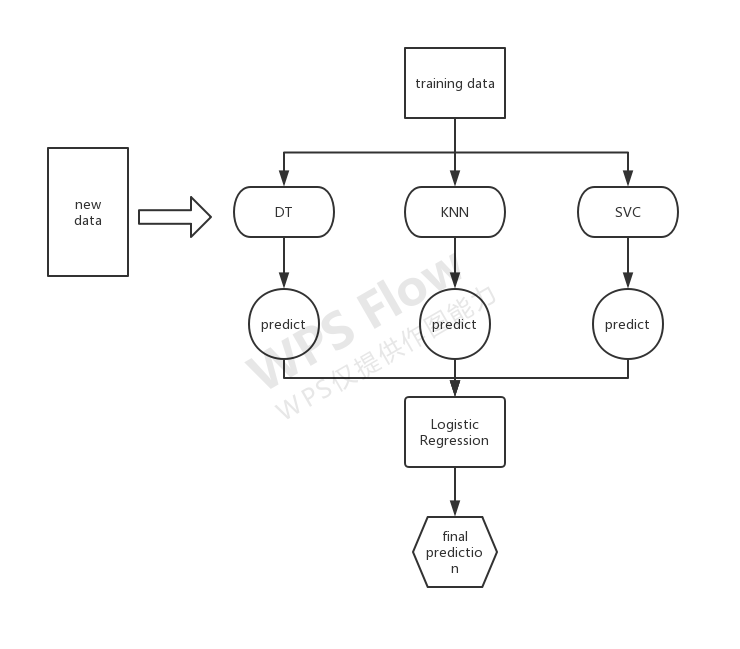
(换了各种分类器的组合,准确率才勉强能看。。。)

import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from mlxtend.classifier import StackingClassifier
from sklearn.preprocessing import StandardScaler
#数据读入
df= pd.read_excel("单细胞测序数据Labels.csv",header=None)#read_csv就是不好用啊
label=df.values.tolist()
tmp = [] #去掉小列表
for i in label:
tmp.append(i[0])#此处是为了将[[a],[b]]这种嵌套列表变成[a,b]
label = tmp
df= pd.read_excel("单细胞测序数据.csv")
feature=df.values.tolist()
for i in feature:#这里是要删除非数字的列,对应数据中的第一列
del i[0]
#label映射
tmp = []
tmp.append(0)
for i in range(1,len(label)):
if label[i] != label[i-1]:
tmp.append(tmp[i-1]+1)
else:
tmp.append(tmp[i-1])
label = tmp
#数据集划分
X_train_scaled,X_test_scaled,y_train,y_test=train_test_split(feature,label,test_size=0.3,stratify=label)
ss = StandardScaler()
X_train_scaled= ss.fit_transform(X_train_scaled)
X_test_scaled = ss.fit_transform(X_test_scaled)
#clf1,clf2,clf3对应上图的classification models ,即分类器
clf1 = KNeighborsClassifier()
clf2 = LogisticRegression()
clf3 = SVC()
# lr对应上图的Meta-classifier
lr = RandomForestClassifier()
#进行stacking
sclf = StackingClassifier(classifiers=[clf1, clf2, clf3],
meta_classifier=lr)
#用三个模型分别进行训练,以作比较
clf1.fit(X_train_scaled, y_train)
clf2.fit(X_train_scaled, y_train)
clf3.fit(X_train_scaled, y_train)
#用stacking进行训练
sclf.fit(X_train_scaled, y_train)
print('kNN测试集准确率:{:.3f}'.format(clf1.score(X_test_scaled, y_test)))
print('逻辑回归测试集准确率:{:.3f}'.format(clf2.score(X_test_scaled, y_test)))
print('SVM测试集准确率:{:.3f}'.format(clf3.score(X_test_scaled, y_test)))
print('Stacking测试集准确率:{:.3f}'.format(sclf.score(X_test_scaled, y_test)))
后记
第一次尝试关于分类器的小项目,发现菜鸡世界的机器学习就是调包啊。。。唯一有挑战性的就是数据预处理了hhh。。。有什么见解和纰漏之处请各位多多指教,多多指正,互相提高~艾宁!
作者:葛伟平